



 本文介绍了Java虚拟机的类加载过程,包括加载、验证、准备、解析和初始化等阶段,详细阐述了类加载器的工作原理及双亲委派模型,并探讨了类执行的基本流程。
本文介绍了Java虚拟机的类加载过程,包括加载、验证、准备、解析和初始化等阶段,详细阐述了类加载器的工作原理及双亲委派模型,并探讨了类执行的基本流程。
虚拟机的类加载和执行机制是虚拟机的最主要功能,在这里简单的对所知的内容进行一次温习,并记录以方便日后重温。
本篇主要引用《深入理解Java虚拟机——JVM高级特性与最佳实践》一书。
1、类文件结构
java虚拟机要对类文件进行加载和执行,那么必须要能够理解类文件结构,而对于虚拟机而言,平台无关性和语言无关性是其最重要的两大特征,那么就势必要对类文件结构进行规范化和结构化,这样才能保证无论是什么语言编译成的字节码文件,java虚拟机都能够正常加载和执行。因此,对于字节码文件(即.class文件)的简单理解是进一步理解虚拟机运行机制的基本步骤。
Class类文件,亦称字节码文件,是由虚拟机规范规定了其结构形式的文件。Class文件是一组以8位为基础单位的二进制流,各个数据项目严格按照顺序紧凑排列在Class文件中,中间没有任何分隔符,以保证整个Class文件中存储的内容全部是程序运行的必要数据,没有空隙。当遇到需要占用8位字节以上空间的数据时,则会按照高位在前的方式分割成若干上8位字节进行存储。
根据虚拟机规范的规定,Class文件格式中只有两种数据类型:无符号数和表。无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节,2个字节,4个字节和8个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值、或者按照UTF-8编码构成字符串值。表是多个无符号数或其它表作为数据项构成的复合数据类型,所有表都习惯性地以"_info"结尾。无论是无符号数还是表,当需要描述同一类型但数量不定的多个数据时,经常会使用一个前置的容量计数器加若干个连续的数据项的形式,这时候称这一系列连续的某一类型的数据为某一类型的集合。
说完了虚拟机规范对Class文件的基本约定后,我们来关注一下Class文件都有些啥。
既然虚拟机是语言无关,那我们可以以java语言作为范本进行学习。回顾一下,我们在定义一个类的时候,都需要或者说可以定义些什么内容。首先,类的修饰符,是abstract,或public、protected、private,然后是类名,再接着,是否有继承或是实现父类或接口,这些是类的基本约束。再接着来看类的内容,我们可以定义类成员变量(static)和实例成员变量,接着是定义类的行为——类方法,类方法又有方法名,返回值,参数值,还有异常列表等。
由上面这些定义的内容,我们可以猜到,当这个定义的类被编译成Class文件时,Class文件中应该要包含些什么内容了。我们再从虚拟机的角度来完整地了解Class文件的结构。
首先,最简单的一个问题,虚拟机必须判定输入的文件是不是一个Class文件,java虚拟机通过识别输入文件的首4个字节的魔数(0xCAFEBABE)来确定其是否Class文件。接着虚拟机由于一直在不断地改进和更新,所以不断有新的版本出现,新的版本能兼容旧的版本,但旧的版本可能就完全无法读取新的虚拟机编译而成的Class文件了,因此,虚拟机就必须对Class文件进行版本的识别和检查,也就是说,Class文件必须要有版本号的数据(Class文件的第5到第8个字节)。
紧接着是Class文件的常量池入口,常量池是Class文件结构中与其它项目关联最多的数据类型,也是占用Class文件空间最大的数据项目之一,同时也是在Class文件中第一个出现的表类型数据项目。由于常量池中常量的数量不固定,因此在常量池的入口之前有一个u2类型的容量计数值。常量池之中主要存放两大常量:字面量(Literal)和符号引用(Symbolic Reference)。字面量即是java语言层面中的常量,如文本字符串(如"adb"等字面量),被声明成final的常量值。符号引用则属于编译原理方面的概念,包括三类常量:类和接口的全限定名,字段的名称和描述符,方法的名称和描述符。这些符号引用在虚拟机中如果不经过转换则无法与实际内存相连接,即无法被虚拟机直接使用,在虚拟机运行时,需要从常量池获得对应的符号引用,再在类创建时或运行时解析并翻译到具体的内存地址中。每项常量都是一个表,而由于各个常量的类型不一,大小也不相同,所以同样需要一个u1类型的数据来标记常量的类型,以确定其后的常量表的格式。
