






背景
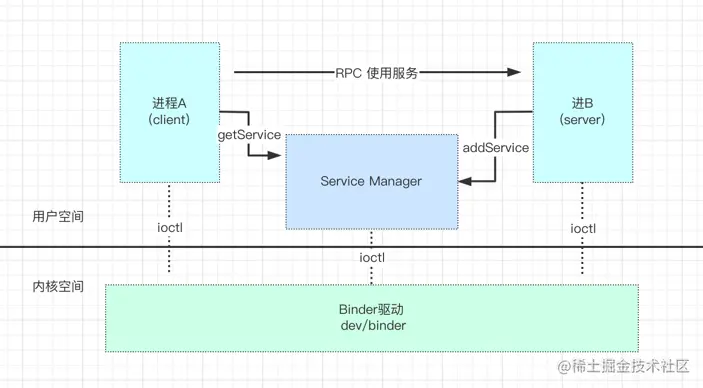
Binder是Android进程间的一种通信方式,属于C/S架构。 Android系统的底层基于Linux内核。相对与传统的IPC方式,Binder在效率上 有显著的优势。通过Binder来实现进程间通信本质上是通过Binder驱动来完成的。
Binder Driver将自己注册为一个misc device(杂项设备),并向上层提供驱动节点:dev/binder。 这种"杂项"设备不是真正的物理 硬件设备,而是虚拟驱动。它运行在内核态中,提供open()、mmap()、ioctl()等常用操作。
Binder通信涉及到四个部分:
- Server: 提供接口服务的具体实现;向
ServiceManager(SM)注册服务。 - Client: 从SM获取服务,调用服务提供的接口。
- ServiceManager: Binder大管家。管理binder相关的服务。提供注册、查询服务等接口
- Binder驱动: 本质上实现跨进程通信。
一、Android为什么要采用Binder机制
Linux本身提供了多种多进程的通信方式: 管道、信号量、队列、socket、共享内存
- 管道:只能单向通信。 进程A到管道一次拷贝,管道到进程B一次拷贝,总共两次拷贝(用户->内核->用户)。
- 信号量:一般作为进程间的同步锁来使用。
- 信号:一般是用来内核给应用发送某个信号通知,如非法访问某个内存地址、杀死进程信号。
- 队列:进程A到队列一次拷贝,队列到进程B一次拷贝,总共两次拷贝(用户->内核->用户)。
- socket: 通信效率较低,开销大。分为本机基于fd的socket低速通信,和基于网络的tcp/udp的socket。需要两次拷贝。
- 共享内存:让两个进程映射到同一个内存缓冲区,实现共享,无需拷贝。但是需要自己维护同步过程,复杂且难用。
- Binder:通过mmap映射机制,让应用进程可以直接访问内核内存,减少了一次拷贝。效率仅次于共享内存。
二、C/S 角度
Binder通信过程中涉及到了多个C/S场景:
- 一般情况下是client作为客户端,server作为服务端。
- 当注册服务时,Server作为client端,SM作为server端。
- 当获取服务时,client作为客户端,SM作为服务端。
三、分层角度
3.1 java层
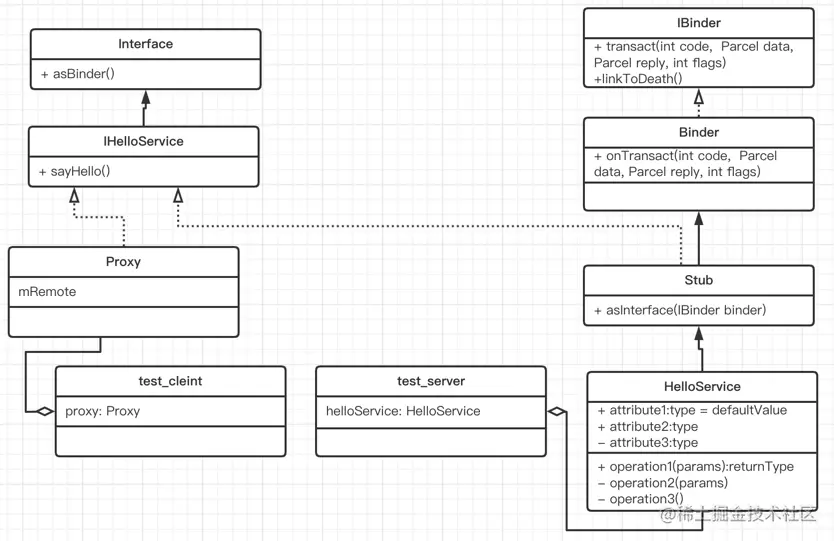
涉及到的类:
假设定义一个IHelloService.aidl文件,经过编译会生成IHelloService.java文件。 通信过程如下:
- Server:
HelloService继承内部抽象类Stub,实现接口sayHello()。- 调用
ServiceManager.addService方法,注册服务到ServiceManager
- Client:
- client通过
ServiceManager获取到Server的本IBinder对象 - 通过调用
IHelloService.asInterface(IBinder obj)转换成一个IHelloService本地对象。 - 调用接口
