



-
学习更多可点击推文合集:代码分享。
-
合集会包含免费教程和付费教程,免费教程资料会直接发到资料分享群里,完全免费,需要的可以扫码进群,失效可直接联系我。
-
付费教程可按单篇付费,也可直接联系我按年付费,2025年份目前定价为200,随着付费课程的增加费用会越来越高,且群内成员我开发的R包和后续课程可打8折。
-
后续计划更新的内容很多,可以查看推文:生信摆渡推文课程更新计划,附资料领取群。

-
关注不迷路, 添加星标, 最新教程抢先看!
-

前言
-
首先,这个R包是来源于余光创老师的R包fanyi,Github:https://github.com/YuLab-SMU/fanyi。
-
由于目前的功能还比较基础,相当于只简单打了个地基,但是地基打好了楼就随便你怎么盖了。
-
所以,跟据我的使用经验,优化和增加了一些非常使用的函数。
前期准备
安装
- R包fanyi安装很简单。
if(!require("fanyi")) install.packages("fanyi")
library(fanyi)
Loading required package: fanyi
Warning message:
"package 'fanyi' was built under R version 4.4.2"
If you use fanyi in published research, please cite:
Guangchuang Yu. Using fanyi to assist research communities in retrieving and interpreting information. bioRxiv 2023, doi: 10.1101/2023.12.21.572729
```
- 安装 fanyi2
```R
# 本地安装
file_pkgs = grep("^fanyi2.*\\.gz$", dir(), value = TRUE)
install.packages(file_pkgs, repos = NULL, upgrade = FALSE, force = TRUE)
library(fanyi2)
Loading required package: fastR
Attaching package: 'fanyi2'
The following objects are masked from 'package:fastR':
gene_summary2, merge_strings, translate2
配置翻译服务
-
配置翻译服务可能有点麻烦,不过操作下来也还好。
-
这里推荐百度翻译,虽然没有对比,但是感觉挺便宜的,目前翻译了26万字符也才花了5块钱😂。
-
看通知好像每月有5万的免费额度,已经足够用了。
- 参考配置步骤:
- go to https://fanyi-api.baidu.com/manage/developer and regist as an individual developer
- get
appidandkey(密钥) - set
appidandkeywithsource = "baidu"usingset_translate_option() - have fun with
baidu_translate()
添加默认配置
- 获取
appid和key后就能设置配置了,如上面的步骤所示进行设置:
# fanyi::set_translate_option(appid = "20250118XXXXXXXX", key = "II_MRM6yQMjXXXXXXXX", source = "baidu")
-
参数是假的, 所以我先注释掉了, 自己用的时候要取消注释并参数值替换成自己的
-
代码中的
appid和key替换成你自己的就行了,每次使用之前需要运行一下这行代码。 -
当然如果把这行代码放到默认配置文件里就不用每次再运行了,R包一加载就能用了。
-
添加默认配置可参考教程:【Rprofile – 自定义你的R启动方式】:https://www.jianshu.com/p/6777edf1cc98
使用和优化
translate
- 原版函数
- 通用翻译函数
- 默认英译中
- 默认调用 set_translate_option 中设置的翻译服务
Sys.sleep(2)
translate("Description of R package fanyi: Translate Words or Sentences via Online Translators.")
‘R包fanyi的描述:通过在线翻译器翻译单词或句子。’
translate('R包fanyi的描述:通过在线翻译器翻译单词或句子。', from = "zh", to = "en")
‘Description of R package fanyi: Translate words or sentences through an online translator.’
cn2en 和 en2cn
- 原版函数
- 也有两个中英文互译的专有函数:
cn2en和en2cn
cn2en("Description of R package fanyi: Translate Words or Sentences via Online Translators.")
‘Description of R package fanyi: Translate Words or Sentences via Online Translators.’