在常量池之后,紧接着的2个字节代表访问标志,即在前面说到的,这个Class是类还是接口,是用哪个修饰符来修饰,abstract,public等,还有,如果是类的话,是否被声明为final,等等。
访问标志之后,则是类索引、父索引与接口索引的集合。类索引和父类索引都是一个u2类型的数据,而接口索引集合是一组u2类型的数据的集合,Class文件中由这三项数据来确定这个类的继承关系。类索引用来确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,接口索引集合用来描述这个类实现了哪些接口,这些被实现的接口将按实现或继承的顺序从左到右的顺序排列在接口的索引集合中。类索引、父类索引和接口索引都按顺序排列在访问标志之后。
接下来就是字段表了,此处字段表存的就是前文说的类成员变量或实例成员变量,但不包括方法内部声明的变量。如果类存在父类,则除非子类覆盖了父类的字段定义,否则在子类中不会列出从超类或父接口中继承而来的字段,但有可能列出原来java代码中不存在的字段,譬如在内部类为了保持对外部类的访问性,会自动添加指向外部类实例的字段。另外,java中是不允许出现相同的字段名的,但对于字节码来说,如果两个字段的描述符不一致,则字段重名是合法的。
字段表之后就是方法表集全了。方法表集合与字段表集合的结构形式几乎完全一致。此处,方法中的代码的存放位置则是方法表的属性表中的一项名为"Code"的属性里面。与字段表集合相对应的,如果父类方法在子类中没有被重写(Override),则方法表集合中就不会出现来自父类的方法信息。
最后来对上面说到的属性表作个解释。属性表是Class文件格式中最具扩展性的一种数据项目,在Class文件,字段表,方法表中都可以携带自己的属性表集合,以用于描述某些场景专有的信息(如方法表中专有的代码信息),具体的属性表的各个属性项目若有兴趣可以翻看《深入理解java虚拟机》这本书,也可以直接翻看虚拟机规范。
2、类加载机制
了解了类的文件结构,接着我们来了解虚拟机如何加载这些Class文件。
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验,转换解析和初始化,最终形成可以被直接使用的java类型,这就是虚拟机的类加载机制。
类的生命周期包括加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)、卸载(Unloading)等七个阶段,其中验证、准备和解析三个部分统称为连接(Linking)。而类的加载指的就是从加载到初始化这五个阶段。
这七个阶段的顺序除了解析阶段和使用阶段外,其它几个阶段的开始顺序是确定的,必须按这种顺序按部就班的开始,但不要求按这种顺序按部就班的完成,这些阶段通常是互相交叉地混合式进行的,通常会在一个阶段执行的过程中调用或激活另外一个阶段。解析阶段在某些情况下可以在初始化阶段之后再开始,以支持java的运行时绑定(RTTI),而使用阶段则是按类文件内容的定义的不同而在不同的阶段进行。
虚拟机规范对于何时进行加载这一阶段并没有强制约束,但对于初始化阶段,虚拟机规范是严格规定了有且只有四种情况必须立即对类进行初始化:
a、遇到new,getstatic,putstatic或invokestatic这4条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。生成这4条指定的场景是:使用new关键字实例化对象,读取或设置一个类的静态字段以及调用一个类的静态方法的时候。当然,被final修饰并在编译期就把结果放入常量池的静态字段不属于这些场景,这类静态字段的值在编译期时就会被编译器优化而直接放入常量池,其引用直接指向其在常量池的入口。
b、使用java.lang.reflect包的方法对类进行反射调用时,如果类没有进行过初始化,则需要先触发其初始化。
c、当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
d、当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的类),虚拟机会先初始化这个主类。
以上四种场景中的行为称为对一个类进行主动引用,除此之外所有引用类的方式都不会触发初始化,称为被动引用。
接口的加载过程与类加载过程最主要的区别在于第三点,即当初始化一个接口时,并不需要先初始化其父接口,而是只有真正使用到父接口中的字段的时候才会初始化。
以下对类加载的各个阶段进行简单的说明。
