




📝 博客主页:jaxzheng的优快云主页
随着电子健康记录(EHRs)、基因组学数据和可穿戴设备的普及,医疗数据量呈现爆炸式增长。个性化推荐与决策支持技术(PRDST)正成为提升医疗效率、优化治疗方案的核心手段。本文探讨PRDST的关键技术、实现路径及实际应用,重点解析如何从海量医疗数据中提取价值,为临床决策提供科学依据。
医疗数据来源多样,包括结构化数据(如实验室结果、诊断编码)和非结构化数据(如医生笔记、医学影像)。高效的数据预处理是PRDST的基石,涉及数据清洗、标准化和特征工程。

以下为Python实现的医疗数据预处理示例,使用Pandas库处理EHRs:
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 加载示例EHR数据
ehr_data = pd.read_csv('patient_records.csv')
# 数据清洗:处理缺失值
ehr_data = ehr_data.dropna(subset=['blood_pressure', 'glucose_level'])
# 特征标准化
scaler = StandardScaler()
ehr_data[['blood_pressure', 'glucose_level']] = scaler.fit_transform(ehr_data[['blood_pressure', 'glucose_level']])
# 输出处理后的数据
print(ehr_data.head())
个性化推荐通过分析患者历史数据(如病史、用药记录),预测最优治疗方案。协同过滤和深度学习是主流方法。以下示例展示基于矩阵分解的推荐算法:
from sklearn.decomposition import NMF
# 构建患者-治疗方案交互矩阵
interaction_matrix = ehr_data.pivot_table(index='patient_id', columns='treatment', values='response', aggfunc='mean')
# 应用非负矩阵分解(NMF)
model = NMF(n_components=5, init='random', random_state=42)
W = model.fit_transform(interaction_matrix)
H = model.components_
# 为新患者生成推荐
def recommend_treatment(patient_id):
patient_vector = W[interaction_matrix.index.get_loc(patient_id)]
scores = patient_vector.dot(H.T)
return interaction_matrix.columns[scores.argsort()[::-1][:3]]
# 示例:推荐患者ID 1002的治疗方案
print(recommend_treatment(1002))
该算法输出患者最可能响应的前三项治疗方案,显著减少试错成本。
决策支持系统(DSS)将推荐结果无缝嵌入临床工作流。核心组件包括实时数据接入、AI推理引擎和可视化界面。下图展示典型DSS架构:

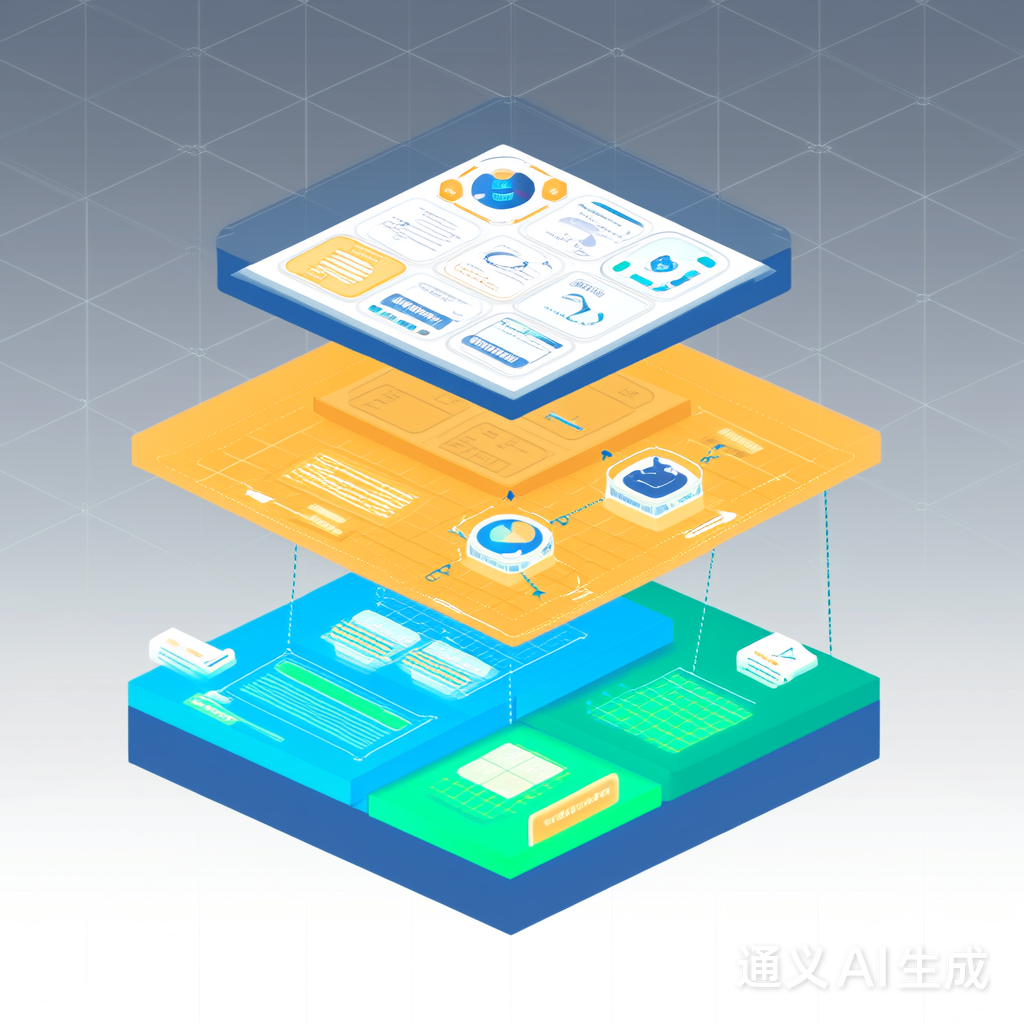
系统通过API与医院信息系统(HIS)对接,实现以下功能:
- 实时预警:检测药物相互作用风险
- 方案对比:生成治疗选项的疗效/副作用对比
- 证据追溯:标注推荐依据的临床指南
PRDST仍面临三大挑战:
- 数据异构性:不同医院数据格式不统一
- 隐私合规:需满足HIPAA/GDPR要求
- 临床可解释性:AI决策需医生可理解
未来趋势包括:
- 联邦学习:在保护隐私下跨机构训练模型
- 多模态融合:整合影像、基因组与电子病历
- 自然语言处理:从医生笔记中提取关键信息
医疗数据的个性化推荐与决策支持技术正从理论走向临床实践。通过高效数据处理、智能算法和系统化集成,PRDST不仅提升诊疗精准度,还推动医疗资源优化配置。随着技术成熟,未来将实现“数据驱动的个性化医疗”从愿景变为日常标准。医疗机构需加速构建数据基础设施,与技术开发者协同,释放医疗数据的真正价值。

















 2689
2689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