en2cn('R包fanyi的描述:通过在线翻译器翻译单词或句子。')
‘R包fanyi的描述:通过在线翻译器翻译单词或句子。’
gene_summary
- 原版函数
- 提供基因ID(必须是ENTREZID),返回基因名、基因名全称、基因描述信息
- 可以很方便的获取基因信息
print(gene_summary(c('7157', '1956', '915')))
uid name description
TP53 7157 TP53 tumor protein p53
EGFR 1956 EGFR epidermal growth factor receptor
CD3D 915 CD3D CD3 delta subunit of T-cell receptor complex
summary
TP53 This gene encodes a tumor suppressor protein containing transcriptional activation, DNA binding, and oligomerization domains. The encoded protein responds to diverse cellular stresses to regulate expression of target genes, thereby inducing cell cycle arrest, apoptosis, senescence, DNA repair, or changes in metabolism. Mutations in this gene are associated with a variety of human cancers, including hereditary cancers such as Li-Fraumeni syndrome. Alternative splicing of this gene and the use of alternate promoters result in multiple transcript variants and isoforms. Additional isoforms have also been shown to result from the use of alternate translation initiation codons from identical transcript variants (PMIDs: 12032546, 20937277). [provided by RefSeq, Dec 2016]
EGFR The protein encoded by this gene is a transmembrane glycoprotein that is a member of the protein kinase superfamily. This protein is a receptor for members of the epidermal growth factor family. EGFR is a cell surface protein that binds to epidermal growth factor, thus inducing receptor dimerization and tyrosine autophosphorylation leading to cell proliferation. Mutations in this gene are associated with lung cancer. EGFR is a component of the cytokine storm which contributes to a severe form of Coronavirus Disease 2019 (COVID-19) resulting from infection with severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2). [provided by RefSeq, Jul 2020]
