



 业务需用华为云平台FusionInsight Manager的Flink组件,实现源端数据向DWS数据库实时同步。在MRS工程加业务代码后启动程序报错,经测试排除数据库连接和业务逻辑问题,最终定位是数据库Url的IP问题,将其改为云端IP后程序正常运行。
业务需用华为云平台FusionInsight Manager的Flink组件,实现源端数据向DWS数据库实时同步。在MRS工程加业务代码后启动程序报错,经测试排除数据库连接和业务逻辑问题,最终定位是数据库Url的IP问题,将其改为云端IP后程序正常运行。
业务需求:应用华为云平台FusionInsight Manager中的Flink组件配合业务程序实现源端数据向DWS数据库的实时同步。
在MRS二次开发样例工程的基础上加入自己的业务代码:
public class ReadFromKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
ParameterTool paraTool = ParameterTool.fromArgs(args);
Properties properties = paraTool.getProperties();
DataStream<String> messageStream =
env.addSource(
new FlinkKafkaConsumer<>(
paraTool.get("topic"), new SimpleStringSchema(), properties));
SingleOutputStreamOperator<String> operator = messageStream.
rebalance()
.map(
new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
return "Flink says => " + s + System.getProperty("line.separator");
}
});
operator.addSink(JdbcSink.
sink("insert into test.test_fff(fff) values (?)",
(preparedStatement, s) -> {
preparedStatement.setString(1, s);
},
JdbcExecutionOptions.builder()
.withBatchSize(10)
.withBatchIntervalMs(1000)
.withMaxRetries(3)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("org.postgresql.Driver")
.withUrl("jdbc:postgresql://xx.xxx.xxx.xxx:xxxx/GS_DW")// 数据库Url地址
.withUsername("username")
.withPassword("password")
.build()
));
env.execute();
}
}
加入需求业务后启动程序,消息发送程序实时发送编辑好的Json字符串,启动ReakFromKafka接收并消费消息。此时发生报错“java.net.NoRouteToHostException: No route to host (Host unreachable)”,程序终止。报错信息:Caused by: java.net.NoRouteToHostException: No route to host (Host unreachable)
数据库连接经过验证没有问题。(将数据库写入代码从addSink方法中取出,直接在main方法中执行入库正常,测试代码及数据库结果如下)
public class ReadFromKafka3 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
ParameterTool paraTool = ParameterTool.fromArgs(args);
Properties properties = paraTool.getProperties();
DataStream<String> messageStream =
env.addSource(
new FlinkKafkaConsumer<>(
paraTool.get("topic"), new SimpleStringSchema(), properties));
tryInsert(new Worker(1, "jjj", "123@123.com", 22, new BigDecimal("553.212")));
SingleOutputStreamOperator<String> operator = messageStream.
rebalance()
.map(
new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
return "Flink says => " + s + System.getProperty("line.separator");
}
});
env.execute();
}
public static void tryInsert(Worker worker) {
String sql = "insert into test.worker(id, name, email, age, salary) values (? ,? ,? ,? ,? )";
Connection conn = null;
PreparedStatement ps = null;
try {
conn =DriverManager.getConnection("jdbc:postgresql://xx.xxx.xxx.xxx:xxxx/GS_DW",
"username", "password");
ps = conn.prepareStatement(sql);
ps.setInt(1, worker.getInteger("id"));
ps.setString(2, worker.getString("name"));
ps.setString(3, worker.getString("email"));
ps.setInt(4, worker.getInteger("age"));
ps.setBigDecimal(5, worker.getBigDecimal("salary"));
ps.executeUpdate();
System.out.println(" insert finished! ");
} catch (Exception e) {
System.out.println(" insert error : " + e.toString() + " , " + e.getCause());
System.out.println("e.getMessage() = " + e.getMessage() + e.getLocalizedMessage());
e.printStackTrace();
} finally {
DruidUtil.closePsConn(ps, conn);
}
}
}
操作结果:
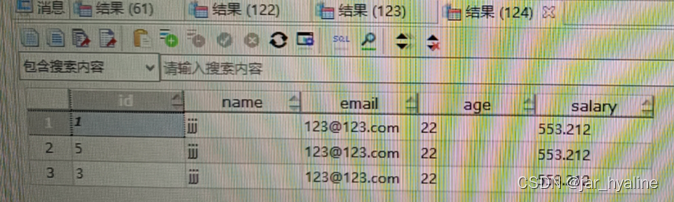
故问题定位就是只要将数据库操作代码放入addSink方法中就会报如上错误。PS:flink算子入库方法改为使用JdbcSinkFunction(继承 RichSinkFunction类)后报错还是一样,说明不是业务逻辑的问题。
经过各种测试及查找资料,最终定位问题是数据库Url的IP问题。由于Flink程序是在云平台上运行,故此时需要将"jdbc:postgresql://xx.xxx.xxx.xxx:xxxx/GS_DW"中的IP改为云端IP,找云平台运维人员拿到云端IP并修改后程序即可正常运行。

















 1460
1460




 到【灌水乐园】发言
到【灌水乐园】发言







