



一、引言
为什么同样是做 RAG,有的效果拔群,有的却差强人意?分块(Chunking)策略可能是那个被你忽略的关键环节。
什么是Chunk?
AI中的分块是指将大型文档分割成称为“chunk”的较小片段。这些片段可以是段落、句子、词组或受token限制的片段,这使得模型能更轻松地仅搜索和检索所需内容。这种分块技术对于优化检索增强生成(RAG)的性能至关重要。
为什么在RAG中需要Chunk?
在RAG中,检索到正确的信息是关键,但当知识库非常庞大,可能包含数百万字或文档时,使用有效的RAG分块技术对于从这类大型数据集中高效检索相关信息,就变得至关重要了。举个例子,你有一个服务QPS达到千万级还要在30ms内返回结果,这时一定会搞一组本地缓存的集群。把你的数据按规则初始化到缓存里,就是对应的RAG的Chunk操作。
Chunk也是RAG ETL Pipeline中Transform环节的核心组件之一,可以比喻成我们切蛋糕,在切之前就已经想好要分几块了。让我看看“切蛋糕🍰”有几种手法。
二、主流RAG的分块策略详解
2.1.固定大小分块策略
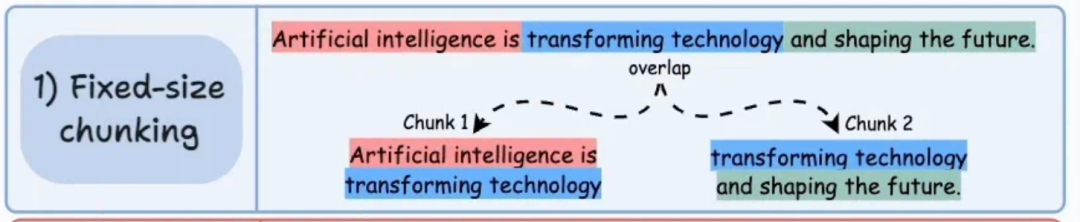
- 核心思想:根据预定义的字符数或 token 数将文本分成统一的块。
- 工作方式:例如,固定每块 500 tokens。引入 “重叠区”(Overlap)来缓解上下文断裂问题。
- 优点:实现简单,处理速度快,不依赖复杂模型。
- 缺点:可能破坏语义完整性(如拆分句子或段落),对结构差异大的文档适应性差。
2.2.语义分块策略
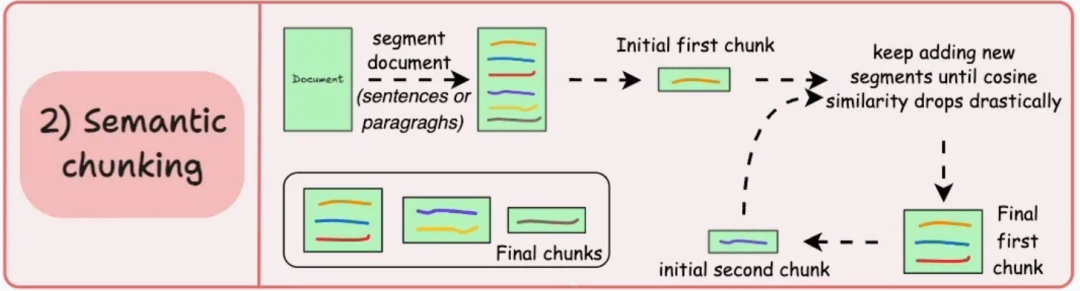
