



大模型基础概念
背景知识
以下知识是我们了解大模型所需要的计算机背景信息。
-
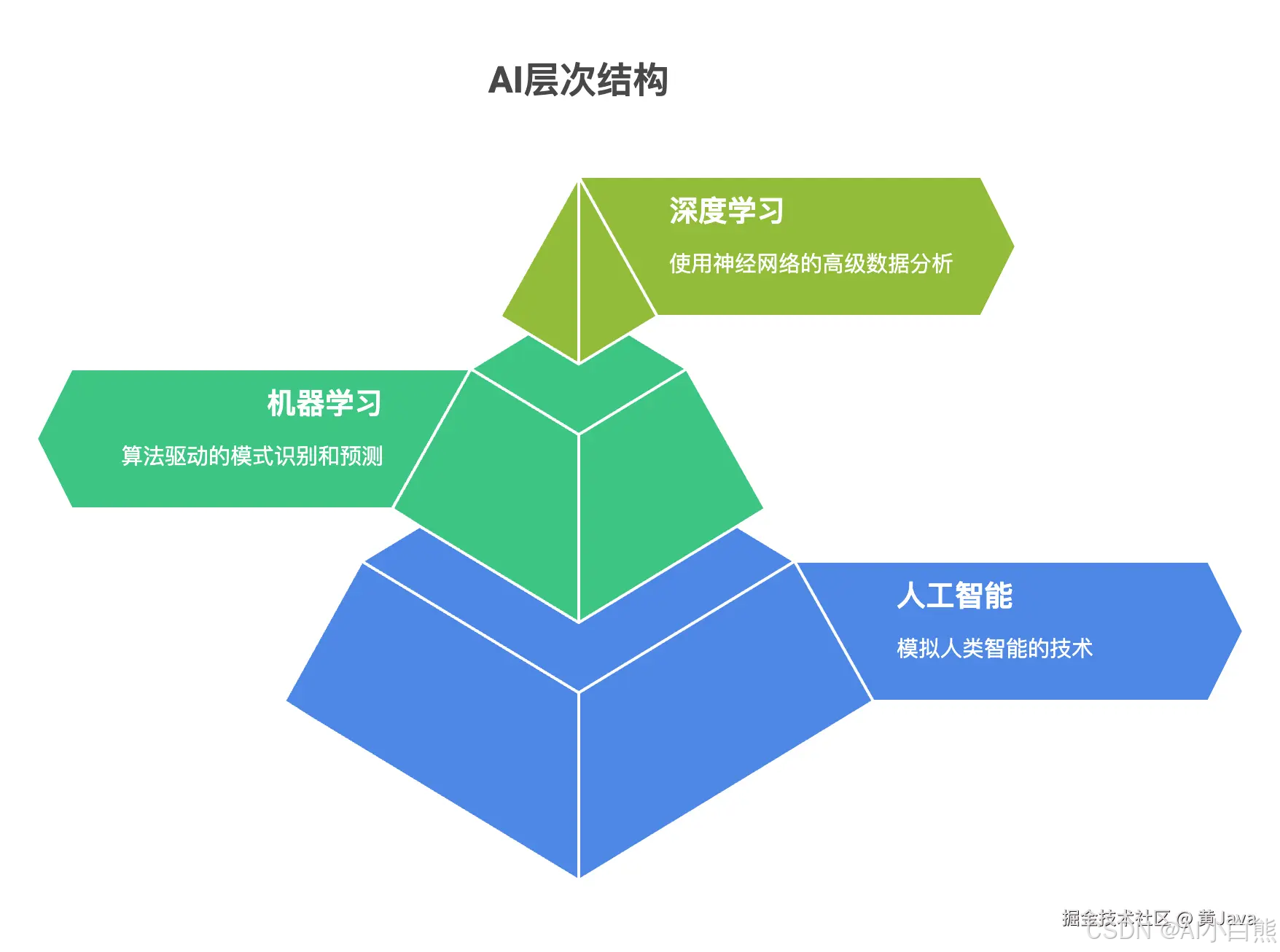
人工智能:Artificial Intelligence,简称AI。
- 人工通用智能:Artificial General Intelligent,简称AGI。
- 人工智能生成内容:Artificial Intelligence Generated Content,简称AIGC。
-
机器学习:是人工智能的一个子集,核心思想是不需要显式编程,让计算机通过算法自行学习和改进,从而识别模式、做出预测和决策。
-
深度学习:是机器学习的一个子集,核心是使用人工神经网络模仿人脑处理信息的方式,通过层次化的方法提取和表示数据的特征,专注于非结构化数据的处理。
具体层级结构如下图所示:
概念知识
以下内容是学习大模型需要了解的相关概念。
-
大模型:深度学习算法 + 海量数据 + 超强算力。大模型主要分为两类:
- 判别模型:主要是识别不同场景下的差异,做出判断。
- 生成模型:基于特定的场景学习特征,解决问题。
以识别「猫」和「狗」为例,判别模型主要学习的是「猫」和「狗」的区别,而生成模型主要学习的是「猫」和「狗」的特征。生成模型可以根据学习的特征生成一只「猫」,而判别模型则不行。
-
大语言模型:Large Language Model,简称LLM。主要指的是用于自然语言相关任务的深度学习模型。
-
Transformer架构:2017年提出的一种深度学习架构,核心思想是使用自注意力机制(Self-Attention)来捕捉输入序列中的长距离依赖关系,而无需依赖循环神经网络(RNN)或卷积神经网络(CNN)。通俗来说,自注意力机制允许模型在处理序列的每个元素时,同时考虑序列中的所有其他元素(不仅仅是相邻元素),从而更好地理解上下文信息。
-
文本生成方式:大语言模型通过预测下一个词(词向量)出现的概率来实现文本生成,本质上是基于概率的采样算法。以下是两种常见的采样策略:
- Top-K:在生成每个词时,模型只从概率最高的前 K 个候选词中进行选择。例如,K=3 时,只选择概率最高的 3 个词进行采样。
- Top-P:在生成每个词时,模型从累积概率超过阈值 P 的最小词集合中进行选择。例如,P=0.7 时,对概率从大到小的词进行选择,直到累加概率超过 0.7,再从已选择的词中进行采样。
上述两个策略主要用于控制采样的多样性和质量,其中Top-K适合需要严格控制多样性的任务;Top-P适合需要平衡多样性和质量的任务。
-
温度:Temperature。温度用于调控采样过程中的概率分布,控制采样的随机性和多样性。
- 采样的概率分布: P(wi)=exp(zi/T)∑jexp(zj/T)P(w_i) = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)}P(wi)=∑jexp(zj/T)exp(zi/T) 。
其中T就是温度。当T>1时,会增加低概率词被选中的概率;T<1时,会倾向于选择概率更高的词。
