




📝 博客主页:jaxzheng的优快云主页
目录
医疗数据蕴含巨大价值,但其敏感性要求严格隐私保护。传统数据集中存储模式面临合规风险与泄露隐患,而联邦学习(Federated Learning)作为分布式机器学习范式,允许多方协作训练模型而不共享原始数据,为医疗AI提供创新解决方案。本文深入探讨联邦学习在医疗场景的应用实践、隐私保护机制及技术挑战。
联邦学习通过"数据不动模型动"的架构实现隐私保护:各参与方(如医院)在本地训练模型,仅上传模型参数更新(如梯度)至中央服务器,服务器聚合更新后形成全局模型。该过程避免了原始数据的跨机构传输,显著降低隐私泄露风险。
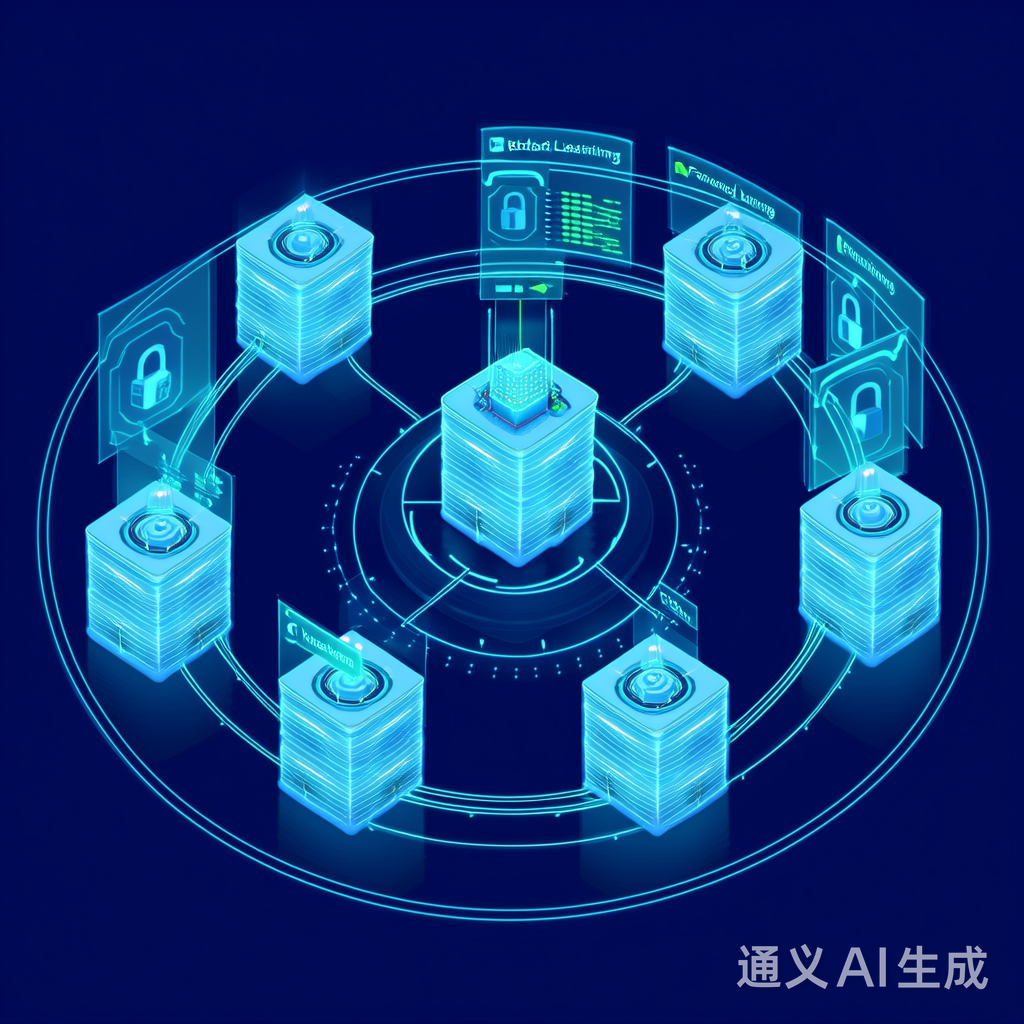
图:联邦学习典型架构,包含客户端、服务器和安全通信层
关键流程:
- 服务器初始化全局模型
- 分发模型至各客户端
- 客户端本地训练并计算更新
- 上传模型更新至服务器
- 服务器聚合更新并迭代
# 联邦学习基础流程模拟
import numpy as np
# 初始化全局模型
global_model = np.zeros(10)
# 模拟5个医疗机构客户端
client_updates = []
for _ in range(5):
# 本地训练生成梯度更新(模拟)
local_update = np.random.normal(0, 0.1, 10)
client_updates.append(local_update)
# 服务器聚合更新
global_model = np.mean(client_updates, axis=0)
print("聚合后全局模型:", global_model)
多家医院协作构建糖尿病预测模型,利用分散的电子健康记录(EHR)与眼底影像数据。联邦学习使各机构在本地训练模型,仅共享特征提取层参数,避免患者ID等敏感信息暴露。
# 医疗联邦学习模型构建示例(使用PyTorch)
import torch
import torch.nn as nn
class MedicalFLModel(nn.Module):
def __init__(self):
super().__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(3, 16, 3),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1)
)
self.classifier = nn.Linear(16, 2) # 二分类:糖尿病/非糖尿病
def forward(self, x):
features = self.feature_extractor(x)
return self.classifier(features.view(features.size(0), -1))
# 模型在客户端本地训练
client_model = MedicalFLModel()
client_optimizer = torch.optim.SGD(client_model.parameters(), lr=0.01)
# 模拟本地数据训练
for epoch in range(10):
client_optimizer.zero_grad()
outputs = client_model(torch.randn(32, 3, 224, 224)) # 随机输入
loss = torch.nn.CrossEntropyLoss()(outputs, torch.randint(0, 2, (32,)))
loss.backward()
client_optimizer.step()
在癌症早筛场景,联邦学习整合多家医院的病理切片数据。各医院仅上传CNN特征向量,服务器构建全局分类器,确保患者影像数据始终保留在本地。

