



文章目录
1、正则表达式
1.1 概述
- 正则表达式是一种用来描述字符串模式的规则
- 功能:检索、替换、过滤符合特定规则的字符串
- 系统日志筛选(如定位“登录失败”“服务启动失败”)
- 配置文件解析
- 文本查找替换
- 脚本编程中的条件匹配
1.2 正则表达式组成
1.2.1 元字符
.匹配任意单个字符- 匹配任意单个字符(除
\r\n换行符、回车符)
- 匹配任意单个字符(除
[]匹配字符集[a-z][0-9][A-Z]- 匹配list列表中的一个字符 例: go[ola]d,[abc]、[a-z]、[a-z0-9]
[^list]匹配非集合中的字符- 匹配任意不在list列表中的一个字符 例: [^a-z] 、[^0-9] 、[^A-Z0-9]
^行首$行尾\转义符
1.2.2 次数
*0 次或多次
匹配前面子表达式0次或者多次 例:goo*d、go.*d
\+至少 1 次
匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
\{n\}恰好 n 次
匹配前面的子表达式n次,例:go\{2\}d、'[O-9]\{2\}'匹配两位数字
\{m,n\}m 到 n 次
匹配前面的子表达式n到m次,例: go\{2,3\)d、'[0-9]\{2,3\}'匹配两位到三位数字
\{n,\}至少 n 次
匹配前面的子表达式不少于n次,例: go\{2,\}d、' [0-9]\{2,\}'匹配两位及两位以上数字
1.2.3 案例
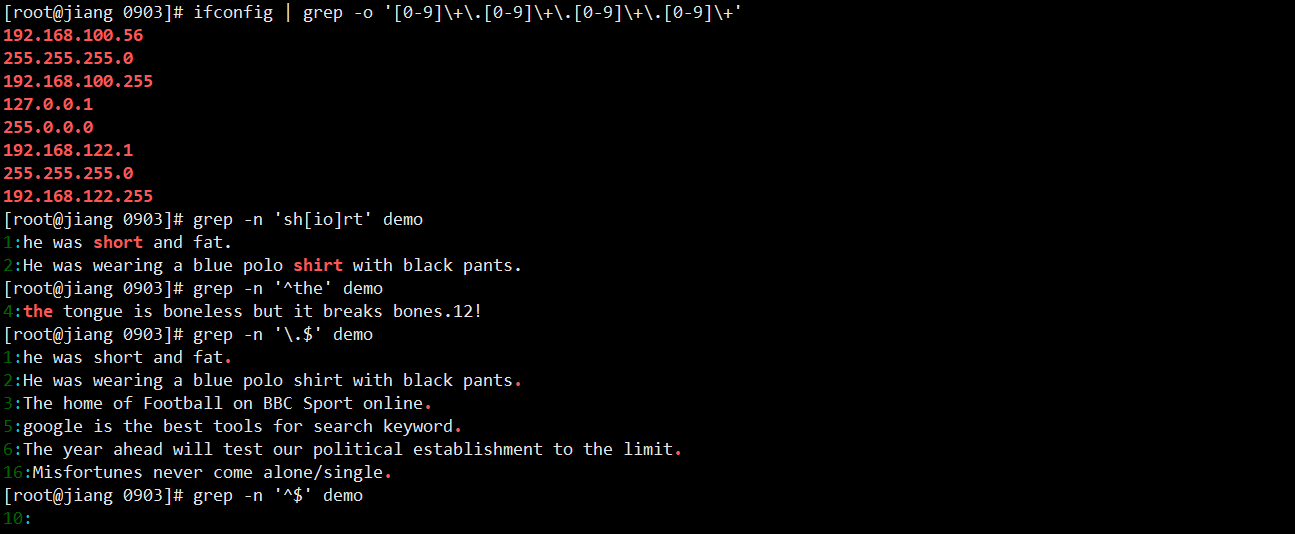
## 查找ip
ifconfig | grep -o '[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+'