-
-
端到端模型:输入后只经过一个模型就能得到最终输出,这种模型称为端到端模型。
- 优点:延迟低,模型效果好,灵活性。
- 缺点:训练难度高,解释性差。
-
大模型压缩:指通过一系列技术手段,减少大型深度学习模型的规模、计算复杂度和存储需求,同时尽量保持其性能。主要方法包括:
- 量化:调整参数精度,例如将 32 位浮点数转换为 16 位浮点数。
- 蒸馏:使用一个大模型(教师模型)指导一个小模型(学生模型)学习,从而将大模型的知识转移到小模型中。
- 剪枝:移除模型中对输出影响较小的权重或神经元。
-
泛化能力:大模型最重要的能力之一,指的是模型通过训练,能够总结出一些有价值的方法论。
- 预期:模型能够举一反三,有能力解决之前自己没有遇到过的问题。
训练&优化方法
以下知识是我们了解打磨训练和优化方法的内容。
-
预训练:通过海量数据训练一个大模型,从而得到一个通用的基础模型。
- 增量预训练:在已有的大模型基础上,通过特定领域的知识进行再次预训练,增强模型在某些方面的能力。此过程会修改大模型本身的参数。例如,通用模型基于金融领域的知识,训练成一个金融领域的专用大模型。
-
微调:Fine-tuning,通过特定或私有化数据对模型进行改良。此过程会修改大模型本身的参数。通常的数据格式为
<input, output>。微调有两种方式:-
全量微调:在微调过程中理论上会调整所有参数。
-
LoRA微调:通过指定一个参数 Rank,用更少的参数进行调整的一种微调方式。
- 原理:原有参数为M_N的矩阵,调整后的参数为(M_K的矩阵)和(K_N的矩阵),其中K就是Rank。根据矩阵运算:M_N的矩阵=(M_K的矩阵)·(K_N的矩阵)。
- 优点:之前需要调整M_N个参数,现在只需要调整M_K+K*N个参数,一般选取较小的K使得参数修改量大大减少,降低资源需求。例如M=100,N=100,K=3,前者为10000个参数,后者为600个参数。
-
-
对齐:Alignment,调整模型的行为,使其输出更符合人类的价值观、偏好或任务需求。该阶段通常在「微调」之后进行。通常的数据格式为
<input, accept, reject>。- 人类反馈强化学习:RLHF,对齐方式的一种,主要通过一个奖励模型来给予被训练模型反馈,从而改进被训练模型。
-
提示工程:指通过设计和优化输入提示(Prompt),来引导大模型生成符合预期的输出。
-
上下文学习:In-Context Learning,指模型在不更新参数的情况下,仅通过输入中的少量示例或任务描述,就能快速适应新任务并生成符合预期的输出。这种方式主要解决模型不知道自己知道的问题。
- Prompt结构:instruction(你要做什么事情)、requirement(你应该怎么做,要求是什么)、example(s)(给的案例)、input(实际问题)。
- 关注点:不能包含太大的上下文;需要保障案例的多样性;需要保证案例的代表性。
-
灾难性遗忘:模型在训练的过程中,可能会遗忘掉之前已有的一些能力。这个问题无法避免。
-