加载阶段,虚拟机需要完成三件事:通过一个类的全限定名来获取定义此类的二进制字节流,将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构,在java堆中生成一个代表这个类的java.lang.Class对象,作为方法区这些数据的访问入口。
验证阶段,不同虚拟机会进行不同类验证的实现,但大致都会完成以下四个阶段的检验过程:文件格式验证(验证字节流是否符合Class文件格式的规范,并能被当前版本的虚拟机处理),元数据验证(对字节码描述信息进行语义分析,保证其描述信息符合java语言规范),字节码验证(对类方法体进行数据流和控制流分析,保证类的方法在运行时不会做出危害虚拟机的行为)和符号引用验证(发生在将符号引用转化为直接引用的时候,在解析阶段中发生)。
准备阶段,正式为类成员变量(注意,不是实例成员变量,实例变量会在对象实例化时随着对象一起分配在java堆上)分配内存并设置类变量初始值(通常情况下是数据类型的零值,不进行赋值操作)的阶段,这些内存都将在方法区中进行分配。
例:public static int value=123;则在准备阶段过后,value的初始值为0而不是123,赋值指令是在初始化阶段通过构造方法来执行的。
解析阶段,虚拟机将常量池内的符号引用替换为直接引用的过程。符号引用与内存布局无关,而直接引用的目标必定已经在内存中存在。解析动作主要针对类或接口、字段、类方法、接口方法四类符号引用进行。
初始化阶段,真正开始执行类中定义的java程序代码(字节码),是执行类构造器<clinit>()方法的过程。
<clinit>()方法的一些特点:
<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块(static{})中的语句合并产生的,编译器收集顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量。
<clinit>()方法与类的构造函数(或者说实例构造器<init>()方法)不同,它不需要显式地调用父类构造器,虚拟机会在子类的<clinit>()方法执行之前完成父类<clinit>()方法的执行。
由于父类的<clinit>() 方法先执行,也就意味着父类中定义的静态语句块要优先于子类的变量赋值操作
<clinit>()方法对于类或接口来说并不是必须的,如果一个类中没有静态语句块,也没有对变量的赋值操作,则编译器可以不为这个类生成<clinit>()方法。
接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成<clinit>()方法,不同于类的地方是执行接口的<clinit>()方法时不坱要先执行父类的<clinit>()方法。
虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确地加锁和同步,如果多个线程同时去初始化一个类,则只有一个线程去执行这个类的<clinit>()方法,其它线程阻塞等待,直到活动线程执行<clinit>()方法完毕。
了解完各个类加载机制的阶段后,我们需要进一步了解类加载器这个概念。类加载器只用于实现类的加载动作,即实现通过一个类的全限定名来获取描述此类的二进制字节流。但对于类来说,要判断两个类是否相等(instanceof,equal),其前提是两个类是由同一个类加载器所加载,否则,无论两个类是否来源于同一个Class文件,这两个类都必定不等,亦即是说,对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在java虚拟机的唯一性。
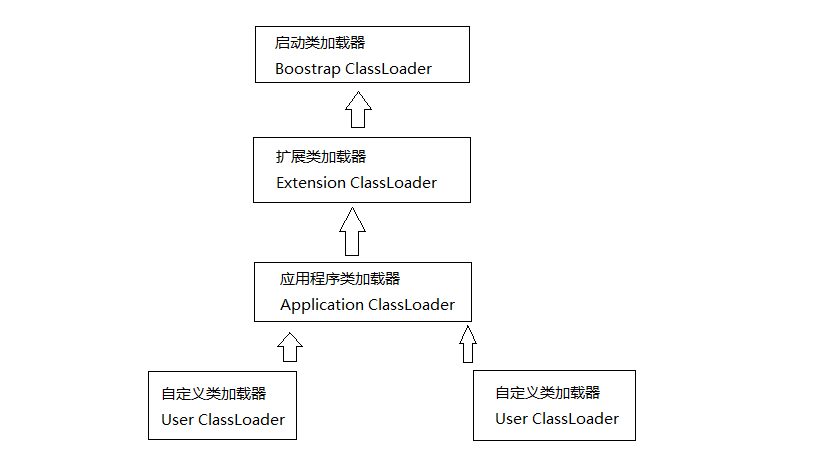
在Java开发人员看来,类加载器可划分为以下三类系统提供的类加载器:启动类加载器(Boostrap ClassLoader,负责将存放在<JAVA_HOME>\lib目录中的类库加载到虚拟机内存中,其无法被Java程序直接引用),扩展类加载器(Extension ClassLoader,由sun.misc.Launcher$ExtClassLoader实现,负责加载<JAVA_HOME>\lib\ext目录中的类库,可被开发者直接使用),应用程序类加载器(由sun.misc.Launcher$AppClassLoader来实现,负责加载用户类路径(ClassPath)上指定的类库,可被开发者直接使用,且为默认的类加载器)。
java中采用双亲委派模型(Parents Delegation Model)来实现类的加载模式。双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器,此处的父子关系不以继承来实现,而是采用组合来利用父加载器。