- 核心思想:根据文本的语义相似度而非物理结构进行分块,确保每个 Chunk 内部主题高度相关。
- 工作方式:通常通过计算句子 Embedding 的余弦相似度,当相似度低于某个阈值时进行分割。
- 优点:能创建逻辑上最连贯的 Chunk,对后续检索和生成质量提升显著。特别适用于处理主题跳跃较多的文档。
- 缺点:计算成本高(需要调用 Embedding 模型),处理速度较慢。
2.3.基于递归分块策略
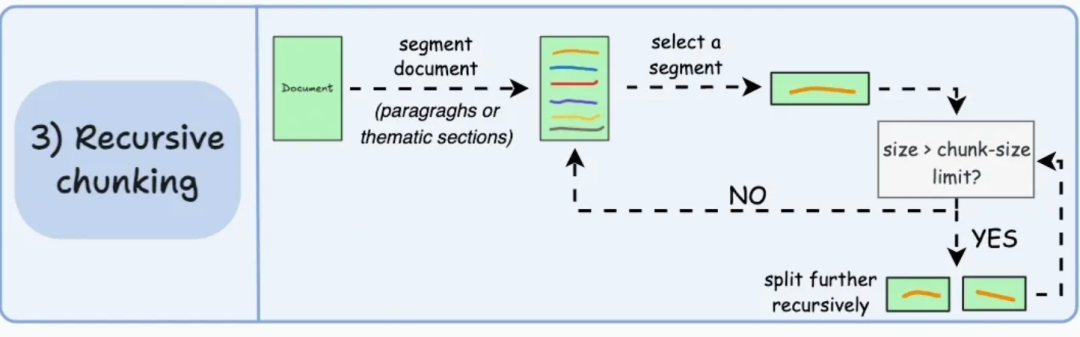
- 核心思想:一种更智能的组合式策略,按优先级顺序尝试多种分隔符进行递归分割。
- 工作方式:例如,优先按段落分割,如果段落仍过大,再按句子分割,最后才按字符数强制分割。
- 优点:尽可能保留高级别的语义结构(段落 > 句子 > ...),适应性强,能处理多种类型文档。
- 缺点:实现稍复杂,性能开销高于纯固定大小分块。
2.4.基于文档的分块策略
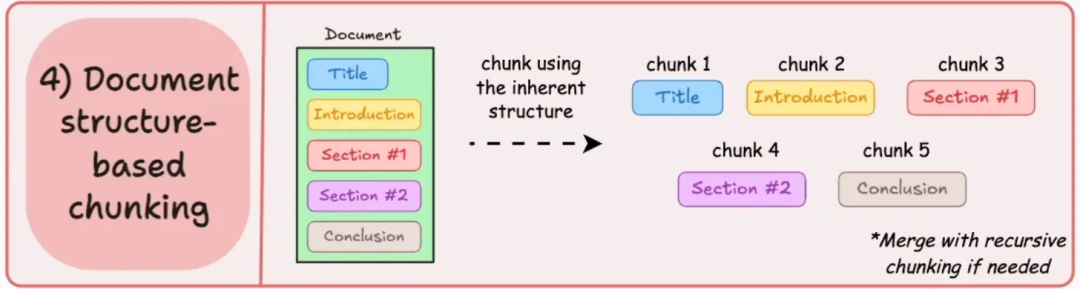
- 核心思想:利用文档本身的元数据和结构信息(如标题层级、表格、图片说明、PDF 页码等)进行智能分割。
- 工作方式:例如,将一个一级标题下的所有内容(包括子标题和段落)作为一个大 Chunk,或者将每个表格单独作为一个 Chunk。
- 优点:完美贴合特定类型文档(如法律合同、学术论文、报告)的逻辑结构,信息组织性强。
- 缺点:依赖高质量的文档解析和结构识别,通用性相对较弱。
2.5.智能体分块策略

- 核心思想:这是一种更前沿的动态策略,根据 Agent 将要执行的具体任务或目标来决定如何分块。