图:多中心医院协作的癌症影像分析流程
在模型更新中添加可控噪声,确保单个数据点无法被推断。核心参数:ε(隐私预算)和δ(泄露概率)。
# 实现差分隐私的梯度噪声添加
import numpy as np
def add_dp_noise(gradient, epsilon, delta, max_norm):
"""
添加高斯噪声实现差分隐私
:param gradient: 原始梯度
:param epsilon: 隐私预算
:param delta: 泄露概率
:param max_norm: 梯度裁剪阈值
"""
# 梯度裁剪
clip_norm = max_norm
gradient_norm = np.linalg.norm(gradient)
if gradient_norm > clip_norm:
gradient = gradient * clip_norm / gradient_norm
# 计算噪声标准差
sigma = clip_norm * np.sqrt(2 * np.log(1.25 / delta)) / epsilon
noise = np.random.normal(0, sigma, gradient.shape)
return gradient + noise
# 应用示例
raw_gradient = np.array([0.5, -0.3, 1.2])
noisy_gradient = add_dp_noise(raw_gradient, epsilon=1.0, delta=1e-5, max_norm=2.0)
print("原始梯度:", raw_gradient)
print("添加噪声后:", noisy_gradient)
利用秘密共享技术确保服务器无法单独获取单个客户端更新。客户端将更新分割为随机份额,服务器仅能计算份额和,无法反推原始数据。
图:联邦学习中隐私保护技术的综合比较(差分隐私、安全聚合、同态加密)
- 数据异质性:不同医院数据分布差异导致模型收敛困难
- 通信开销:大规模客户端需频繁通信,影响效率
- 隐私-效用权衡:高隐私保护降低模型精度
- 动态隐私预算:根据数据敏感度动态调整ε值
- 联邦强化学习:结合强化学习优化协作策略
- 区块链存证:记录模型更新过程确保可审计性
联邦学习为医疗数据协作开辟了新路径,通过"数据不离域"模式平衡了创新与隐私。结合差分隐私、安全聚合等技术,已在糖尿病预测、癌症影像分析等场景验证其价值。未来随着算法优化与标准化推进,联邦学习将成为医疗AI基础设施的核心组件,推动精准医疗进入新阶段。医疗机构需持续关注隐私保护机制的演进,构建安全可信的AI协作生态。

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