双亲委派模型的工作过程:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会自己去加载。其模型如下图所示:
3、虚拟机字节码执行引擎
了解了以上类文件结构和类加载机制后,我们最后再来看看字节码在虚拟机中是如何被执行的。
不同的虚拟机实现时硕,执行引擎在执行Java执行的时候可能有解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)两种选择,也可能两者兼备,甚至可能包含几个不同级别的编译器执行引擎。
在具体了解虚拟机是如何执行字节码之前,我们先来从概念上理解虚拟机是如何执行程序的。程序的执行可以直接解释为是对方法的递归调用,通过一连串的方法链来最终得出执行结果,亦即是说虚拟机对程序的执行,根本上是对方法的调用和执行。
栈帧(Stack Frame)是用于支持虚拟机进行方法调用和方法执行的数据结构,是虚拟机运行时数据区中的虚拟机栈的栈元素。栈帧存储了方法的局部变量表(最小单位为变量槽Variable Slot)、操作数栈、动态连接和方法返回地址等信息,每一个方法从调用开始到执行完成的过程,就对应着一个栈帧在虚拟机栈里面从入栈到出栈的过程。栈帧的内容在编译时就已经完成确定,不受程序运行期变量数据的影响,仅取决于具体的虚拟机实现。
前面说了,对程序的执行就是对方法链的调用和执行,即可能会出现很多方法同时处于执行状态,此时对于执行引擎来说,活动线程中,只有栈顶的栈帧是有效的,称为当前栈帧,其关联的方法称为当前方法,执行引擎所运行的所有字节码指令只针对当前栈帧进行操作。
方法调用包含两种方法:解析和分派。解析调用一定是个静态过程,在编译期间完全确定,在类装载的解析阶段就会把涉及的符号引用全部转变为可确定的直接引用,不会延迟到运行期再去完成。而分派调用则可能是动态的也可能是静态的,根据分派依据的宗量数可分为单分派和多分派。(具体情形请参考《深入理解java虚拟机》这本书第8章)
方法执行即是指字节码解释执行引擎,包括解释执行和编译执行。而java编译器输出的指令流,基本上是一种基于栈的指令集架构。即Java虚拟机采用的是基于栈的字节码执行引擎。(具体情形请参考《深入理解java虚拟机》这本书第8章)
类从被加载到虚拟机内存中开始,到卸装出内存为止,它的整个生命周期包括了:加载,验证,准备,解析,初始化,使用和卸载七个阶段。其中验证、准备和解析三个部分称为连接,也就是说,一个Java类从字节代码到能够在JVM中被使用,需要经过加载、链接和初始化这三个步骤 。我们看一看Java虚拟机的体系结构。
Java虚拟机的体系结构如下图所示:

- 类装载器子系统,它根据给定的完整类名来装载类或接口
- 执行引擎,它负责执行那些包含 在被装载类的方法中的指令。
- 方法区以及一个堆,它们是由该虚拟机实例中所有线程共享的。当虚拟机装载一个class文 件时,它会从这个class文件包含的二进制数据中解析类型信息。然后,它把这些类型信息入到方法区中。当程序运行时,虚拟机会把所有该程序在运行时创建的对象都放到堆中。
- Java栈是由许多 栈帧 或者 帧组成的,一个栈帧包含 一个Java方法调用的状态。当线程调用一个Java方法时。虚拟机压入一个新的栈帧到该线程的Java栈中;当该方法返回时,这个栈帧就会从Java栈中被弹出或者抛弃。Java虚拟机没有寄存器,其指令集使用Java栈来存储中间数据。这样设计的原因是为了保持Java虚拟机的指令集尽量紧凑。同时也使于Java虚拟机在那些只有很少通用寄存器的平台上实现。另外,Java虚拟机的这种基于栈的体系结构,也有助于运行时某些虚拟机实现的动态编译器和即时编译器的代码优化。
我们将按照类的生命周期来谈谈Java虚拟机的工作,本篇我们先谈谈加载:
Java类加载的全过程,是加载、验证、准备、解析和初始化这五个阶段的过程。而加载阶段是类加载过程的一个阶段。在加载阶段,虚拟机需要完成以下三件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在Java堆中生成一个代表这个类的java.lang.Class对象,作为方法区这些数据的访问入口。
在这三件事情中,通过一个类的全限定名来获取定义此类的二进制字节流这个动作是在Java虚拟机外部来实现的,以便让应用程序自己决定如何去获取所需要的类。实现这个动作的代码模块被称为“类加载器”。