- 工作方式:Agent 会先理解任务,然后自适应地从文档中提取和组织最相关的信息块。例如,任务是 “总结”,则可能提取关键论点;任务是 “回答特定问题”,则可能精准定位相关证据。
- 优点:灵活性和针对性极高,能最大化任务效果。
- 缺点:实现复杂,通常需要强大的规划和推理能力,目前还不普及。
2.6.基于句子的分块策略
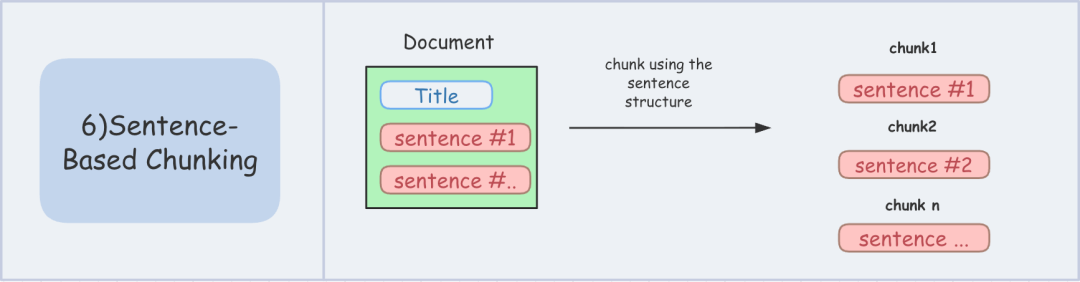
- 核心思想:将文本分割成完整的句子,确保每个 Chunk 都包含一个或多个完整的思想。
- 工作方式:使用 NLP 工具(如 NLTK, SpaCy)识别句子边界,然后可以将几个连续的句子组合成一个 Chunk。
- 优点:保证了基本的语义单元完整,避免了 “半句话” 的问题。
- 缺点:句子长度差异仍可能导致 Chunk 大小不均;多个句子组合时,如何确定最佳组合仍需策略。
2.7.基于段落的分块策略
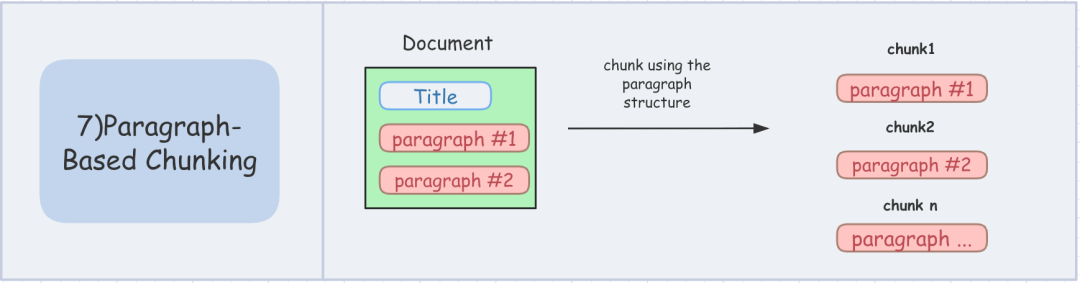
- 核心思想:基于段落的分块,通过提示符截取,将整个文本划分成多个段落。这种方式同样适合结构清晰的文档。
- 工作方式:例如,保险条款、法律、论文、AB实验报告等文档。
- 优点:优点自然分段,语义完整。
- 缺点:缺点自然是段落长度不一,可能超token限制。
其他
除以上7种外,还有很多大神们总结的切块方法论,如按照token、按照层级,按照excel sheet页,按照pdf页码等。都是针对特定场景。下面我结合实战和中文的切块的方法论做一下总结。
三、分块策略的选择与实战优化
3.1. 没有“万能”的分块策略
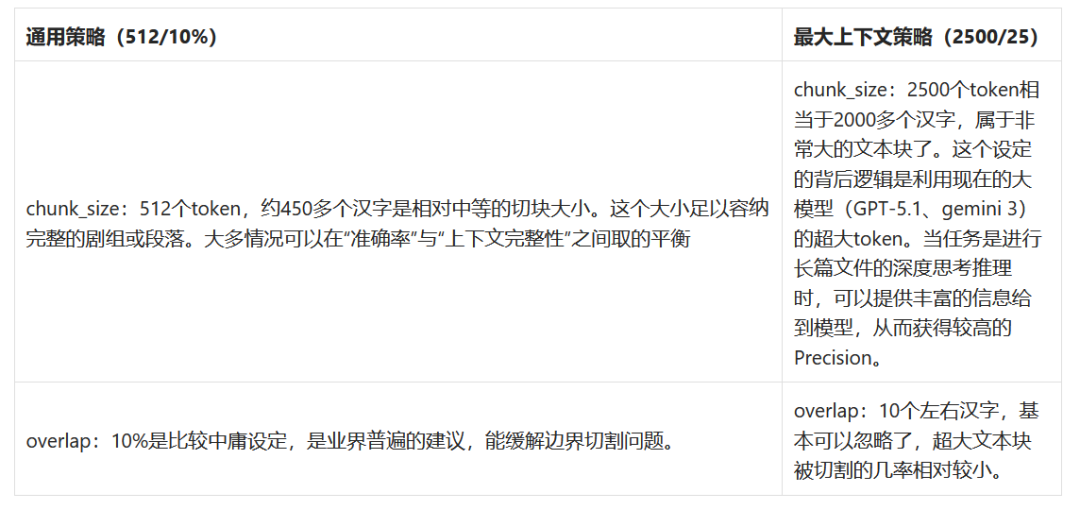