sayHello()完成跟服务端通信
client和server整个过程涉及到类图 :
重点:
Proxy中的mRemote其实是一个BinderProxy对象。BinderProxy的mNativeData指向的是一个c++ 层的Binder对象,实际上一个BpBinder。
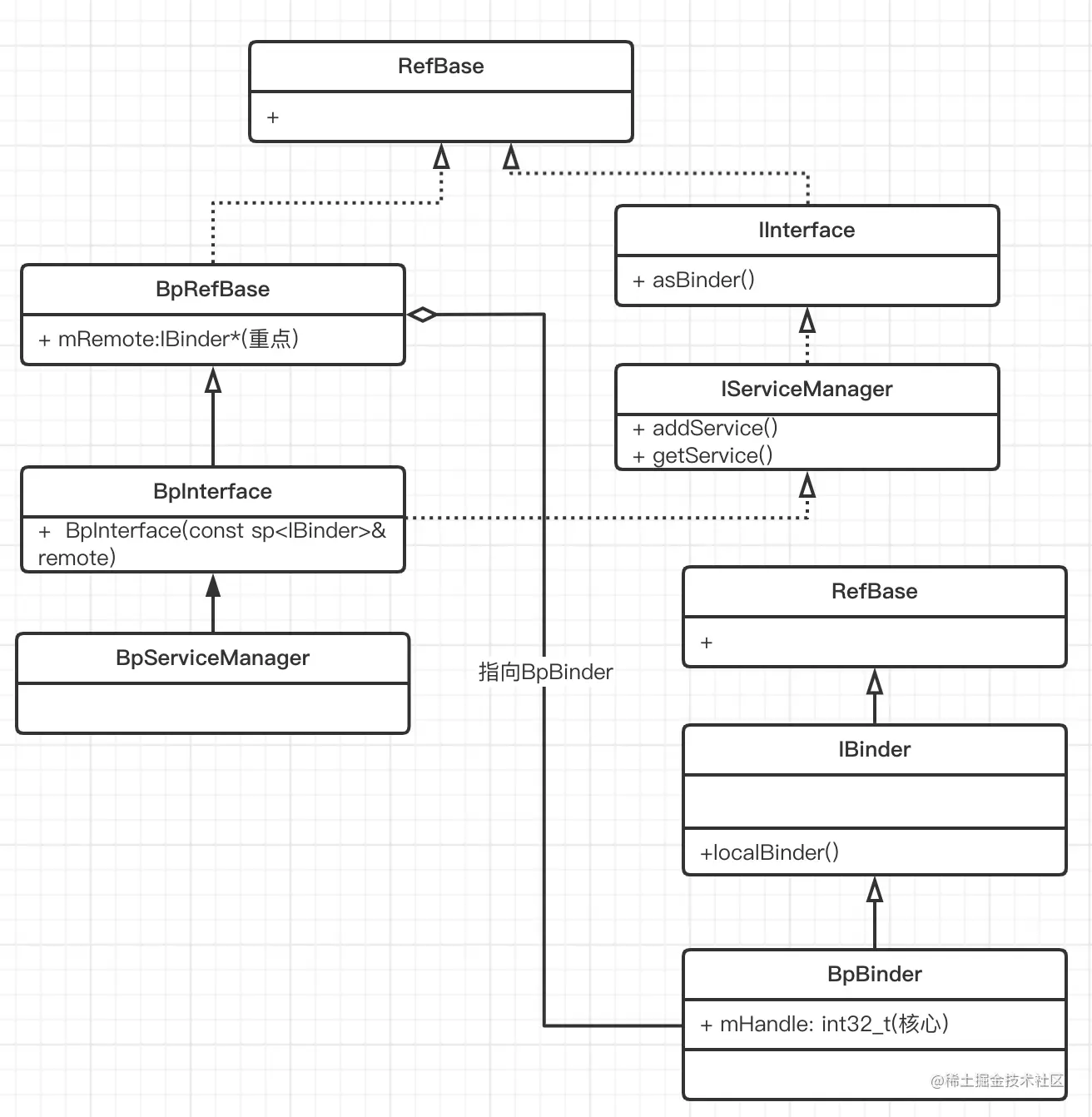
ServiceManager类相关的类图:

重点:
ServiceManagerProxy中的mRemote是一个binderProxy对象。BinderProxy的mNativeData指向的是一个c++ 层的Binder对象,实际上一个BpBinder。
3.2 c++层
java层把数据封装好后,通过BinderProxy中的native指针,把数据传到了c++层。 从client客户端角度出发,会有BpBinder对象来完成接下来的操作。
总体上来讲就算没有java层,c++层完全可以实现客户端和服务端通过Binder驱动来完成通信。因此,进程通信的核心逻辑应该在c++层。里面肯定会涉及到ioctl()、open()、mmap()等系统调用的操作。
ServiceManager类图如下:
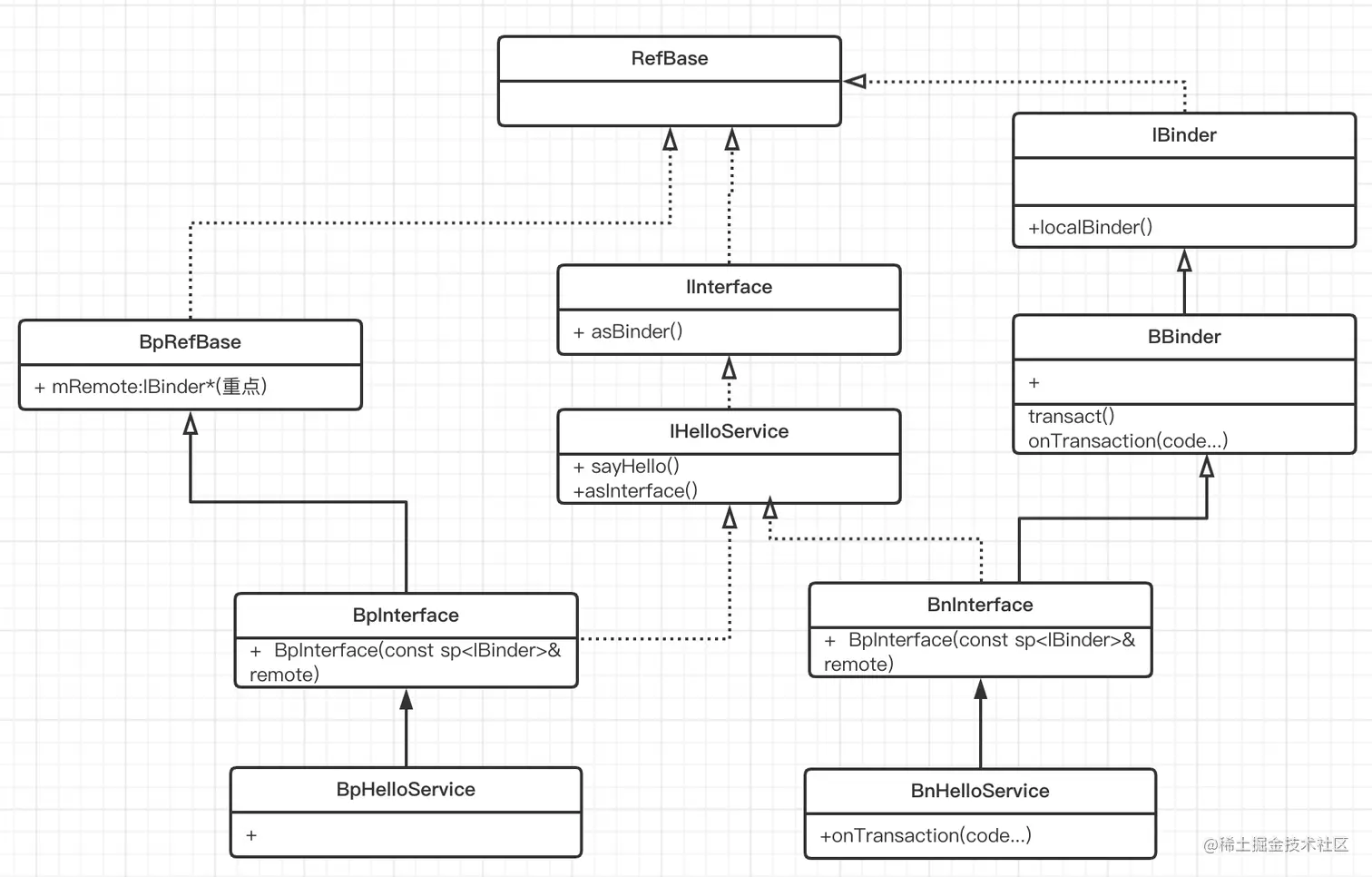
BpRefBase 类里面有一个IBinder *指针 类型的成员变量 mRemote。 mRemote指向了一个BpBinder对象, BpBinder里面含有一个mHandle成员变量。
HelloService相关类图:
3.3 内核驱动层

这个已经很清晰表明了内核中发生的事情。Binder驱动作为一个misc “杂项驱动”,它会在系统初始化阶段把binder_open()、binder_ioctl()、binder_mmap() 等函数完成注册。当用户态调用open进入到内核中,内核会直接调用之前注册好的驱动函数。
在内核态,对于每一个进程都会创建一个binder_proc与之对应。binder_proc中会有binder_buffer。这一块buffer缓冲区就是通过mmap()映射而来,因此,只要Client把数据copy_from_user()到buffer,然后通知server直接读取buffer中的数据即可。
Binder 解析之驱动层理解
一、 驱动初始化
Binder驱动作为misc 设备,在系统启动的时候就会完成注册。
common/drivers/char/misc.c
static int __init init_binder_device(const char *name)
{
int ret;
struct binder_device *binder_device;
binder_device = kzalloc(sizeof(*binder_device), GFP_KERNEL);
if (!binder_device)
return -ENOMEM;
binder_device->miscdev.fops = &binder_fops; //这个就是驱动注册函数
...