幻觉:指的是大模型的乱说。主要包含:上下文的矛盾、与Prompt要求不一致、与事实矛盾、荒谬的回复。
- 产生原因:训练的数据质量不高(信息不准确、多样性缺乏),训练过程中存在问题(过拟合),生成过程存在问题,提示不明确有歧义。
应用
以下知识是大模型应用中我们需要了解的内容。
-
RAG:Retrieval-Augmented Generation,结合了数据检索和生成的一个模型架构,核心思想是通过从外部知识库中检索相关信息,并结合生成模型的能力,生成更准确、更可靠的回答。
-
原理:对已有知识库文档进行分段(chunks)-> 存储到向量数据库中 -> 根据问题检索对应的向量数据库,得到答案(二次排序)-> 将问题和答案构造成 Prompt 给到大模型 -> 大模型处理润色后给到用户回答。
-
文档分段:根据语义动态切分。
-
存储数据库:文档向量化。
-
检索:先对问题进行向量化(问题改写、扩充),然后计算与结果的向量相似度匹配,取 Top-N。
- 相似度匹配:数学原理是计算余弦相似度,向量间空间夹角小的相似度高。
-
排序:根据相关性进行二次精排。
-
Prompt构造:如果数据量太大,需要考虑压缩。
-
-
【拓展】知识图谱:一种结构化的知识表示形式,用于描述现实世界中的实体(如人、地点、事件等)及其之间的关系。
- 在大模型中的应用场景:在RAG场景中搭配向量数据库使用可以给模型提供更多信息,减少幻觉问题。
-
-
MoE:混合专家模型。
- 构成:由1个路由(Router)+多个专家(Expert)构成,路由负责将问题路由给到对应的专家进行解决,这个过程中需要做到合理均衡的分配。问题分配给对应专家后,让多个专家共同去做决策。
-
Agent:
对比理解
以下知识是通过对比方式,帮助我们加深对上述知识的理解。
微调和RAG的区别,应用场景的选择:
| 区别&场景 | 微调 | RAG |
|---|---|---|
| 是否改动模型 | 是 | 否 |
| 动态变化数据源 | 不推荐 | 推荐 |
| 模型定制 | 推荐 | 不推荐 |
| 产生幻觉概率 | 高 | 低 |
| 可解释性 | 低 | 高 |
| 成本 | 高 | 低 |
| 延迟 | 低 | 高 |
| 应用到智能设备 | 推荐 | 不推荐 |
增量预训练、微调、上下文学习的区别:
| 区别&场景 | 增量预训练 | 微调 | 上下文学习 |
|---|---|---|---|
| 参数是否更新 | 是 | 是 | 否 |
| 训练数据要求 | 大量 | 少量 | 不需要(写到Prompt里) |
| 训练效率 | 非常低 | 低 | - |
| 灵活度 | 非常低 | 低 | 高 |
| 成本 | 非常高 | 高 | 低 |
| 实用性 | 很低 | 中 | 非常高 |
微调、RAG、上下文学习之间的选择:
-
能力缺乏:
- 能力相差较多,需要系统性学习,选择微调。
- 能力相差不多,需要背景知识,选择上下文学习。
-
能力足够:缺乏参考资料,选择RAG。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











