




HDFS分布式文件系统
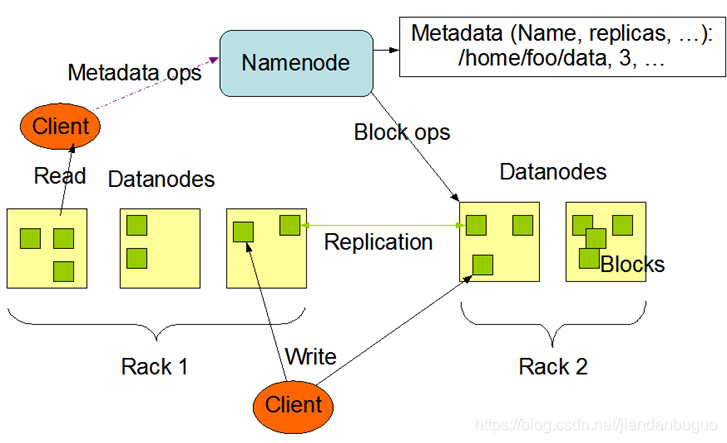
HDFS采用master/slave架构
master:NameNode
slave:DataNode
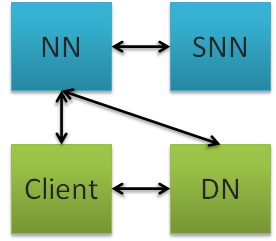
HDFS组成及功能
- client:客户端,负责存储、读取
- namenode:元数据节点,管理文件系统的namespace元数据,一个集群只能有一个Active namenode
- datanode:数据节点,数据存储节点,保存、检索Block,一个集群可以有多个数据节点
- secondary namenode:从元数据节点,合并namenode的edit
logs到fsimage文件中,辅助namenode将内存中元数据信息持久化
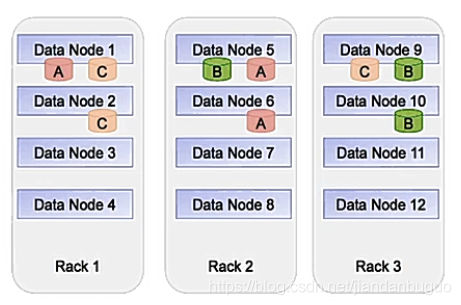
HDFS副本机制
在hdfs中数据以数据块(block)的形式存储的,数据块是hdfs中最基本的存储单位,在hadoop2.x版本中,数据块的默认大小为128M。
通常默认的副本数为3个,可在配置文件中修改
副本的存放机制为:一个本地机架节点、一个在同一个机架不同节点、一个在不同机架的节点
block:数据块,是hdfs最基本的存储单元,2.x版本默认大小为128M
副本机制的作用:避免数据丢失,副本数默认是3
如下图所示,每一个Rack都是一个机架,上面有若干个datanode节点,A、B、C都是一个block块,以A 为例,存储时现在Rack1的节点上存放,然后会在一个不同的节点上备份(Rack2的DataNode5)和同一机架的不同节点备份(Rack2的DataNode6)
HDFS优点
- 高容错性:副本机制
- 适合大数据处理
- 流式数据访问
- 可构建在廉价的机器上
HDFS缺点
- 不适合低延时数据访问场景:hdfs是海量数据存储,因此耗时比较大
- 不适合小文件存取场景:无论是大文件还是小文件在namenode中的存储大小是相同的,因此小文件过多会造成namenode溢出
- 不适合并发写入,文件随机修改场景
HDFS写文件
如下图所示:
客户端client上传文件前,会将文件分块(默认128M),假设文件大小为300M,则会分成3块:0 ~ 128M、128~256M、256 ~300M
①首先client会想namenode发出请求上传第一个数据块
②namenode会查验目标路径,若不存在,则抛出异常;若存在则会返回一个空闲节点的列表(3个),假设为DN1、DN2、DN3
③NameNode将节点列表返回给客户端
④客户端会与DN建立Pipline连接
⑤上传一个数据块,会将数据块写书DN的内存中,在一边写入DN1内存的同时,会一边传给DN2
⑥响应写入成功
⑦其他块上传重复以上操作

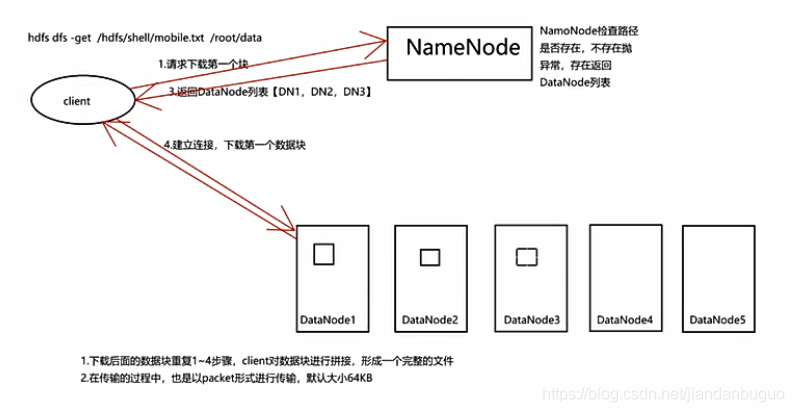
HDFS读文件
①首先客户端向NameNode请求下载第一个块
②NameNode检查路径,若不存在则抛出异常,处在则返回存储数据的节点列表
③NameNode将列表返回给client
④建立Pipline连接
⑤下载第一个数据块
⑥下载其他数据块重复以上步骤
⑦数据块下载完成,client会将数据库块整合成一个文件

















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