// 调用misc_register注册binder驱动
ret = misc_register(&binder_device->miscdev);
if (ret < 0) {
kfree(binder_device);
return ret;
}
hlist_add_head(&binder_device->hlist, &binder_devices);
return ret;
}
binder_fops对应的结构体:
const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = compat_ptr_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
从上面可以看出,系统调用和驱动函数的对应关系:

二、 驱动提供的函数
common/drivers/android/binder.c
2.1 binder_open()
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc, *itr; //每一个进程对应一个binder_proc结构体
struct binder_device *binder_dev;
struct binderfs_info *info;
struct dentry *binder_binderfs_dir_entry_proc = NULL;
bool existing_pid = false;
proc = kzalloc(sizeof(*proc), GFP_KERNEL); // 分配内存空间
if (proc == NULL)
return -ENOMEM;
...
INIT_LIST_HEAD(&proc->todo); //初始化todo 链表
init_waitqueue_head(&proc->freeze_wait); wait链表
/* binderfs stashes devices in i_private */
...
refcount_inc(&binder_dev->ref);
proc->context = &binder_dev->context;
binder_alloc_init(&proc->alloc);
binder_stats_created(BINDER_STAT_PROC);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
INIT_LIST_HEAD(&proc->waiting_threads);
filp->private_data = proc; // file中的private_data指向biner_proc对象
mutex_lock(&binder_procs_lock);
hlist_for_each_entry(itr, &binder_procs, proc_node) {
if (itr->pid == proc->pid) {
existing_pid = true;
break;
}
}
hlist_add_head(&proc->proc_node, &binder_procs); // 把binder_node节点加到binder_proc表头的队列中
mutex_unlock(&binder_procs_lock);
...
return 0;
}
不管是client还是server,还是serviceManager都会先打开驱动。当某个进程打开驱动时候,内核会创建binder_proc对象(其实就是代表了这个进程),把proc加入到静态全局的procs链表中。 proc对象中有binder_node节点链表。
2.2 binder_mmap()
static int binder_mmap(struct file *filp, struct vm_area_struct *vma) //vma 是应用进程的某块虚拟内存区域
{
// 得到进程的proc结构体
struct binder_proc *proc = filp->private_data;
if (proc->tsk != current->group_leader)
return -EINVAL;
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
pr_err("%s: %d %lx-%lx %s failed %d\n", __func__,
proc->pid, vma->vm_start, vma->vm_end, "bad vm_flags", -EPERM);
return -EPERM;
}
vma->vm_flags |= VM_DONTCOPY | VM_MIXEDMAP;
vma->vm_flags &= ~VM_MAYWRITE;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
return binder_alloc_mmap_handler(&proc->alloc, vma);
}
int binder_alloc_mmap_handler(struct binder_alloc *alloc,
struct vm_area_struct *vma)
{
int ret;
const char *failure_string;
struct binder_buffer *buffer; // binder驱动对应的物理内存的内核中虚拟内存描述
mutex_lock(&binder_alloc_mmap_lock);
if (alloc->buffer_size) { //是否已经映射??
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
alloc->buffer_size = min_t(unsigned long, vma->vm_end - vma->vm_start,
SZ_4M);// 分配应用的虚拟内存空间,最大值为4M。
mutex_unlock(&binder_alloc_mmap_lock);
alloc->buffer = (void __user *)vma->vm_start; //buffer指向应用进程的虚拟内存的起始地址
alloc->pages = kcalloc(alloc->buffer_size / PAGE_SIZE,
sizeof(alloc->pages[0]),
GFP_KERNEL); //计算偏移量offset。实际上只为进程分配了一个物理页的大小 4k
if (alloc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
buffer = kzalloc(sizeof(*buffer), GFP_KERNEL);
if (!buffer) {
ret = -ENOMEM;
failure_string = "alloc buffer struct";
goto err_alloc_buf_struct_failed;
}
buffer->user_data = alloc->buffer;
list_add(&buffer->entry, &alloc->buffers);
buffer->free = 1;
binder_insert_free_buffer(alloc, buffer);
alloc->free_async_space = alloc->buffer_size / 2;
binder_alloc_set_vma(alloc, vma);
mmgrab(alloc->vma_vm_mm);
return 0;
return ret;
}主要职责:
- vma表示应用进程的虚拟地址空间。
- 通过
mmap()机制让vma与某块物理页内存进行了映射。 - 同时让bider驱动内核的虚拟地址空间
binder_proc->buffer与应用进程的虚拟内存大小一致 - 让该
物理页与驱动的虚拟内存空间进行映射。 - 至此,应用进程就和驱动内核映射了同一块物理空间,应用进程可直接进行访问,而不用拷贝。
2.3 binder_ioctl()
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
/*pr_info("binder_ioctl: %d:%d %x %lx\n",
proc->pid, current->pid, cmd, arg);*/
binder_selftest_alloc(&proc->alloc);
trace_binder_ioctl(cmd, arg);
//挂起应用进程,等待唤醒
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
//从proc的threads链表中查询 thread当前线程
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
case BINDER_WRITE_READ: // 接收和发送binder数据
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
...
case BINDER_SET_CONTEXT_MGR_EXT: { // 设置serviceManager为全局静态的binder大管家
struct flat_binder_object fbo;
if (copy_from_user(&fbo, ubuf, sizeof(fbo))) {
ret = -EINVAL;
goto err;
}
ret = binder_ioctl_set_ctx_mgr(filp, &fbo);
if (ret)
goto err;
break;
}
...
default:
ret = -EINVAL;
goto err;
}
ret = 0;
return ret;
}
只贴出来两个核心的功能:
- 收发binder数据
- 设置serviceManager为全局上下文。
2.3.1 binder_ioctl_write_read()
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
//把数据从用户空间拷贝到内核空间
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
// write_size>0,表示进程向驱动中写数据
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
if (ret < 0) {
bwr.read_consumed = 0;
//写入数据错误,把数据拷贝回用户空间
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
// read_size>0,表示进程从驱动中读数据
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
binder_inner_proc_lock(proc);
if (!binder_worklist_empty_ilocked(&proc->todo))
binder_wakeup_proc_ilocked(proc);
binder_inner_proc_unlock(proc);
if (ret < 0) {
// 读取数据错误,把数据拷贝回用户空间
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
向驱动写入数据或者读取数据。
2.3.2 binder_ioctl_set_ctx_mgr()
设置 serverManager为binder "大管家"。
三、驱动中涉及的结构体
3.1 binder_node
一个binder_node表示一个服务。加入一个进程有多个服务,那么proc中就会有多个binder_node。 binder_node中的最重要的字段当属ptr、cookies、proc。
3.2 binder_write_read
ioctl(bs->fd,BINDER_WRITE_READ,&bwr)
binder_write_read{
long write_buffer;
long write_size;
long read_buffer;
long read_size;
long read_consumed;
long write_consumed;
...
}
其中 write_buffer/read_buffer 指向了 writebuf结构体:
struct{
uint32_t cmd;
struct binder_transaction_data_txn;
} _attribute_ writebuf
3.3 binder_proc
binder_proc{
rb_root refs_by_desc; //存储了binder_refs链表
rb_root refs_by_node;//存储了binder_refs链表
rb_root nodes; //该进程所以的服务
rb_root threads; //所有的binder线程,红黑树。binder_thread 每个线程处理一个client
void *buffers;
list_head buffers;
list_head todo; //todo 链表
...