CD3D The protein encoded by this gene is part of the T-cell receptor/CD3 complex (TCR/CD3 complex) and is involved in T-cell development and signal transduction. The encoded membrane protein represents the delta subunit of the CD3 complex, and along with four other CD3 subunits, binds either TCR alpha/beta or TCR gamma/delta to form the TCR/CD3 complex on the surface of T-cells. Defects in this gene are a cause of severe combined immunodeficiency autosomal recessive T-cell-negative/B-cell-positive/NK-cell-positive (SCIDBNK). Two transcript variants encoding different isoforms have been found for this gene. Other variants may also exist, but the full-length natures of their transcripts has yet to be defined. [provided by RefSeq, Feb 2009]
translate_ggplot
- 原版函数
- 翻译坐标轴标签
- 不过这些都是可以自己通过翻译原始绘图数据去实现, 没什么好说的
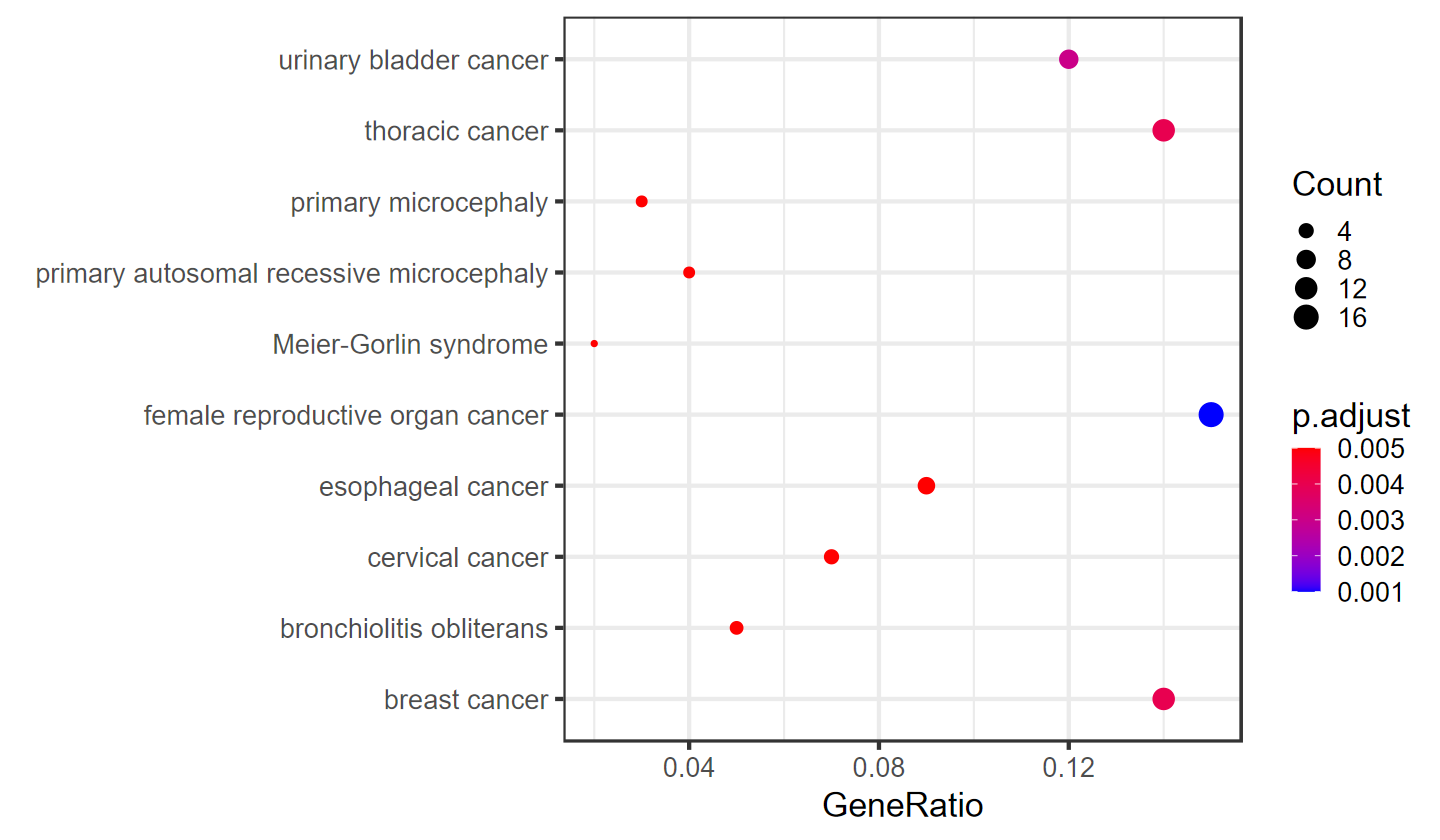
library(ggplot2)
data <- data.frame(
term = c(
"female reproductive organ cancer", "breast cancer", "thoracic cancer",
"urinary bladder cancer", "esophageal cancer", "cervical cancer",
"bronchiolitis obliterans", "primary autosomal recessive microcephaly",
"primary microcephaly", "Meier-Gorlin syndrome"
),
GeneRatio = c(0.15, 0.14, 0.14, 0.12, 0.09, 0.07, 0.05, 0.04, 0.03, 0.02),
p.adjust = c(0.001, 0.004, 0.004, 0.003, 0.005, 0.005, 0.005, 0.005, 0.005, 0.005),
Count = c(16, 12, 12, 8, 6, 4, 3, 2, 2, 1)
)
Warning message:
"package 'ggplot2' was built under R version 4.4.3"
options(repr.plot.width = 12, repr.plot.height = 7)
p <- ggplot(data, aes(x = GeneRatio, y = term))
p <- p + geom_point(aes(size = Count, color = p.adjust))
p <- p + scale_color_gradient(low = "blue", high = "red")
p <- p + labs(x = "GeneRatio", y = "", color = "p.adjust", size = "Count")
p <- p + theme_bw(20)
print(p)
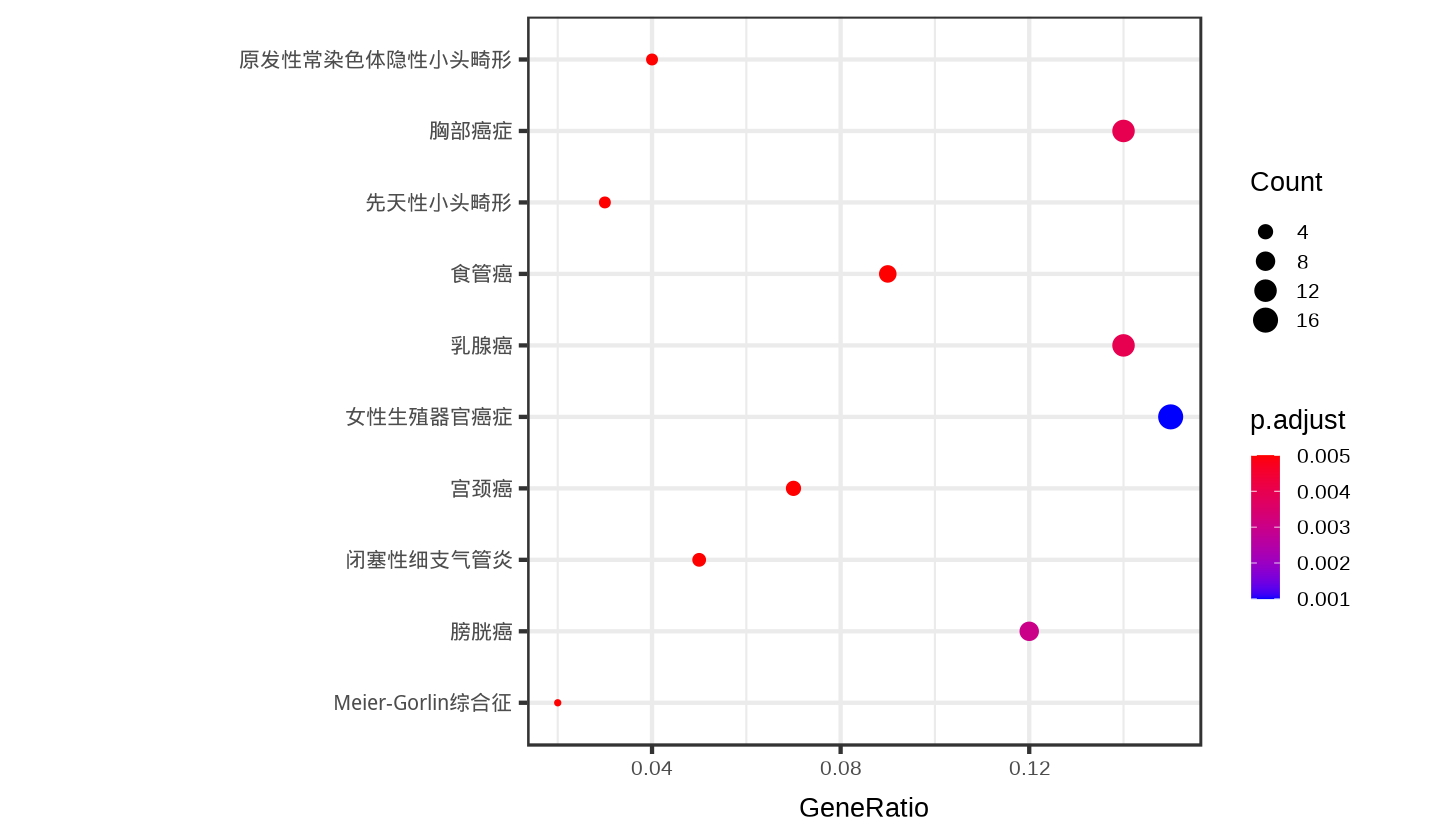
# 显示中文
showtext::showtext_auto()
# y轴翻译为中文
translate_ggplot(p, axis = 'y')
translate2
- translate的优化函数, 优化了两个地方
- 一是在对很多个字符进行批量翻译时, 出现有些返回为空的bug, 这个bug也很致命, 输入和输出数目对不上, 造成数据错位了
- 二是如果输入的向量元素个数很多, 翻译也会比较慢, 因为是逐个翻译并返回的
- 我这里解决的办法是将多个字符串尽可能地连接为单个字符串, 因为单词翻译字符长度, 最长为5000个字符, 翻译后再进行分割, 这样两个问题就都能解决了!