站在Java虚拟机的角度讲,只存在两种不同的类加载喊叫:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现(只限于Hot Spot,像MPR、Maxine等虚拟机,整个虚拟机本身都是由Java编写的,Bootstrap ClassLoader自然也是由Java语言实现的),是虚拟机自身的一部分;另外一种 用户自定义类装载器。前者是 Java 虚拟机实现的一部分,后者是 Java 程序的一部分。由不同的类装载器装载的类将被放在虚拟机内部的不同命名空间中 。从Java开发人员的角度来看,类加载器还可以划分的更细致一些,分为系统提供的类加载器与用户自定义的类加载器。
系统提供的类加载器:
系统提供的类装载器主要由下面三个:
- 启动类加载器(bootstrap classloader):它用来加载 Java 的核心库,是用原生代码(本地代码,与平台有关)来实现的,并不继承自java.lang.ClassLoader。这个类加载器负责将存放在<JAVA_HOME>\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识加的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用。
- 扩展类加载器(extensions classloader):扩展类加载器是由 Sun 的 ExtClassLoader(sun.misc.Launcher$ExtClassLoader) 实现的。它负责将 < Java_Runtime_Home >/lib/ext 或者由系统变量java.ext.dir 指定位置中的类库加载到内存中
- 应用程序类加载器(application classloader):系统类加载器是由 Sun 的 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的,由于这个类加载器是ClassLoader中getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序默认的类加载器。
用户自定义的类装载器是普通的Java对象,它的类必须派生自java.lang.ClassLoader类。ClassLoader中定义的方法为程序为程序提供了访问类装载器机制的接口。此外,对于每一个被装载的类型,Java虚拟机都会为它创建一个java.lang.Class类的实例来代表该类型。和所有其它对象一样,用户自定义的类装载器以有Class类的实例都放在内存中的堆区,而装载的类型信息则都放在方法区。
下面介绍一下java.lang.ClassLoader类:
为了完成加载类的这个职责,| 方法 | 说明 |
|---|---|
getParent() | 返回该类加载器的父类加载器。 |
loadClass(String name) | 加载名称为 name的类,返回的结果是 java.lang.Class类的实例。 |
findClass(String name) | 查找名称为 name的类,返回的结果是 java.lang.Class类的实例。 |
findLoadedClass(String name) | 查找名称为 name的已经被加载过的类,返回的结果是 java.lang.Class类的实例。 |
defineClass(String name, byte[] b, int off, int len) | 把字节数组 b中的内容转换成 Java 类,返回的结果是 java.lang.Class类的实例。这个方法被声明为 final的。 |
resolveClass(Class<?> c) | 链接指定的 Java 类。 |
类装载器的特征
Java类加载器有两个比较重要的特征:层次组织结构和代理模式。这两个特征也就是我们平时说的类加载器的双亲委派模型。层次组织结构指的是除了顶层为启动类加载器之外,其余的类加载器都有一个父类加载器,通过getParent()方法可以获取到。类加载器通过这种父亲-后代的方式组织在一起,形成树状层次结构。这里类加载器之间的父子关系一般不会以继承的关系来实现,而是都使用组合关系来复用父加载器的代码。代理模式则指的是一个类加载器既可以自己完成Java类的定义工作,也可以代理给其它的类加载器来完成。
- 类加载器的树状组织结构
在系统提供的类加载器中,除了启动类加载器之外,所有的类加载器都有一个父类加载器。通过
getParent()方法可以得到。对于系统提供的类加载器来说,系统类加载器的父类加载器是扩展类加载器,而扩展类加载器的父类加载器是启动类加载器;对于开发人员编写的类加载器来说,其父类加载器是加载此类加载器 Java 类的类加载器。因为类加载器 Java 类如同其它的 Java 类一样,也是要由类加载器来加载的。一般来说,开发人员编写的类加载器的父类加载器是系统类加载器。类加载器通过这种方式组织起来,形成树状结构。树的根节点就是引导类加载器。