## shirt 或 short
grep -n 'sh[io]rt' demo
## 首行是 the
grep -n '^the' demo
## 行尾是 .
grep -n '\.$' demo
## 空行
grep -n '^$' demo
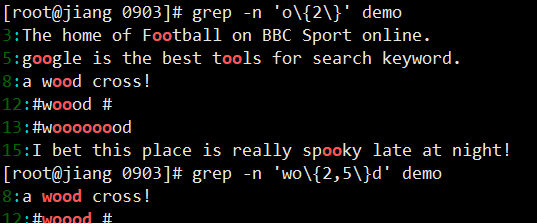
## 两个 o 的字符
grep -n 'o\{2\}' demo
## 以 w 开头以 d 结尾,中间包含 2~5 个 o
grep -n 'wo\{2,5\}d' demo
## 以 w 开头以 d 结尾,中间包含 2 个或 2 个以上 o
grep -n 'wo\{2,\}d' demo
2、常用小工具
2.1 截取-cut
cut:常用于从文本中抽取需要的字段
注意:cut只擅长于处理单个字符为间隔的文本
常用选项
-b:按字节截取-c:按字符截取(中文推荐用-c)-d:指定分隔符(默认 TAB)-f:指定字段(需配合-d)
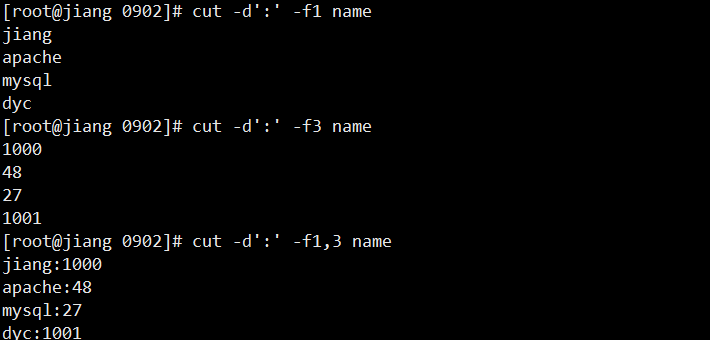
# 截取第1列
cut -d':' -f1 name
# 截取第3列
cut -d':' -f3 name
# 截取第1和3列
cut -d':' -f1,3 name
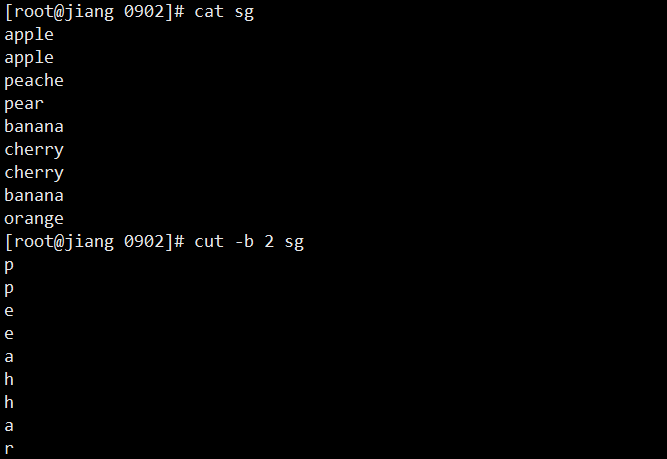
# 截取第2个字符
cat sg | cut -b 2
cat zw | cut -c 2

2.2 排序-sort
常用选项
-t:指定分隔符-k:指定排序字段-n:按数值排序(默认是字典序)-r:降序-u:去重(等价于uniq)-o:输出到文件
# 升序
sort sg
# 倒叙
sort -r sg
# 去重
sort -u sg
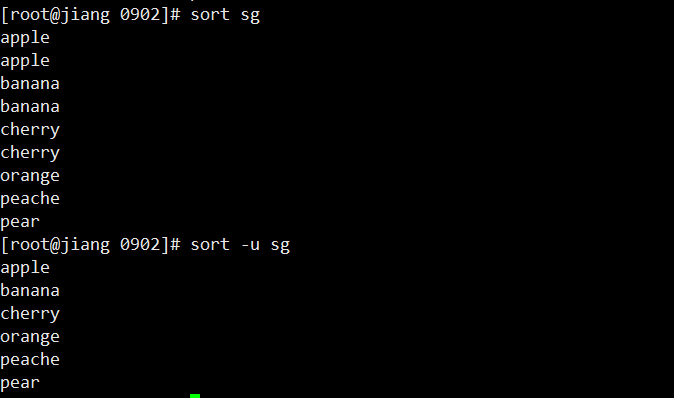
# 以冒号分隔,按第3列数值升序
sort -n -t: -k3 ceshi
# 排序结果保存
sort -nr -t: -k3 ceshi -o out.txt
2.3 uniq-去重
只能去掉相邻的重复行
常用选项
-c:对重复的行进行计数-d:只显示重复行-u:只显示唯一行
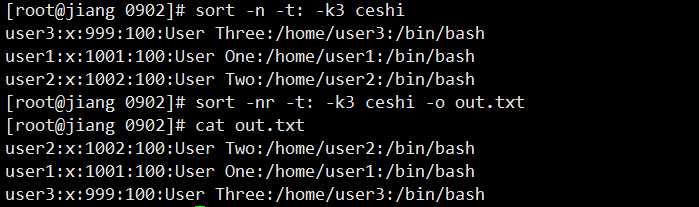
# 去掉相邻重复行
uniq sg
# 全局去重
sort sg | uniq
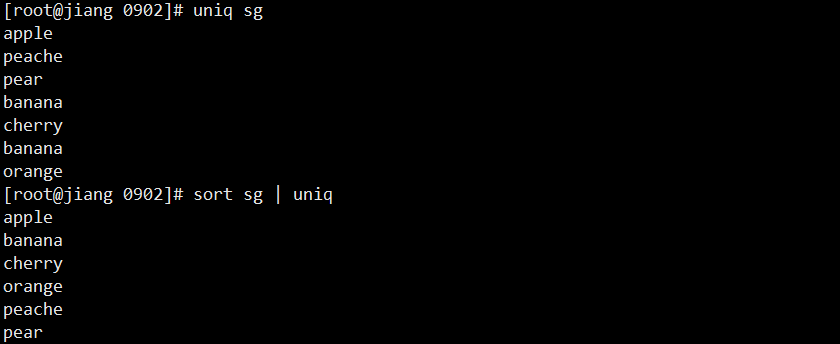
# 统计每行出现次数
sort sg | uniq -c
# 只显示重复行
sort sg | uniq -d
