



使用GraphRAG构建知识图谱问答系统的完整流程。主要内容包括:
1)创建Python虚拟环境并安装GraphRAG;
2)配置大模型API(DeepSeek和通义千问);
3)索引流程实现及优化(调整chunk大小、启用缓存);
4)查询系统实现,包括数据加载、上下文构建和带记忆功能的对话引擎。
一、创建虚拟环境
创建虚拟环境名称为“RAG
conda create -n rag python=3.10
conda activate rag
创建项目文件夹 RAG 路径如下:G:\ProgramAI\Jupyter Notebook\RAG 创建input文件夹。
G:\ProgramAI\Jupyter Notebook\RAG\input 导入TXT文本文件。
二、安装graphrag
官网下载 graphrag-2.6.0 进入虚拟换进、进入到graphrag文件夹内。
G:
cd G:\ProgramAI\graphrag-2.6.0\graphrag-2.6.0
pip install -e .
三、初始化
1、初始化项目文件
graphrag init --root ./RAG
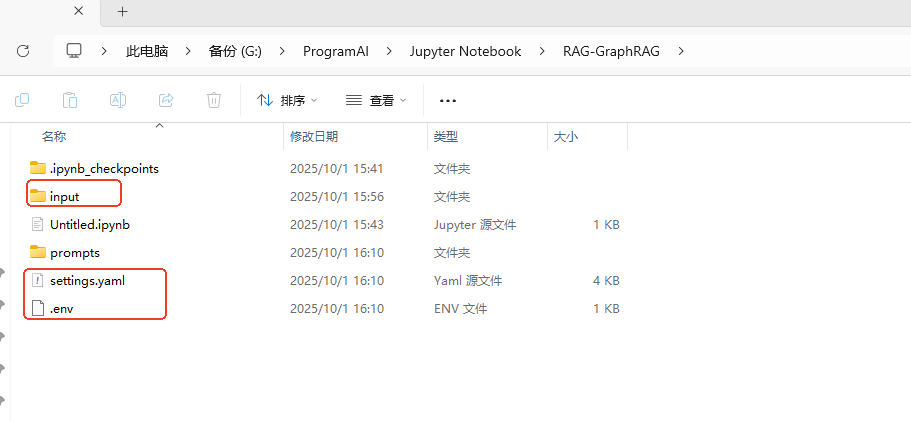
2、.env修改配置文件
.env 添加API-key sk-你的deepseek API-KEY
GRAPHRAG_API_KEY=sk-你的deepseek API-KEY
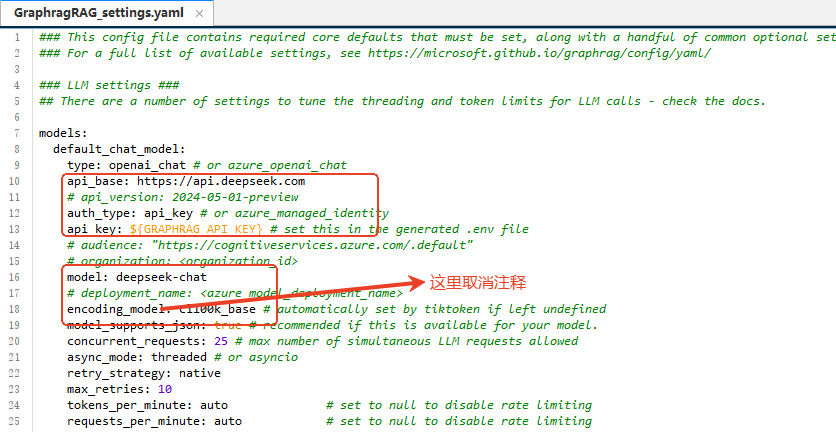
3、修改配置settings.yaml文件
3.1 关系识别、关系挖掘大模型配置 使用deepseek v3模型。deepseek没有提供向量模型
api_base: https://api.deepseek.com
model: deepseek-chat
encoding_model: cl100k_base # automatically set by tiktoken if left undefined
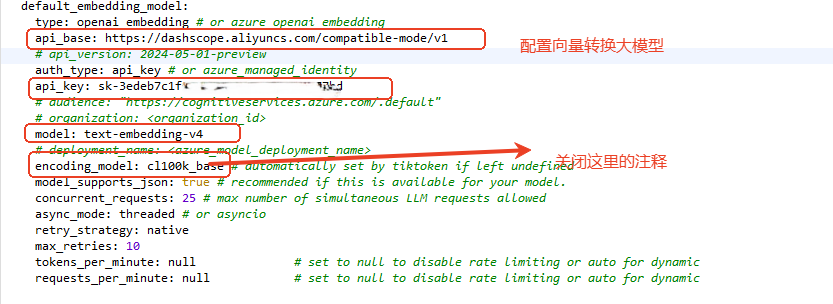
3.2 向量转换模型配置。使用(通义千问向量模型)text-embedding-v4
api_key: sk-你的通义千问API-KEY
type: openai_embedding <span style="color:#aa5500"># or azure_openai_embedding</span>
model: text-embedding-v4
api_base:https://dashscope.aliyuncs.com/compatible-mode/v1</span></span>
四、优化调整
1. 优化 chunk 配置(最有效方法)
-
604KB 的文件,原本分成 5169 个 1200 tokens 的块
-
增大到 3000 tokens 后,块数量减少约 70%
-
从 5169 → 1500 块左右,减少 70% 的 API 调用
chunks: size: 3000 # 从 1200 增加到 3000(更适合小文件)
overlap: 300 # 适当增加重叠
group_by_columns: [id]
2. 启用缓存功能(避免重复请求)
cache:
type: file
base_dir: "cache"
enabled: true # 确保启用缓存
3. 调整 API 速率限制
models:
default_chat_model:
