



 HashMap是Java中基于哈希表的Map实现,提供无序、key唯一、value可重复的映射操作。在JDK1.7中,数据结构为数组+链表,而JDK1.8进行了优化,使用数组+链表+红黑树,当链表长度超过8且数组长度超过64时转为红黑树,以优化查询性能。加载因子默认为0.75,影响扩容策略,当元素数量超过阈值时进行扩容。
HashMap是Java中基于哈希表的Map实现,提供无序、key唯一、value可重复的映射操作。在JDK1.7中,数据结构为数组+链表,而JDK1.8进行了优化,使用数组+链表+红黑树,当链表长度超过8且数组长度超过64时转为红黑树,以优化查询性能。加载因子默认为0.75,影响扩容策略,当元素数量超过阈值时进行扩容。
一、概述
HashMap是Map的常用子类,基于哈希表(数组+链表)的Map接口实现,提供所有可选的映射操作。关键特点:无序、key唯一、value允许重复、key和value允许为null。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
二、版本
2.1 JDK1.7
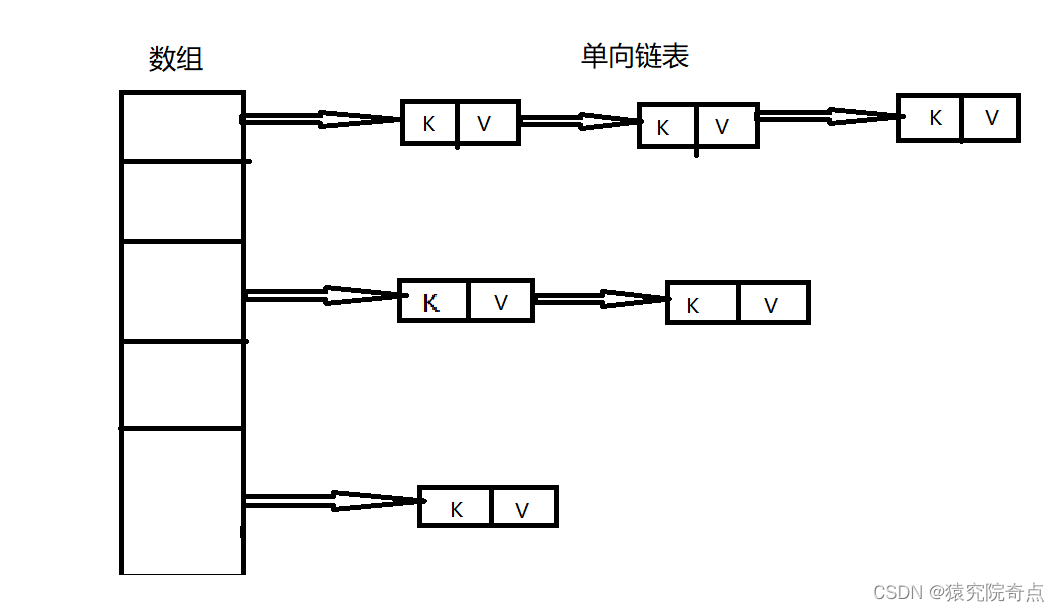
JKD1.7之前HashMap的数据结构为数组+单项链表。哈希冲突时,将冲突值加入链表中,插入元素时采用头插法。
2.2 JDK1.8
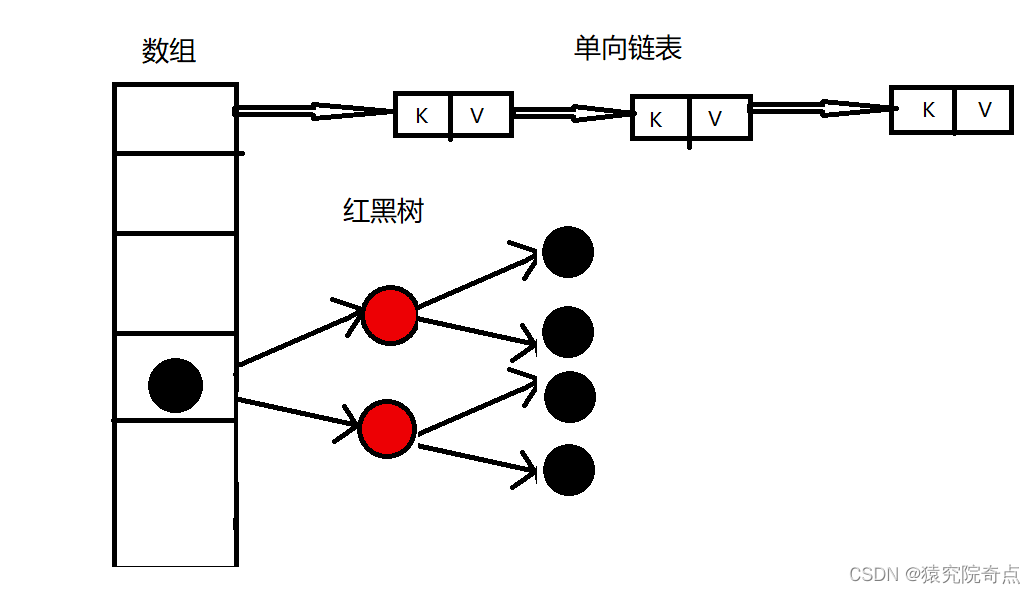
JDK1.8之后对HashMap做了一系列优化,最为重要的就是将HashMap的数据结构改为数组+单向链表+红黑树,当链表长度大于默认值8,数组长度大于64时,将链表转化为红黑树,以此优化查询时间。插入元素时采用尾插法。
三、关键参数
Node<K,V>[ ] table
保存KV键值对的数组,每个KV键值对都被封装成一个Node对象
数组容量决定了HashMap对内存的占用大小
float loadFactor
加载因子(填充因子)
加载因子默认为0.75,代表HashMap对数组容量的使用率为75%,超过该使用率,则数组需要扩容。
加载因子决定了HashMap对数组的使用率,加载因子越高,则表示允许填满的元素就越多,集合的空间利用率就越高,但是冲突的机会增加。反之,越小则冲突的机会就会越少,但空间很多就浪费了。
int threshold
扩容阈值
用于判断数组是否需要扩容
扩容阈值threshold = 数组容量 * 加载因子
size : int
KV键值对的数量
四、关键计算
hash()函数
static final int hash(Object key) {//hash()方法计算出一个hash值
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//当当前数组位置为空时,新的Entry对象可以直接放进数组中
tab[i] = newNode(hash, key, value, null);
else {
//当计算出的下标位置上有元素时
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//如果key相等,那么用新的value替换原数据
else if (p instanceof TreeNode)
//如果不相等,判断当前节点是不是TreeNode<K,V>树形节点,如果是,创作树形节点插入红黑树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果不是树形节点,则创建普通的Node<K,V>加入链表尾部
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//当链表长度大于8且数组长度大于64时,链表转换为红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();//如果当前节点数大于实际存储空间大小时,调用resize(),按照原数组的长度,扩容一倍
afterNodeInsertion(evict);
return null;
}
下标计算
JKD1.7:index = hash % 数组长度
JDK1.8:index = (数组长度 - 1) & hash,可以提高性能,但数组长度必须为2的N次幂

















 2844
2844




 到【灌水乐园】发言
到【灌水乐园】发言