}
3.4 binder_ref
获取一个服务对应一个handle值(是一个整数值),类似于打开一个文件对应一个fd值。应用层传递过来的handle值,在内核中对应binder_ref结构体,表示对一个服务的引用。而一个服务是一个binder_node。
binder_ref {
binder_node *node; //对应某个服务
int32_t desc;// 整数值,对应handle值
...
}
binder_node{
binder_proc *proc;
user *ptr; //
user *cookies; //对应c++层的bnxxxService类,用来回调到c++层
}
内核会根据handle值来找到对应的binder_ref,进而找到binder_node服务。在通过binder_node找到binder_proc 目的进程。最后把数据放入todo链表中,唤醒目的进程,开始从内核读取数据。
四、驱动中具体过程总结
4.1 Server端注册服务
- 为服务创建binder_node:cookies指向native层的BnxxxService对象;proc指向server进程。
- 向serviceManager注册该binder_node。在内核中会创建binder_ref,node指向该binder_node,同时分配desc值(由注册的顺序决定..)。
- 回到serviceManager的用户态,在svcinfos服务链表中,加入一个svcinfo对象。
4.2 Client端获取服务
- 从serviceManager中查询name为xxx的服务。 serviceManager会从服务链表svcinfos中找到对应的svcinfo,返回handle给驱动的内核态。
- 驱动从在serviceManager的binder_proc结构体中,根据handle从refs_by_desc找到binder_ref,在从binder_ref中找到binder_node。
- 给client进程的binder_proc中,创建新的binder_ref,其中的node指向前面找到的binder_node,同时分配desc(由获取服务的顺序决定)。
- 驱动程序返回desc给client,也就是用户态的handle。
4.3 Client 向 Server发送数据
- client 构造数据,通过ioctl(handle)发送数据
- client 传入handle,进入内核。根据handle找到binder_ref,从中binder_node,在binder_node找到binder_proc server进程。
- 把数据传入server的todo链表中,唤醒server进程读取数据,client进入休眠。
- server进程被唤醒,从todo中取出数据,返回给用户空间
- server 处理数据
- server 把结果通过ioctl(handle)写回给client(本质上也是放入binder_proc的todo链表),server进入休眠
- client 从todo链表中读取数据,返回给用户空间。
4.4 关于数据的拷贝过程总结
4.4.1 对于binder_write_read
进行了两次拷贝。
- 从client用户态到内核态
- 从内核态到server的用户态
4.4.2 真正的数据
只进行了一次拷贝。
Binder 解析之 Parcel 理解
背景
在继续深入理解Binder机制前,我们很有必要对Parcel进行学习。
一、Parcel 为何物?
Parcel翻译过来是"包裹"的意思,其实就是个智能化数据容器。它提供了一种能力:将各种类型的数据或对象的引用在A进程中打包,经过Binder机制实现跨进程的传递,然后在B进程中解包出来。作为数据的载体,Parcel自动帮你完成打包、解压的过程。
Parcel 进程A打包的数据,和进程B得到数据是同一个份吗
-
如果打包的是数据本身,那么肯定不是。数据在内存中存储,A进程的内存空进和B进程的内存空进肯定不想通的。因此,数据或者引用肯定不是A进程的数据或引用,传入A进程的地址肯定不可行。
-
如果是同一个进程中使用Parcel,也会把数据Student先拆解,拷贝到Parcel的内存中,然后从parcel的内存中根据各个字段,再恢复创建另一个对象Student。再回收Parcel容器的内存。因此,同一个进程不建议使用parcel,内存浪费、效率低。
-
如果是不同进程,进程A把数据Student先拆解,拷贝到Parcel的内存中。然后再把Parcel内存中的数据拷贝到内核空间,释放Parcel内存。 进程B从内核空间直接读取数据,得到一个进程B中的parcel对象,从parcel对象中根据各个字段再恢复创建一个Student对象。此时,student对象就在B进程了。看起来好像是A进程的student对象传递到了进程B。
-
二、Parcel支持的传递数据类型
2.1 基本类型
private static native void nativeWriteByteArray(long nativePtr, byte[] b, int offset, int len);
private static native void nativeWriteBlob(long nativePtr, byte[] b, int offset, int len);
@FastNative
private static native void nativeWriteInt(long nativePtr, int val);
@FastNative
private static native void nativeWriteLong(long nativePtr, long val);
@FastNative
private static native void nativeWriteFloat(long nativePtr, float val);
@FastNative
private static native void nativeWriteDouble(long nativePtr, double val);
static native void nativeWriteString(long nativePtr, String val);
支持int、string、float、double等基本数据类型的读写。
2.2 Parcelables
/**
* Flatten the name of the class of the Parcelable and its contents
* into the parcel.
**/
public final void writeParcelable(Parcelable p, int parcelableFlags) {
if (p == null) {
writeString(null);
return;
}
writeParcelableCreator(p);
//writeToParcel()把自定义对象的数据写入parcel中
p.writeToParcel(this, parcelableFlags);
}
支持实现了parcelable接口的自定义对象的写入。如:intent、student等。
/**
* Read and return a new Parcelable from the parcel. The given class loader
* will be used to load any enclosed Parcelables. If it is null, the default
* class loader will be used.
*/
// 创建一个新的自定义对象
@SuppressWarnings("unchecked")
public final <T extends Parcelable> T readParcelable(ClassLoader loader) {
Parcelable.Creator<?> creator = readParcelableCreator(loader);
if (creator == null) {
return null;
}
if (creator instanceof Parcelable.ClassLoaderCreator<?>) {
Parcelable.ClassLoaderCreator<?> classLoaderCreator =
(Parcelable.ClassLoaderCreator<?>) creator;
return (T) classLoaderCreator.createFromParcel(this, loader);
}
//注意,这里得到的自定义对象跟写入的不是同一个了。
return (T) creator.createFromParcel(this);
}
创建并返回一个新的自定义对象。
2.3 Bundles
/**
* Flatten a Bundle into the parcel at the current dataPosition(),
* growing dataCapacity() if needed.
*/
public final void writeBundle(Bundle val) {
if (val == null) {
writeInt(-1);
return;
}
val.writeToParcel(this, 0);
}
/**
* Read and return a new Bundle object from the parcel at the current
* dataPosition(), using the given class loader to initialize the class
* loader of the Bundle for later retrieval of Parcelable objects.
* Returns null if the previously written Bundle object was null.
*/
public final Bundle readBundle(ClassLoader loader) {
int length = readInt();
if (length < 0) {
if (Bundle.DEBUG) Log.d(TAG, "null bundle: length=" + length);
return null;
}
final Bundle bundle = new Bundle(this, length);
if (loader != null) {
bundle.setClassLoader(loader);
}
return bundle;
}
支持Bundle对象的读写。
与parcelable有什么关系?
答: Bundle本质上就是一个parcelable对象。特点是封装了键值对的数据读写,一定程度上优化了读写效率,提升了性能。
2.4 Active object
什么是Active object?
答:我们一般存入到Parcel的是数据的本身,而Active object则是写入一个特殊的标志token,这个token引用了原数据对象。
当从Parcel中恢复这个对象时,我们可以不用重新实例化这个对象,而是通过得到一个handle值。通过handle值则可以直接操作原来需要写入的对象。
那么哪些对象属于Active object呢?