# 只显示不重复行
sort sg | uniq -u
# 查看登录用户
who | awk '{print $1}'| uniq
# 查看登陆过系统的用户
last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp

2.4 tr-替换/删除
常用选项
-d:删除字符-s:压缩重复字符,只保留一个
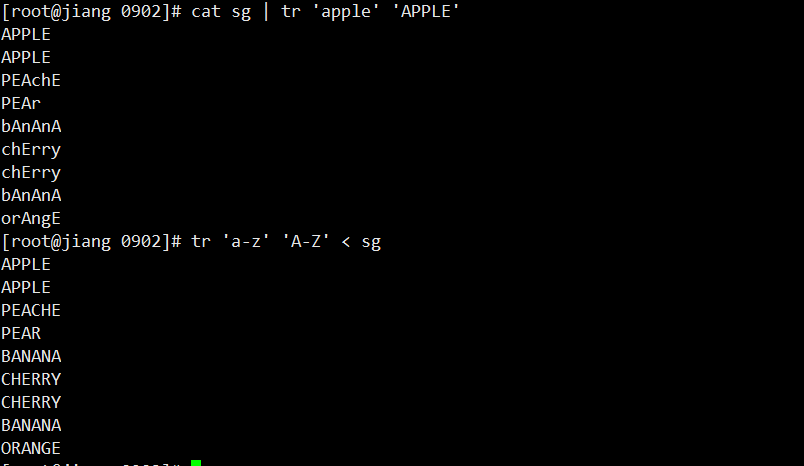
# 小写转大写
tr 'a-z' 'A-Z' < sg
# 对应字母的替换
cat sg | tr 'apple' 'APPLE'
# 把a 替换 ''
cat sg | tr 'a' ' '
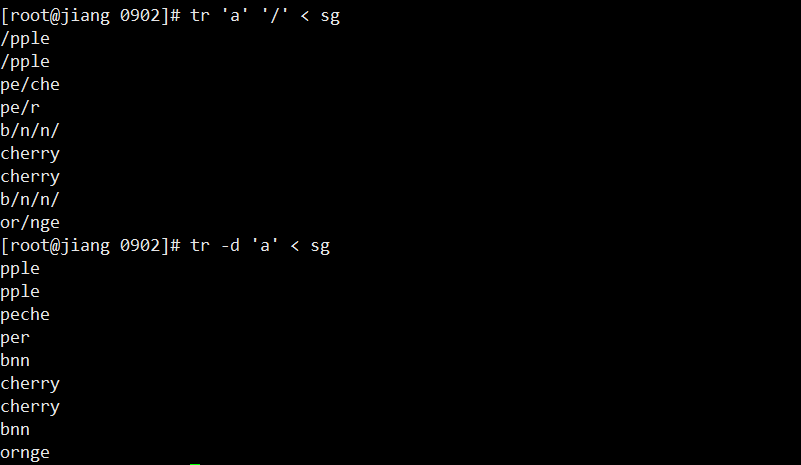
# 替换 a -> /
tr 'a' '/' < sg
# 删除所有 a
tr -d 'a' < sg
# 删除换行符
tr -d '\n' < sg
# 连续 p 压缩成一个
tr -s 'p' < sg
总结
正则表达式是一种用来描述字符串模式的规则。功能:检索、替换、过滤符合特定规则的字符串。
元字符
^匹配输入字符串的开始位置。除非在方括号表达式中使用,表示不包含该字符集合。要匹配^字符本身,请使用\^$匹配输入字符串的结尾位置。如果设置了RegExp 对象的 Multiline 属性,则$也匹配换行符\n或回车符\r,要匹配$字符本身,请使用\$.匹配除“\r\n”之外的任何单个字符\反斜杠,又叫转义字符,去除其后紧跟的元字符或通配符的特殊意义*匹配前面的子表达式零次或多次。要匹配*字符,请使用\*[ ]字符集合。匹配所包含的任意一个字符。例如,[abc]可以匹配“plain”中的“a”[^]匹配未包含的一个任意字符。例如[^abc]可以匹配 plin 中任何一个字母[n1-n2]字符范围。匹配指定范围内的任意一个字符。例如[a-z]可以匹配 a 到 z 范围内的任意一个小写字母字符{n}n 是一个非负整数,匹配确定的 n 次。例如o{2}不能匹配 Bob 中的 o 但是能匹配 food 中的 oo{n,}n 是一个非负整数,至少匹配 n 次。例如o{2,}不能匹配 Bob 中的 o ,但能匹配 foooood 中的所有o{n,m}m 和 n 均为非负整数,其中 n<=m,最少匹配 n 次且最多匹配m 次

















 33万+
33万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