下面代码演示了类加载器的树状组织结构

/**
* @param args
*/
public static void main(String[] args) {
ClassLoader loader = ClassloaderTree. class .getClassLoader();
while (loader!= null ){
System.out.println(loader);
loader = loader.getParent();
}
}
}
打印出来的结果为:
sun.misc.Launcher$ExtClassLoader@ad3ba4
第一个输出的是 ClassLoaderTree类的类加载器,即系统类加载器。它是 sun.misc.Launcher$AppClassLoader类的实例;第二个输出的是扩展类加载器,是 sun.misc.Launcher$ExtClassLoader类的实例。需要注意的是这里并没有输出引导类加载器,这是由于有些 JDK 的实现对于父类加载器是引导类加载器的情况,getParent()方法返回 null
代理模式
代理模式说的是双亲委派模型的工作过程:如果一个类加载器收到了类加载的请求,它首先不会自己尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围没有找到所需的类)时,子加载器才会尝试自己去加载。
那么为什么要使用代理模式呢,每个类加载器都由自己加载不是很好吗,搞得这么复杂干吗?要解释这个,就得首先说明Java虚拟机是如何判定两个类是相同的。在Java虚拟机中,对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,通俗来说,Java 虚拟机不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。即便是同样的字节代码,被不同的类加载器加载之后所得到的类,也是不同的。这个说的相同,包括代表类的Class对象的equals()方法、isAssignableFrom()方法、isInstance()方法的返回结果,也包括了使用instanceof关键字做对象所属关系判定等情况。
下面我们通过编写自定义的类加载器来分别加载同一个class文件,进而确定得到的类是否相同。
在 上表中列出的 java.lang.ClassLoader类的常用方法中,一般来说,自己开发的类加载器只需要覆写 findClass(String name)方法即可。java.lang.ClassLoader类的方法loadClass()封装了前面提到的代理模式的实现(loadClass的具体实现如下所示)。该方法会首先调用 findLoadedClass()方法来检查该类是否已经被加载过;如果没有加载过的话,会调用父类加载器的 loadClass()方法来尝试加载该类;如果父类加载器无法加载该类的话,就调用 findClass()方法来查找该类。因此,为了保证类加载器都正确实现代理模式,在开发自己的类加载器时,最好不要覆写 loadClass()方法,而是覆写findClass()方法。
throws ClassNotFoundException
{
// First, check if the class has already been loaded
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClass0(name);
}
} catch (ClassNotFoundException e) {
// If still not found, then invoke findClass in order
// to find the class.
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
在本例中,我们为了说明两个类加载器加载同一个class会得到不同的类,所以重写loadClass方法,如果只重写findClass方法,会由双亲来加载class文件,得不到想到的效果。
自定义的ClassLoader代码如下:
public class MyClassLoader extends ClassLoader {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