答: IBinder 对象和FileDescriptor 对象。
/**
* Write an object into the parcel at the current dataPosition(),
* growing dataCapacity() if needed.
*/
public final void writeStrongBinder(IBinder val) {
nativeWriteStrongBinder(mNativePtr, val);
}
/**
* Read an object from the parcel at the current dataPosition().
*/
public final IBinder readStrongBinder() {
return nativeReadStrongBinder(mNativePtr);
}
支持IBinder对象的读写。
/**
* Write a FileDescriptor into the parcel at the current dataPosition(),
* growing dataCapacity() if needed.
*
* <p class="caution">The file descriptor will not be closed, which may
* result in file descriptor leaks when objects are returned from Binder
* calls. Use {@link ParcelFileDescriptor#writeToParcel} instead, which
* accepts contextual flags and will close the original file descriptor
* if {@link Parcelable#PARCELABLE_WRITE_RETURN_VALUE} is set.</p>
*/
public final void writeFileDescriptor(FileDescriptor val) {
updateNativeSize(nativeWriteFileDescriptor(mNativePtr, val));
}
/**
* Read a FileDescriptor from the parcel at the current dataPosition().
*/
public final ParcelFileDescriptor readFileDescriptor() {
FileDescriptor fd = nativeReadFileDescriptor(mNativePtr);
return fd != null ? new ParcelFileDescriptor(fd) : null;
}
支持fd对象的读写。
2.5 Untyped container
支持java容器类的存取。如 如map、list等。
* {@link #writeArray(Object[])}, {@link #readArray(ClassLoader)},
* {@link #writeList(List)}, {@link #readList(List, ClassLoader)},
* {@link #readArrayList(ClassLoader)},
* {@link #writeMap(Map)}, {@link #readMap(Map, ClassLoader)},
* {@link #writeSparseArray(SparseArray)},
* {@link #readSparseArray(ClassLoader)}.
而以上接口的本质是通过循环集合,内部调用writeValue(Object) 和readValue(ClassLoader)来实现。 如:
public final void writeMap(Map val) {
writeMapInternal((Map<String, Object>) val);
}
/* package */ void writeMapInternal(Map<String,Object> val) {
if (val == null) {
writeInt(-1);
return;
}
Set<Map.Entry<String,Object>> entries = val.entrySet();
writeInt(entries.size());
for (Map.Entry<String,Object> e : entries) {
writeValue(e.getKey());
writeValue(e.getValue());
}
}
内部都是通过调用 writeValue():
public final void writeValue(Object v) {
if (v == null) {
writeInt(VAL_NULL);
} else if (v instanceof String) {
writeInt(VAL_STRING);
writeString((String) v);
} else if (v instanceof Integer) {
writeInt(VAL_INTEGER);
writeInt((Integer) v);
} else if (v instanceof Map) {
writeInt(VAL_MAP);
writeMap((Map) v);
} else if (v instanceof Bundle) {
// Must be before Parcelable
writeInt(VAL_BUNDLE);
writeBundle((Bundle) v);
} else if (v instanceof PersistableBundle) {
writeInt(VAL_PERSISTABLEBUNDLE);
writePersistableBundle((PersistableBundle) v);
} else if (v instanceof Parcelable) {
// IMPOTANT: cases for classes that implement Parcelable must
// come before the Parcelable case, so that their specific VAL_*
// types will be written.
writeInt(VAL_PARCELABLE);
writeParcelable((Parcelable) v, 0);
} else if (v instanceof Short) {
writeInt(VAL_SHORT);
writeInt(((Short) v).intValue());
} else if (v instanceof Long) {
writeInt(VAL_LONG);
writeLong((Long) v);
} else if (v instanceof Float) {
writeInt(VAL_FLOAT);
writeFloat((Float) v);
} else if (v instanceof Double) {
writeInt(VAL_DOUBLE);
writeDouble((Double) v);
} else if (v instanceof Boolean) {
writeInt(VAL_BOOLEAN);
writeInt((Boolean) v ? 1 : 0);
} else if (v instanceof CharSequence) {
// Must be after String
writeInt(VAL_CHARSEQUENCE);
writeCharSequence((CharSequence) v);
} else if (v instanceof List) {
writeInt(VAL_LIST);
writeList((List) v);
} else if (v instanceof SparseArray) {
writeInt(VAL_SPARSEARRAY);
writeSparseArray((SparseArray) v);
} else if (v instanceof boolean[]) {
writeInt(VAL_BOOLEANARRAY);
writeBooleanArray((boolean[]) v);
} else if (v instanceof byte[]) {
writeInt(VAL_BYTEARRAY);
writeByteArray((byte[]) v);
} else if (v instanceof String[]) {
writeInt(VAL_STRINGARRAY);
writeStringArray((String[]) v);
} else if (v instanceof CharSequence[]) {
// Must be after String[] and before Object[]
writeInt(VAL_CHARSEQUENCEARRAY);
writeCharSequenceArray((CharSequence[]) v);
} else if (v instanceof IBinder) {
writeInt(VAL_IBINDER);
writeStrongBinder((IBinder) v);
} else if (v instanceof Parcelable[]) {
writeInt(VAL_PARCELABLEARRAY);
writeParcelableArray((Parcelable[]) v, 0);
} else if (v instanceof int[]) {
writeInt(VAL_INTARRAY);
writeIntArray((int[]) v);
} else if (v instanceof long[]) {
writeInt(VAL_LONGARRAY);
writeLongArray((long[]) v);
} else if (v instanceof Byte) {
writeInt(VAL_BYTE);
writeInt((Byte) v);
} else if (v instanceof Size) {
writeInt(VAL_SIZE);
writeSize((Size) v);
} else if (v instanceof SizeF) {
writeInt(VAL_SIZEF);
writeSizeF((SizeF) v);
} else if (v instanceof double[]) {
writeInt(VAL_DOUBLEARRAY);
writeDoubleArray((double[]) v);
} else {
Class<?> clazz = v.getClass();
if (clazz.isArray() && clazz.getComponentType() == Object.class) {
// Only pure Object[] are written here, Other arrays of non-primitive types are
// handled by serialization as this does not record the component type.
writeInt(VAL_OBJECTARRAY);
writeArray((Object[]) v);
} else if (v instanceof Serializable) {
// Must be last
writeInt(VAL_SERIALIZABLE);
writeSerializable((Serializable) v);
} else {
throw new RuntimeException("Parcel: unable to marshal value " + v);
}
}
}
writeValue()内部定义了支持的object类型,根据不同类型调用不同接口来实现序列化。
三、Parcel 传递过程
3.1 一些疑问:
1. parcel初始化的时候,并没有分配内存,而是动态分配内存。那么分配内存所在空间是指? A进程空间?
答:是的,在进程A创建肯定是进程A的空间中。
2. 那么parcel有没有数据大小限制? 最大是多少?
答:有的,总大小是Integer最大值。跨进程通信报限制错误,是因为进程间缓冲区有大小限制导致。如1M-8k。
3. 读取数据的顺序必须要和写入数据的顺序一致,这样才能正确的获取的数据?