# ...
tokens_per_minute: 1000 # 已设置
requests_per_minute: 50 # 已设置
default_embedding_model:
# ...
tokens_per_minute: null # 已设置为禁用
requests_per_minute: null # 已设置为禁用
五、Indexing检索流程实现
一切准备就绪后,即可开始执行GraphRAG索引过程。可以借助GraphRAG脚本自动执行indexing。
cd 到文件目录
graphrag index --root ./RAG
graphrag index --root "G:\ProgramAI\Jupyter Notebook\RAG" --output "G:\ProgramAI\Jupyter Notebook\RAG\output" --verbose
耐心等待。。。。。。
看到 output 文件夹生成一下文件。
六、创建查询
加载 Parquet 文件并手动构建对象完成查询
安装依赖包
pip install tiktoken pandas openai
完整代码
import os
import pandas as pd
import tiktoken
from openai import OpenAI
# ======================
# 配置(确保路径和文件名与实际输出一致)
# ======================
INPUT_DIR = "./output" # 确保这是GraphRAG输出目录
ENTITY_TABLE = "entities"
COMMUNITY_TABLE = "communities"
REPORT_TABLE = "community_reports"
COMMUNITY_LEVEL = 2
# ======================
# 1. 检查必要文件是否存在
# ======================
required_files = [
f"{INPUT_DIR}/{ENTITY_TABLE}.parquet",
f"{INPUT_DIR}/{COMMUNITY_TABLE}.parquet",
f"{INPUT_DIR}/{REPORT_TABLE}.parquet"
]
for file in required_files:
if not os.path.exists(file):
raise FileNotFoundError(f"缺失必要文件: {file}. 请先运行GraphRAG处理流程")
# ======================
# 2. 加载数据(使用正确文件名)
# ======================
print("正在加载数据...")
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
community_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_TABLE}.parquet")
report_df = pd.read_parquet(f"{INPUT_DIR}/{REPORT_TABLE}.parquet")
print(f"数据加载成功: {len(entity_df)} 个实体, {len(community_df)} 个社区, {len(report_df)} 个报告")
# ======================
# 3. 定义辅助类(与GraphRAG兼容)
# ======================
class Report:
def __init__(self, id, title, content, community, rank=0):
self.id = id
self.title = title
self.content = content
self.community = community
self.rank = rank
class Community:
def __init__(self, id, name, level, rank=0):
self.id = id
self.name = name
self.level = level
self.rank = rank
class Entity:
def __init__(self, id, name, type, description, community, rank=0):
self.id = id
self.name = name
self.type = type
self.description = description
self.community = community
self.rank = rank
# ======================
# 4. 构建数据对象
# ======================
def build_entities(entity_df):
entities = []
for _, row in entity_df.iterrows():
entities.append(Entity(
id=row["id"],
name=row.get("entity", row.get("name", "Unknown")),
type=row.get("type", "Unknown"),
description=row.get("description", ""),
community=row.get("community", ""),
rank=row.get("rank", 0)
))
return entities
def build_communities(community_df):
communities = []
for _, row in community_df.iterrows():
communities.append(Community(
id=row["id"],
name=row.get("title", row.get("name", "Unknown")),
level=row["level"],
rank=row.get("rank", 0)
))
return communities
def build_reports(report_df, level):
reports = []
for _, row in report_df[report_df["level"] == level].iterrows():
reports.append(Report(
id=row["id"],
title=row.get("title", "Unknown"),
content=row.get("full_content", row.get("content", "")),
community=row["community"],
rank=row.get("rank", 0)
))
return reports
# 构建所有对象
entities = build_entities(entity_df)
communities = build_communities(community_df)
reports = build_reports(report_df, COMMUNITY_LEVEL)
print(f"构建完成: {len(entities)} 个实体, {len(communities)} 个社区, {len(reports)} 个报告")
# ======================
# 5. 验证数据有效性
# ======================
print("\n 验证数据内容...")