// TODO Auto-generated method stub
String fileName = name.substring(name.lastIndexOf(".")+1)+".class";
InputStream is = getClass().getResourceAsStream(fileName);
if ( is == null ){
return super .loadClass(name);
}
try {
byte [] b = new byte [is.available()];
is.read(b);
return defineClass(name,b,0,b.length);
} catch (IOException e) {
e.printStackTrace();
}
return super .loadClass(name);
}
}
代码很简单,就是加载与MyClassLoader同目录下的class类文件。
写一个辅助类
public class Sample {
private Sample instance;
public void setSample(Object obj){
this .instance = (Sample)obj;
}
}
写一个测试的类:
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class ClassLoaderTest {
/**
* @param args
* @throws ClassNotFoundException
* @throws IllegalAccessException
* @throws InstantiationException
* @throws NoSuchMethodException
* @throws SecurityException
* @throws InvocationTargetException
* @throws IllegalArgumentException
*/
public static void main(String[] args) throws InstantiationException, IllegalAccessException, ClassNotFoundException, SecurityException, NoSuchMethodException, IllegalArgumentException, InvocationTargetException {
MyClassLoader loader1 = new MyClassLoader();
MyClassLoader loader2 = new MyClassLoader();
Class class1 = loader1.loadClass("com.xiaoruoen.test.Sample");
Class class2 = loader2.loadClass("com.xiaoruoen.test.Sample");
Object obj1 = class1.newInstance();
Object obj2 = class2.newInstance();
Object obj3 = loader1.loadClass("com.xiaoruoen.test.ClassLoaderTest");
System.out.println(obj3);
System.out.println(obj3 instanceof com.xiaoruoen.test.ClassLoaderTest);
Method method = class1.getMethod("setSample", java.lang.Object. class );
method.invoke(obj1, obj2);
}
}
上面代码运行的结果为:
false
Exception in thread "main" java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at com.xiaoruoen.test.ClassLoaderTest.main(ClassLoaderTest.java:29)
Caused by: java.lang.ClassCastException: com.xiaoruoen.test.Sample cannot be cast to com.xiaoruoen.test.Sample
at com.xiaoruoen.test.Sample.setSample(Sample.java:8)