答:是的。因为Parcel会根据顺序读取。内部有一个位置指针。
3.2 Parcel的创建
3.2.1 obtain()
Parcel都是通过obtain()方法来获取对象的。
static protected final Parcel obtain(long obj) {
// 系统会缓存池(就是一个数组),大小为POOL_SIZE=6。
final Parcel[] pool = sHolderPool;
synchronized (pool) {
Parcel p;
for (int i=0; i<POOL_SIZE; i++) {
p = pool[i];
if (p != null) {
pool[i] = null; // 置空,表示已经被占用
if (DEBUG_RECYCLE) {
p.mStack = new RuntimeException();
}
p.init(obj);
return p;
}
}
}
//池中全部为空,没有可用的parcel,则创建一个新的parcel对象
return new Parcel(obj);
}
3.2.2 init()
Parcel的构造方法:
private Parcel(long nativePtr) {
if (DEBUG_RECYCLE) {
mStack = new RuntimeException();
}
//Log.i(TAG, "Initializing obj=0x" + Integer.toHexString(obj), mStack);
//初始化 nativePtr 表示是native层的 parcel 对象
init(nativePtr);
}
继续看init(nativePtr),其中nativePtr 表示是native层的 parcel 对象。
private void init(long nativePtr) {
if (nativePtr != 0) {
//没有native parcel的指针
mNativePtr = nativePtr;
mOwnsNativeParcelObject = false;
} else {
// 拥有native parcel的指针,走该分支
mNativePtr = nativeCreate();
mOwnsNativeParcelObject = true;
}
}
调用的是jni层:
// jni 方法
private static native long nativeCreate();
3.2.3 nativeCreate(native层)
继续看jni方法。
483 static jlong android_os_Parcel_create(JNIEnv* env, jclass clazz)
484 {
// 创建c++ parcel对象
485 Parcel* parcel = new Parcel();
// 强转为long值,返回引用给java层
486 return reinterpret_cast<jlong>(parcel);
487 }
3.2.4 reinterpret_cast
这个方法非常重要。可以把一个c++对象解释转换为一个long型的值。后续在根据这个long值再强转回为原来的c++的对象。因此,java层只要持有这个long型值,即可与c++层联系起来了。
继续看native层的 Parcel()对象:
3.2.4 Parcel::initState
352 Parcel::Parcel()
353 {
354 LOG_ALLOC("Parcel %p: constructing", this);
355 initState();
356 }
void Parcel::initState()
2913 {
2914 LOG_ALLOC("Parcel %p: initState", this);
2915 mError = NO_ERROR;
2916 mData = nullptr;
2917 mDataSize = 0;
2918 mDataCapacity = 0;
2919 mDataPos = 0;
2920 ALOGV("initState Setting data size of %p to %zu", this, mDataSize);
2921 ALOGV("initState Setting data pos of %p to %zu", this, mDataPos);
2922 mObjects = nullptr;
2923 mObjectsSize = 0;
2924 mObjectsCapacity = 0;
2925 mNextObjectHint = 0;
2926 mObjectsSorted = false;
2927 mHasFds = false;
2928 mFdsKnown = true;
2929 mAllowFds = true;
2930 mOwner = nullptr;
2931 mOpenAshmemSize = 0;
2932 mWorkSourceRequestHeaderPosition = 0;
2933 mRequestHeaderPresent = false;
2934
2935 // racing multiple init leads only to multiple identical write
2936 if (gMaxFds == 0) {
2937 struct rlimit result;
2938 if (!getrlimit(RLIMIT_NOFILE, &result)) {
2939 gMaxFds = (size_t)result.rlim_cur;
2940 //ALOGI("parcel fd limit set to %zu", gMaxFds);
2941 } else {
2942 ALOGW("Unable to getrlimit: %s", strerror(errno));
2943 gMaxFds = 1024;
2944 }
2945 }
2946 }
从以上可以看出,这里只是初始化了一些成员变量,如parcel的大小、容量、开始位置等信息。
注意,此时Parcel是没有分配内存的。Parcel是在存入数据的时候,动态分配内存的。
四、数据读写过程
4.1 基本数据的写
以 writeFloat()和readFloat()为例。
4.1.1 nativeWriteFloat()
public final void writeFloat(float val) {
nativeWriteFloat(mNativePtr, val);
}
传入nativePtr指针,调用的是jni方法,那我们看看native层的方法:
static void android_os_Parcel_writeFloat(JNIEnv* env, jclass clazz, jlong nativePtr, jfloat val)
255 {
// 根据java层的指针强转为c++层的Parcel对象
256 Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
257 if (parcel != NULL) {
//
258 const status_t err = parcel->writeFloat(val);
259 if (err != NO_ERROR) {
260 signalExceptionForError(env, clazz, err);
261 }
262 }
263 }
继续看Parcel的 writeFloat():
4.1.2 writeFloat()
status_t Parcel::writeFloat(float val)
1060 {
1061 return writeAligned(val);
1062 }
1063
template<class T>
1680 status_t Parcel::writeAligned(T val) {
1681 COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
1682 //如果在当前的位置mDataPos+插入值val的大小,还没有超过parcel的容量,那么直接插入val
1683 if ((mDataPos+sizeof(val)) <= mDataCapacity) {
1684 restart_write: // 在当前位置插入val
1685 *reinterpret_cast<T*>(mData+mDataPos) = val;
//完成插入,更新mDataPos位置。结束
1686 return finishWrite(sizeof(val));
1687 }
1688 //如果超过容量,则自动扩容
1689 status_t err = growData(sizeof(val));
//扩容成功,再次把val值插入到parcel中
1690 if (err == NO_ERROR) goto restart_write;
1691 return err;
1692 }
1693
4.1.3 growData()
status_t Parcel::growData(size_t len)
2681 {
2682 if (len > INT32_MAX) {
2683 // don't accept size_t values which may have come from an
2684 // inadvertent conversion from a negative int.
2685 return BAD_VALUE;
2686 }
2687
2688 size_t newSize = ((mDataSize+len)*3)/2; //1.5 倍扩容
2689 return (newSize <= mDataSize)
2690 ? (status_t) NO_MEMORY
2691 : continueWrite(newSize);
2692 }
4.1.4 continueWrite()
...
// This is the first data. Easy!
//调用malloc函数,分配内存
2885 uint8_t* data = (uint8_t*)malloc(desired);
2886 if (!data) {
2887 mError = NO_MEMORY;
2888 return NO_MEMORY;
2889 }
2890
2891 if(!(mDataCapacity == 0 && mObjects == nullptr
2892 && mObjectsCapacity == 0)) {
2893 ALOGE("continueWrite: %zu/%p/%zu/%zu", mDataCapacity, mObjects, mObjectsCapacity, desired);
2894 }
2895
2896 LOG_ALLOC("Parcel %p: allocating with %zu capacity", this, desired);
2897 pthread_mutex_lock(&gParcelGlobalAllocSizeLock);
2898 gParcelGlobalAllocSize += desired;
2899 gParcelGlobalAllocCount++;
2900 pthread_mutex_unlock(&gParcelGlobalAllocSizeLock);
2901
2902 mData = data;
2903 mDataSize = mDataPos = 0;
2904 ALOGV("continueWrite Setting data size of %p to %zu", this, mDataSize);
2905 ALOGV("continueWrite Setting data pos of %p to %zu", this, mDataPos);
2906 mDataCapacity = desired;
2907 }
可以发现,内部是通过malloc()函数完成内存分配的。至此,完成了数据的写入操作。
那数据是如何读取的呢?