- 同时为了确保返回不会空, 调用之前先等待1秒, 慢点总比数据错乱好。
translate2(data$term)
- '女性生殖器官癌症'
- '乳腺癌症'
- '胸部癌症'
- '膀胱癌症'
- '食管癌症'
- '宫颈癌症'
- '闭塞性细支气管炎'
- '原发性常染色体隐性遗传性小头畸形'
- '原发畸形'
- 'Meier-Gorlin综合征'
gene_summary2
- translate的优化函数, 也优化了几个地方
- 首先翻译函数用translate2替代了
- 最关键的一点是原版基因输入只能是ENTREZID, 但我们最常用的还是基因名SYMBOL
- 因此这里调用bitr进行自动转换
- 输入不再是 ENTREZID, 而是SYMBOL
- 最后就是提供了双语版本
print(gene_summary2(c("TP53", "EGFR", "CD3D")))
gene_name description
1 TP53 tumor protein p53
2 EGFR epidermal growth factor receptor
3 CD3D CD3 delta subunit of T-cell receptor complex
description_cn
1 肿瘤蛋白p53
2 表皮生长因子受体
3 T细胞受体复合物的CD3δ亚基
summary
1 This gene encodes a tumor suppressor protein containing transcriptional activation, DNA binding, and oligomerization domains. The encoded protein responds to diverse cellular stresses to regulate expression of target genes, thereby inducing cell cycle arrest, apoptosis, senescence, DNA repair, or changes in metabolism. Mutations in this gene are associated with a variety of human cancers, including hereditary cancers such as Li-Fraumeni syndrome. Alternative splicing of this gene and the use of alternate promoters result in multiple transcript variants and isoforms. Additional isoforms have also been shown to result from the use of alternate translation initiation codons from identical transcript variants (PMIDs: 12032546
, 20937277). [provided by RefSeq, Dec 2016]2 The protein encoded by this gene is a transmembrane glycoprotein that is a member of the protein kinase superfamily. This protein is a receptor for members of the epidermal growth factor family. EGFR is a cell surface protein that binds to epidermal growth factor, thus inducing receptor dimerization and tyrosine autophosphorylation leading to cell proliferation. Mutations in this gene are associated with lung cancer. EGFR is a component of the cytokine storm which contributes to a severe form of Coronavirus Disease 2019 (COVID-19) resulting from infection with severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2). [provided by RefSeq, Jul 2020]