if not reports:
print("警告: 未找到报告数据。请检查输入文档是否包含'业主大会筹备组'相关内容")
else:
contains_keyword = any("筹备组" in report.content for report in reports)
print(f"报告内容{'包含' if contains_keyword else '不包含'} '筹备组' 关键词")
# ======================
# 6. 实现Context Builder(带记忆功能)
# ======================
class GlobalCommunityContext:
def __init__(self, community_reports, communities, entities, token_encoder):
self.reports = community_reports
self.communities = {c.id: c for c in communities}
self.entities = {e.id: e for e in entities}
self.token_encoder = token_encoder
def build_context(self, query, conversation_history, **params):
max_tokens = params.get("max_tokens", 12000)
context_name = params.get("context_name", "Reports")
# 生成系统提示(包含对话历史)
system_prompt = f"""
你是一个专业的法律咨询助手,专注于物业管理领域。请根据以下文档信息和对话历史回答问题。
不要编造信息。如果信息不足,请明确说明。
对话历史:
{self.format_conversation_history(conversation_history)}
问题: {query}
""".strip()
tokens_used = len(self.token_encoder.encode(system_prompt))
context_parts = [system_prompt]
# 按排名排序报告(高排名优先)
sorted_reports = sorted(self.reports, key=lambda x: x.rank, reverse=True)
for report in sorted_reports:
# 只处理当前社区级别
if self.communities.get(report.community, Community("", "", 0)).level != COMMUNITY_LEVEL:
continue
report_text = f"\n--- [{report.community}] {report.title} ---\n{report.content}\n"
report_tokens = len(self.token_encoder.encode(report_text))
if tokens_used + report_tokens > max_tokens:
break
context_parts.append(report_text)
tokens_used += report_tokens
return "".join(context_parts), tokens_used
def format_conversation_history(self, conversation_history):
"""格式化对话历史为字符串"""
history_str = ""
for msg in conversation_history:
role = "用户" if msg["role"] == "user" else "助手"
history_str += f"{role}: {msg['content']}\n"
return history_str
# ======================
# 7. 实现带记忆功能的搜索引擎
# ======================
class GlobalSearch:
def __init__(self, llm_client, context_builder, token_encoder, max_data_tokens=12000):
self.llm_client = llm_client
self.context_builder = context_builder
self.token_encoder = token_encoder
self.max_data_tokens = max_data_tokens
self.conversation_history = [] # 用于存储对话历史
def search(self, question: str) -> dict:
# 添加当前问题到对话历史
self.conversation_history.append({"role": "user", "content": question})
context, token_count = self.context_builder.build_context(
question,
self.conversation_history,
max_tokens=self.max_data_tokens,
context_name="社区报告"
)
response = self.llm_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个专业的法律咨询助手,专注于物业管理领域。"},
{"role": "user", "content": context}
],
max_tokens=2000,
temperature=0.0,
top_p=0.9
)
# 添加助手的回答到对话历史
response_text = response.choices[0].message.content.strip()
self.conversation_history.append({"role": "assistant", "content": response_text})
return {
"response": response_text,
"context_tokens": token_count,
"prompt_tokens": len(self.token_encoder.encode(context)),
"conversation_history": self.conversation_history.copy() # 返回副本避免外部修改
}
# ======================
# 8. 初始化并执行对话
# ======================
print("\n初始化RAG系统...")
token_encoder = tiktoken.get_encoding("cl100k_base")
# 创建上下文构建器
context_builder = GlobalCommunityContext(
community_reports=reports,
communities=communities,
entities=entities,
token_encoder=token_encoder
)
# 配置API
OPENAI_API_KEY = "sk-你的API-KEY"
OPENAI_API_BASE = "https://api.deepseek.com"
llm_client = OpenAI(
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE
)
search_engine = GlobalSearch(
llm_client=llm_client,
context_builder=context_builder,
token_encoder=token_encoder,
max_data_tokens=12000
)
print("\n" + "="*70)
print("你好!我是物业管理法律咨询助手。可以问我关于业主大会、筹备组、决议通过条件等问题。")
print("输入 'exit' 退出对话")
print("="*70)
# ======================
# 9. 对话循环(带记忆功能)
# ======================
while True:
user_input = input("\n你: ").strip()
if user_input.lower() in ["exit", "quit", "bye"]:
print("感谢使用!再见!")
break
if not user_input:
print("请输入有效问题")
continue
print("\n助手: ", end="", flush=True)
result = search_engine.search(user_input)
# 打印回答
print(result["response"])
# 打印当前对话历史(用于调试)
print("\n" + "-"*50)
print("当前对话历史:")
for msg in result["conversation_history"]:
print(f"{msg['role'].capitalize()}: {msg['content'][:100]}{'...' if len(msg['content']) > 100 else ''}")
print("-"*50)
# 打印令牌统计
print(f"使用上下文令牌: {result['context_tokens']} | 提示令牌: {result['prompt_tokens']}")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