... 5 more
从给出的结果来看:
给出的运行结果可以看到,运行时抛出了java.lang.ClassCastException
异常。虽然两个对象 obj1
和 obj2
的类的名字相同,但是这两个类是由不同的类加载器实例来加载的,因此不被 Java 虚拟机认为是相同的。同样,我们使用了
MyClassLoader加载了一个名为
com.xiaoruoen.test.ClassLoaderTest的类,并实例化了这个类的对象。两行输出结果中,从第一句可以看到这个对象确实是类com.xiaoruoen.test.ClassLoaderTest实例化出来的对象,但从第二句可以发现这个对象与类
com.xiaoruoen.test.ClassLoaderTest做所属类型检查的时候却返回了false,这是因为虚拟机中存在了两个ClassLoaderTest类,一个是由系统应用程序类加载器加载的,一个是由我们自定义的类加载器加载的,虽然都是来自同一个Class文件,但依然是两个独立的类,做对象所属类型检查时结果自然是false。
了解了这一点之后,就可以理解代理模式的设计动机了。
代理模式是为了保证 Java 核心库的类型安全。所有 Java 应用都至少需要引用java.lang.Object
类,也就是说在运行的时候,java.lang.Object
这个类需要被加载到 Java 虚拟机中。如果这个加载过程由 Java 应用自己的类加载器来完成的话,很可能就存在多个版本的 java.lang.Object
类(
由上面的例子就可以看出来
),而且这些类之间是不兼容的。通过代理模式,对于 Java 核心库的类的加载工作由引导类加载器来统一完成,保证了 Java 应用所使用的都是同一个版本的 Java 核心库的类,是互相兼容的。
线程上下文类加载器(context class loader)是从 JDK 1.2 开始引入的。类 java.lang.Thread中的方法 getContextClassLoader()和setContextClassLoader(ClassLoader cl)用来获取和设置线程的上下文类加载器。如果没有通过setContextClassLoader(ClassLoader cl)方法进行设置的话,线程将继承其父线程的上下文类加载器。Java 应用运行的初始线程的上下文类加载器是系统类加载器。在线程中运行的代码可以通过此类加载器来加载类和资源。
前面提到的类加载器的代理模式并不能解决 Java 应用开发中会遇到的类加载器的全部问题。Java 提供了很多服务提供者接口(Service Provider Interface,SPI),允许第三方为这些接口提供实现。常见的 SPI 有 JDBC、JCE、JNDI、JAXP 和 JBI 等。这些 SPI 的接口由 Java 核心库来提供,如 JAXP 的 SPI 接口定义包含在 javax.xml.parsers包中。这些 SPI 的实现代码很可能是作为 Java 应用所依赖的 jar 包被包含进来,可以通过类路径(CLASSPATH)来找到,如实现了 JAXP SPI 的
javax.xml.parsers.DocumentBuilderFactory
类中的
newInstance()
方法用来生成一个新的
DocumentBuilderFactory
的实例。这里的实例的真正的类是继承自
javax.xml.parsers.DocumentBuilderFactory
,由 SPI 的实现所提供的。如在 Apache Xerces 中,实现的类是
org.apache.xerces.jaxp.DocumentBuilderFactoryImpl
。而问题在于,
SPI 的接口是 Java 核心库的一部分,是由引导类加载器来加载的;SPI 实现的 Java 类一般是由系统类加载器来加载的。
引导类加载器是无法找到 SPI 的实现类的,因为它只加载 Java 的核心库。它也不能代理给系统类加载器,因为它是系统类加载器的祖先类加载器
。
也就是说,类加载器的代理模式无法解决这个问题。
线程上下文类加载器正好解决了这个问题。如果不做任何的设置,Java 应用的线程的上下文类加载器默认就是系统上下文类加载器。在 SPI 接口的代码中使用线程上下文类加载器,就可以成功的加载到 SPI 实现的类。线程上下文类加载器在很多 SPI 的实现中都会用到。

















 2721
2721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