4.2 基本数据的读过程
4.2.1 nativeReadFloat()
private static native float nativeReadFloat(long nativePtr);
static jfloat android_os_Parcel_readFloat(jlong nativePtr)
430 { //同理,根据long值,得到parcel对象
431 Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
432 if (parcel != NULL) {
433 return parcel->readFloat();
434 }
435 return 0;
436 }
看parcel的 readFloat():
float Parcel::readFloat() const
1953 {
1954 return readAligned<float>();
1955 }
4.2.2 readAligned()
status_t Parcel::readAligned(T *pArg) const {
1648 COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
1649
1650 if ((mDataPos+sizeof(T)) <= mDataSize) {
1651 if (mObjectsSize > 0) {
从当前位置读取一个float类型的数据
1652 status_t err = validateReadData(mDataPos + sizeof(T));
1653 if(err != NO_ERROR) {
1654 // Still increment the data position by the expected length
1655 mDataPos += sizeof(T);
1656 return err;
1657 }
1658 }
1659
1660 const void* data = mData+mDataPos;
1661 mDataPos += sizeof(T);
1662 *pArg = *reinterpret_cast<const T*>(data);
1663 return NO_ERROR;
1664 } else {
1665 return NOT_ENOUGH_DATA;
1666 }
1667 }
内部会根据插入的顺序,根据前位置mDataPos和 数据大小,读取一个float类型的数据。
注意,读取数据的顺序和插入数据的顺序必须一致,否则会读取失败。
4.3 Ative Object对象的写过程
4.3.1 nativeWriteStrongBinder()
static void android_os_Parcel_writeStrongBinder(JNIEnv* env, jclass clazz, jlong nativePtr, jobject object)
299 {
300 Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
301 if (parcel != NULL) {
302 const status_t err = parcel->writeStrongBinder(ibinderForJavaObject(env, object));
303 if (err != NO_ERROR) {
304 signalExceptionForError(env, clazz, err);
305 }
306 }
307 }
4.3.2 ibinderForJavaObject()
sp<IBinder> ibinderForJavaObject(JNIEnv* env, jobject obj)
707 {
708 if (obj == NULL) return NULL;
709
710 // Instance of Binder?
711 if (env->IsInstanceOf(obj, gBinderOffsets.mClass)) {
712 JavaBBinderHolder* jbh = (JavaBBinderHolder*)
713 env->GetLongField(obj, gBinderOffsets.mObject);
714 return jbh->get(env, obj);
715 }
716
717 // Instance of BinderProxy?
718 if (env->IsInstanceOf(obj, gBinderProxyOffsets.mClass)) {
719 return getBPNativeData(env, obj)->mObject;
720 }
721
722 ALOGW("ibinderForJavaObject: %p is not a Binder object", obj);
723 return NULL;
724 }
根据java的binder对象得到native层对应的binder对象:
- 如果是
Binder.java对象(一般为服务端的xxxservice.java),那么就得到一个JavaBBinder.cpp对象,其实就是BBinder对象。 - 如果是
BinderProxy.java对象,那么就得到BpBinder.cpp对象。
4.3.3 writeStrongBinder()
传入的是一个IBinder 对象。
status_t Parcel::writeStrongBinder(const sp<IBinder>& val)
1135 { // val是binder对象, this是parcel对象,此时为写入
1136 return flatten_binder(ProcessState::self(), val, this);
1137 }
1138
status_t flatten_binder(const sp<ProcessState>& /*proc*/,
205 const sp<IBinder>& binder, Parcel* out)
206 {
207 flat_binder_object obj; // 构造无障碍 flat_binder_object对象
208
209 if (IPCThreadState::self()->backgroundSchedulingDisabled()) {
210 /* minimum priority for all nodes is nice 0 */
211 obj.flags = FLAT_BINDER_FLAG_ACCEPTS_FDS;
212 } else {
213 /* minimum priority for all nodes is MAX_NICE(19) */
214 obj.flags = 0x13 | FLAT_BINDER_FLAG_ACCEPTS_FDS;
215 }
216
217 if (binder != nullptr) {
218 BBinder *local = binder->localBinder();
219 if (!local) {
//不是本地的binder,那么使用远端binder的代理
220 BpBinder *proxy = binder->remoteBinder();
221 if (proxy == nullptr) {
222 ALOGE("null proxy");
223 }
224 const int32_t handle = proxy ? proxy->handle() : 0;
225 obj.hdr.type = BINDER_TYPE_HANDLE; //存入类型为handle
226 obj.binder = 0; /* Don't pass uninitialized stack data to a remote process */
227 obj.handle = handle; //存入handle值
228 obj.cookie = 0;
229 } else {
//本地binder,存入
230 if (local->isRequestingSid()) {
231 obj.flags |= FLAT_BINDER_FLAG_TXN_SECURITY_CTX;
232 }
233 obj.hdr.type = BINDER_TYPE_BINDER; // 类型为binder
234 obj.binder = reinterpret_cast<uintptr_t>(local->getWeakRefs()); //存入弱引用
// 把本地的binder对象存入到obj的cookies中
235 obj.cookie = reinterpret_cast<uintptr_t>(local);
236 }
237 } else {
238 obj.hdr.type = BINDER_TYPE_BINDER;
239 obj.binder = 0;
240 obj.cookie = 0;
241 }
242
243 return finish_flatten_binder(binder, obj, out);
244 }
245
4.3.4 finish_flatten_binder()
inline static status_t finish_flatten_binder(
199 const sp<IBinder>& /*binder*/, const flat_binder_object& flat, Parcel* out)
200 {
201 return out->writeObject(flat, false);
202 }
费劲心思把IBinder对象转换成了flat_binder_object对象,直接写入到parcel中:
4.3.5 writeObject()
status_t Parcel::writeObject(const flat_binder_object& val, bool nullMetaData)
1371 {
1372 const bool enoughData = (mDataPos+sizeof(val)) <= mDataCapacity;
1373 const bool enoughObjects = mObjectsSize < mObjectsCapacity;
1374 if (enoughData && enoughObjects) { //如果parcel中内存足够,则直接存入
//存入val: flat_binder_object
1375 restart_write:
1376 *reinterpret_cast<flat_binder_object*>(mData+mDataPos) = val;
1377
1378 // remember if it's a file descriptor
1379 if (val.hdr.type == BINDER_TYPE_FD) {
1380 if (!mAllowFds) {
1381 // fail before modifying our object index
1382 return FDS_NOT_ALLOWED;
1383 }
1384 mHasFds = mFdsKnown = true;
1385 }
1386
1387 // Need to write meta-data?
1388 if (nullMetaData || val.binder != 0) {
1389 mObjects[mObjectsSize] = mDataPos;
1390 acquire_object(ProcessState::self(), val, this, &mOpenAshmemSize);
1391 mObjectsSize++;
1392 }
1393
1394 return finishWrite(sizeof(flat_binder_object));
1395 }
1396
1397 if (!enoughData) {
//如果parcel中内存不够,则扩容
1398 const status_t err = growData(sizeof(val));
1399 if (err != NO_ERROR) return err;
1400 }
1401 if (!enoughObjects) {
1402 size_t newSize = ((mObjectsSize+2)*3)/2;
1403 if (newSize*sizeof(binder_size_t) < mObjectsSize) return NO_MEMORY; // overflow //溢出
1404 binder_size_t* objects = (binder_size_t*)realloc(mObjects, newSize*sizeof(binder_size_t));
1405 if (objects == nullptr) return NO_MEMORY;
1406 mObjects = objects;
1407 mObjectsCapacity = newSize;
1408 }
1409
1410 goto restart_write; // 扩容后,继续写入
1411 }
1412
至此,我们把一个binder对象转换成了一个flat_binder_object的对象,写入到parcel中(而不是直接写入binder对象本身)。
binder对象的读取过程:
4.4 Ative Object对象的读过程
4.4.1 nativeReadStrongBinder()
private static native IBinder nativeReadStrongBinder(long nativePtr);
static jobject android_os_Parcel_readStrongBinder(JNIEnv* env, jclass clazz, jlong nativePtr)
462 {
463 Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
464 if (parcel != NULL) {
465 return javaObjectForIBinder(env, parcel->readStrongBinder());
466 }
467 return NULL;
468 }
469
4.4.2 parcel->readStrongBinder()
sp<IBinder> Parcel::readStrongBinder() const
2214 {
2215 sp<IBinder> val;
2216 // Note that a lot of code in Android reads binders by hand with this
2217 // method, and that code has historically been ok with getting nullptr
2218 // back (while ignoring error codes).
