 MySQL索引下推原理、场景与示例
MySQL索引下推原理、场景与示例




索引下推
索引下推的工作原理
- 传统查询流程:
- 存储引擎根据索引查找数据。
- 将所有符合索引条件的数据返回给服务器层。
- 服务器层根据其他条件(如
WHERE子句)进一步过滤数据。
- 索引下推优化后的流程:
- 存储引擎根据索引查找数据。
- 在索引查找时,直接应用过滤条件(如
WHERE子句)。 - 只返回满足所有条件的数据给服务器层。
索引下推的适用场景
- 非聚簇索引:索引下推主要用于非聚簇索引,因为非聚簇索引的叶子节点存储的是指向数据行的指针,而不是数据行本身。
- 复合索引:当查询条件涉及复合索引的多个列时,索引下推可以显著减少需要扫描的数据量。
- 范围查询:对于范围查询(如
BETWEEN、>、<等),索引下推可以减少需要读取的数据行数。
索引下推的示例
-
假设有一张表
user,包含以下列:id(主键)、name、age、city。 -
创建一个复合索引:
CREATE INDEX idx_name_age ON user(name, age); -
查询语句:
SELECT * FROM user WHERE name like '张%' AND age =18; -
传统查询流程:
- 存储引擎根据索引
idx_name_age查找所有name like '张%'的数据。 - 将所有
name like '张%'的数据返回给服务器层。 - 服务器层根据
age =18进一步过滤数据。
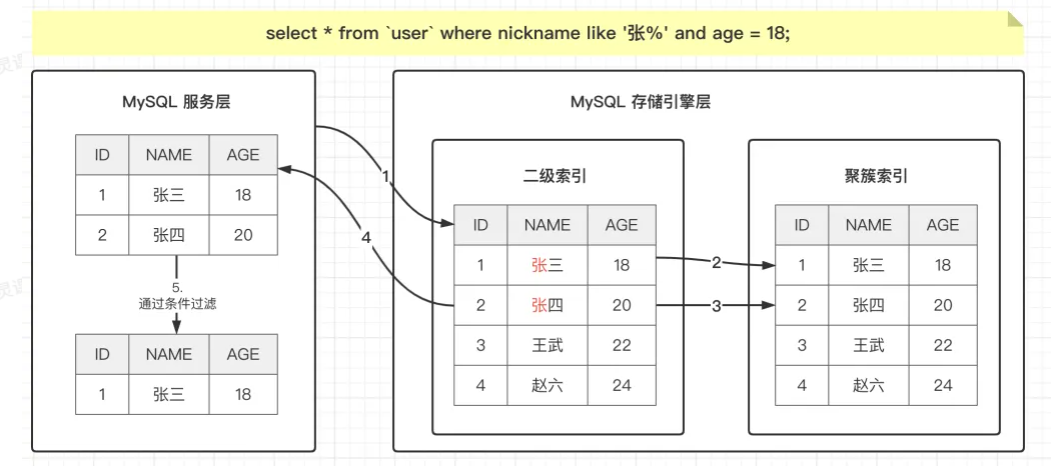
- 存储引擎根据索引
-
索引下推优化后的流程:
-
存储引擎根据索引
idx_name_age查找所有name like '张%'的数据。 -
在索引查找时,直接应用
age=18的条件。 -
只返回
name like '张%'且age =18的数据给服务器层。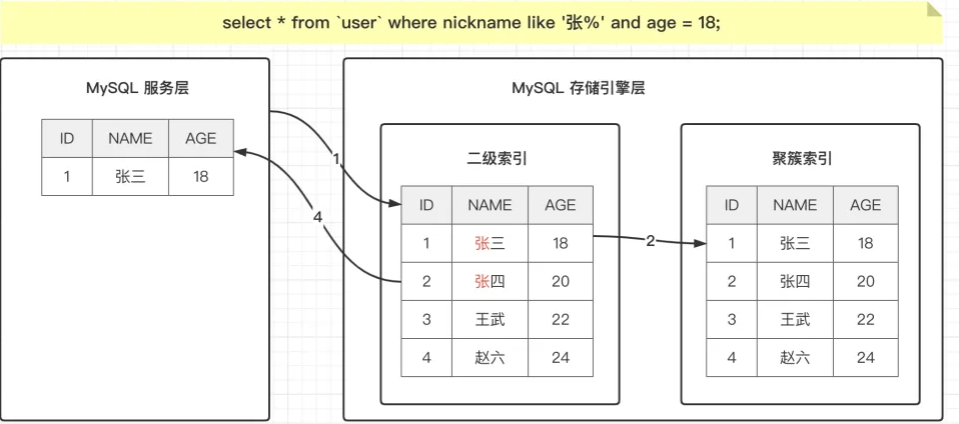
-



















 1165
1165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