3 The protein encoded by this gene is part of the T-cell receptor/CD3 complex (TCR/CD3 complex) and is involved in T-cell development and signal transduction. The encoded membrane protein represents the delta subunit of the CD3 complex, and along with four other CD3 subunits, binds either TCR alpha/beta or TCR gamma/delta to form the TCR/CD3 complex on the surface of T-cells. Defects in this gene are a cause of severe combined immunodeficiency autosomal recessive T-cell-negative/B-cell-positive/NK-cell-positive (SCIDBNK). Two transcript variants encoding different isoforms have been found for this gene. Other variants may also exist, but the full-length natures of their transcripts has yet to be defined. [provided by RefSeq, Feb 2009]
summary_cn
1 该基因编码一种含有转录激活、DNA结合和寡聚结构域的肿瘤抑制蛋白。编码的蛋白质对各种细胞应激做出反应,调节靶基因的表达,从而诱导细胞周期停滞、凋亡、衰老、DNA修复或代谢变化。该基因的突变与多种人类癌症有关,包括遗传性癌症,如Li-Fraumeni综合征。该基因的选择性剪接和选择性启动子的使用导致多种转录变体和异构体。其他同工型也被证明是由使用来自相同转录变体的替代翻译起始密码子引起的(PMID:12032546
20937277)。[由RefSeq提供,2016年12月]2 该基因编码的蛋白质是一种跨膜糖蛋白,是蛋白激酶超家族的成员。这种蛋白质是表皮生长因子家族成员的受体。EGFR是一种细胞表面蛋白,与表皮生长因子结合,从而诱导受体二聚化和酪氨酸自磷酸化,导致细胞增殖。该基因的突变与肺癌有关。EGFR是细胞因子风暴的一个组成部分,该风暴导致感染严重急性呼吸综合征冠状病毒-2(SARS-CoV-2)而导致的严重形式的2019冠状病毒病(新冠肺炎)。[由RefSeq提供,2020年7月]
3 该基因编码的蛋白质是T细胞受体/CD3复合物(TCR/CD3复合体)的一部分,参与T细胞发育和信号转导。编码的膜蛋白代表CD3复合物的δ亚基,与其他四个CD3亚基一起,结合TCRα/β或TCRγ/δ,在T细胞表面形成TCR/CD3复合物。该基因的缺陷是严重联合免疫缺陷常染色体隐性T细胞阴性/B细胞阳性/NK细胞阳性(SCIDBNK)的原因。已经发现该基因有两种编码不同亚型的转录变体。其他变体也可能存在,但其转录物的全长性质尚未确定。【由RefSeq提供,2009年2月】
report_pathway
- 这个函数不放在fanyi2包里, 而是会放在正在开发的 fastEnrich 包里, 可用来快速生成富集分析的中文报告
text = report_pathway(data$term, out_name = "enrich_report.txt")
print(text)
[1] "富集的top5通路分别为:女性生殖器官癌症 ( female reproductive organ cancer )、乳腺癌症 ( breast cancer )、胸部癌症 ( thoracic cancer )、膀胱癌症 ( urinary bladder cancer )和食管癌症(esophageal cancer)。"
- 这里只是给大家一个引子, 有了翻译你可以做任何它能做的事!