2219 readNullableStrongBinder(&val);
2220 return val;
2221 }
4.4.3 unflatten_binder()
status_t Parcel::readNullableStrongBinder(sp<IBinder>* val) const
2209 {
2210 return unflatten_binder(ProcessState::self(), *this, val);
2211 }
status_t unflatten_binder(const sp<ProcessState>& proc,
303 const Parcel& in, sp<IBinder>* out)
304 {// 从parcel中获得 flat_binder_object 对象
305 const flat_binder_object* flat = in.readObject(false);
306
307 if (flat) {
308 switch (flat->hdr.type) {
309 case BINDER_TYPE_BINDER:
//从cookies中强转回得到一个IBinder对象
310 *out = reinterpret_cast<IBinder*>(flat->cookie);
311 return finish_unflatten_binder(nullptr, *flat, in);
312 case BINDER_TYPE_HANDLE:
//从flat的handle得到一个 IBinder代理
313 *out = proc->getStrongProxyForHandle(flat->handle);
314 return finish_unflatten_binder(
315 static_cast<BpBinder*>(out->get()), *flat, in);
316 }
317 }
318 return BAD_TYPE;
319 }
此时,由于是客户端从SM中获取服务端的Service代理对象,因此走的是BINDER_TYPE_HANDLE分支。得到一个BpBinder对象。具体过程,可参考getService流程。
4.4.4 readObject()
const flat_binder_object* Parcel::readObject(bool nullMetaData) const
2460 {
2461 const size_t DPOS = mDataPos;
2462 if ((DPOS+sizeof(flat_binder_object)) <= mDataSize) {
// 从parcel当前位置,强转得到一个flat 对象:obj
2463 const flat_binder_object* obj
2464 = reinterpret_cast<const flat_binder_object*>(mData+DPOS);
2465 mDataPos = DPOS + sizeof(flat_binder_object);
2466 if (!nullMetaData && (obj->cookie == 0 && obj->binder == 0)) {
2467 // When transferring a NULL object, we don't write it into
2468 // the object list, so we don't want to check for it when
2469 // reading.
2470 ALOGV("readObject Setting data pos of %p to %zu", this, mDataPos);
2471 return obj;
2472 }
2473
2474 ...
2517 return nullptr;
2518 }
4.4.5 proc->getStrongProxyForHandle()
sp<IBinder> ProcessState::getStrongProxyForHandle(int32_t handle)
260 {
261 sp<IBinder> result;
262
263 AutoMutex _l(mLock);
264
265 handle_entry* e = lookupHandleLocked(handle);
266
267 if (e != nullptr) {
268 // We need to create a new BpBinder if there isn't currently one, OR we
269 // are unable to acquire a weak reference on this current one. See comment
270 // in getWeakProxyForHandle() for more info about this.
271 IBinder* b = e->binder;
272 if (b == nullptr || !e->refs->attemptIncWeak(this)) {
273 ...
300 b = BpBinder::create(handle);
301 e->binder = b;
302 if (b) e->refs = b->getWeakRefs();
303 result = b;
304 } else {
305 // This little bit of nastyness is to allow us to add a primary
306 // reference to the remote proxy when this team doesn't have one
307 // but another team is sending the handle to us.
308 result.force_set(b);
309 e->refs->decWeak(this);
310 }
311 }
312
313 return result;
314 }
根据handle 创建一个bpBinder对象。
4.4.6 finish_unflatten_binder()
inline static status_t finish_unflatten_binder(
296 BpBinder* /*proxy*/, const flat_binder_object& /*flat*/,
297 const Parcel& /*in*/)
298 {
299 return NO_ERROR;
300 }
这里,啥事都没做,直接返回code。
4.4.7 javaObjectForIBinder()
jobject javaObjectForIBinder(JNIEnv* env, const sp<IBinder>& val)
666 {
667 if (val == NULL) return NULL;
668
669 if (val->checkSubclass(&gBinderOffsets)) {
670 // It's a JavaBBinder created by ibinderForJavaObject. Already has Java object.
671 jobject object = static_cast<JavaBBinder*>(val.get())->object();
672 LOGDEATH("objectForBinder %p: it's our own %p!\n", val.get(), object);
673 return object;
674 }
675
676 BinderProxyNativeData* nativeData = new BinderProxyNativeData();
677 nativeData->mOrgue = new DeathRecipientList;
678 nativeData->mObject = val;
679 //通过反射,构造了BinderProxy.java类,其中的nativeData指向了BpBinder.cpp对象
680 jobject object = env->CallStaticObjectMethod(gBinderProxyOffsets.mClass,
681 gBinderProxyOffsets.mGetInstance, (jlong) nativeData, (jlong) val.get());
682 if (env->ExceptionCheck()) {
683 // In the exception case, getInstance still took ownership of nativeData.
684 return NULL;
685 }
686 BinderProxyNativeData* actualNativeData = getBPNativeData(env, object);
687 if (actualNativeData == nativeData) {
688 // Created a new Proxy
689 uint32_t numProxies = gNumProxies.fetch_add(1, std::memory_order_relaxed);
690 uint32_t numLastWarned = gProxiesWarned.load(std::memory_order_relaxed);
691 if (numProxies >= numLastWarned + PROXY_WARN_INTERVAL) {
692 // Multiple threads can get here, make sure only one of them gets to
693 // update the warn counter.
694 if (gProxiesWarned.compare_exchange_strong(numLastWarned,
695 numLastWarned + PROXY_WARN_INTERVAL, std::memory_order_relaxed)) {
696 ALOGW("Unexpectedly many live BinderProxies: %d\n", numProxies);
697 }
698 }
699 } else {
700 delete nativeData;
701 }
702
703 return object;
704 }
通过反射,构造了BinderProxy.java对象,其中的nativeData成员指向了BpBinder.cpp对象。至此,java层就得到一个IBinder对象。
4.5 总结
经过以上的分析,我们有了一个基本的认识,不管什么类型的数据,我们通过parcel提供的接口就能轻松实现数据的序列化和反序列化。而这种序列化的过程是基于内存的。
五、Parcel与Serializable区别
Parcel:
- 基于内存中的序列化
- 把对象拆解,再组装,效率更高
- 不适合序列化到文件和网络
- 对写入数据的和读取数据有顺序要一致,否则会失败
- 一般情况下用于跨进程,当然也可以在同一个进程(
不推荐)
Serializable:
- 基于网络、文件的序列化。 直接转成二进制,占用内存小。
- 当然也可以基于内存,不过有缺点:但是临时变量多,内存碎片化,导致频繁gc

















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