现实中不存在一种“one-for-all” 的数据读取和分块方法,特别像是 PDF 和 Word 这类复杂格式的文档。比较流行的方案是实用DeepDoc(OCR、TSR、DLR),所以实际中应根据业务,制作不同的模板。那么评估Chunk的参数和指标有哪些呢? 指标就是Precision和Recall,详细看表格:

Chunk参数与指标,我设计了两套策略:512/10%和2500/25 (单位token)
3.2.Chunk策略的选择
我的方法论:段落分块(Paragraph Chunking),句子分块(Semantic Chunking),递归分块(Recursive Chunking),语义分块(Semantic Chunking)。
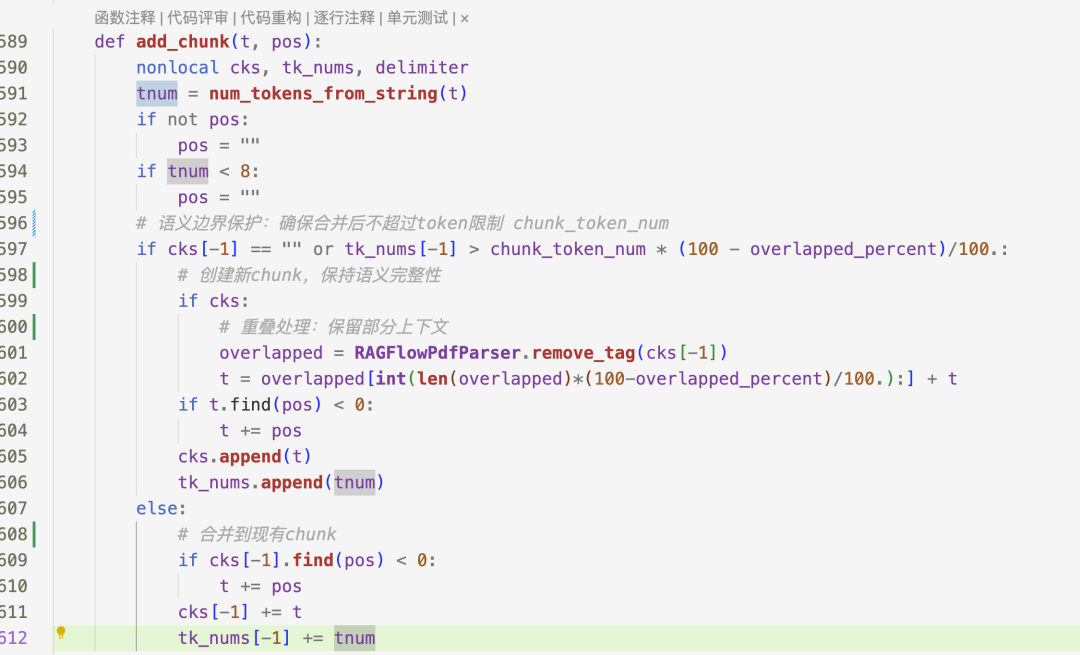
现在的RAG框架基本都是基于段落或句子来分块,也都都支持(\n。;!?)的递归分块。那从运营用户角度出发,或者第一次切的时候,如何傻瓜式操作呢?RAGFlow交出了一份方案,看一下它的分块核心算法
四、方法论总结
如何开始?可以从512 tokens 搭配 10-15%的重叠率开始。
如何优化?调试参数,多使用递归分块和句子分块,语义分块还是不够优秀。
如何测评?上号 chunking_evaluation
有和方法论? 上号 CRUD-RAG 论文指出对于创意生成和保持文章连贯性的任务,切分较大的块表现会更佳。我们在
RAGas实验也得到了相同的答案。
好了,以上是我们的实践总结,希望能帮到大家。



















 342
342


 到【灌水乐园】发言
到【灌水乐园】发言