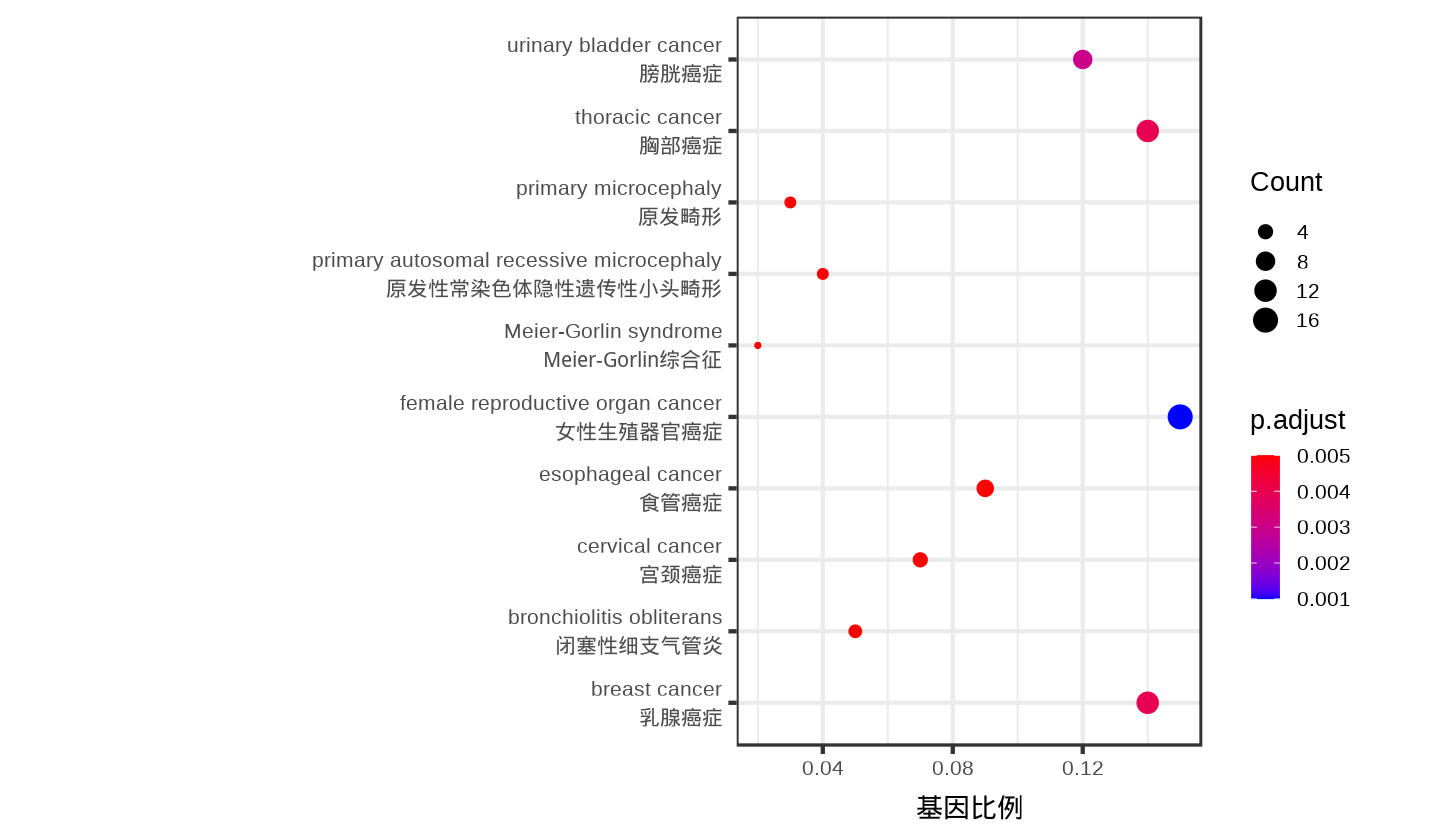
- 比如富集分析气泡图双语版本
data$term2 = paste0(data$term, "\n", translate2(data$term))
p <- ggplot(data, aes(x = GeneRatio, y = term2))
p <- p + geom_point(aes(size = Count, color = p.adjust))
p <- p + scale_color_gradient(low = "blue", high = "red")
p <- p + labs(x = translate2("GeneRatio"), y = "", color = "p.adjust", size = "Count")
p <- p + theme_bw(20)
print(p)
-
最后温馨提醒一下, 不要输入过多的字符, 因为翻译是收费的, 用完就要交钱了, 虽然也没几个😅
-
本教程资料免费,需要代码资料的后台添加我好友发送此推文领取。
-

















 2678
2678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









