




分库分表,是企业里面比较常见的针对高并发、数据量大的场景下的一种技术优化方案,所谓"分库分表",根本就不是一件事儿,而是三件事儿,他们要解决的问题也都不一样。
这三个事儿分别是"只分库不分表"、"只分表不分库"、以及"既分库又分表"。
1.分库
分库主要解决的是并发量大的问题。因为并发量一旦上来了,那么数据库就可能会成为瓶颈,因为数据库的连接数是有限的,虽然可以调整,但是也不是无限调整的。所以,当你的数据库的读或者写的QPS过高,导致你的数据库连接数不足了的时候,就需要考虑分库了,通过增加数据库实例的方式来提供更多的可用数据库链接,从而提升系统的并发度。
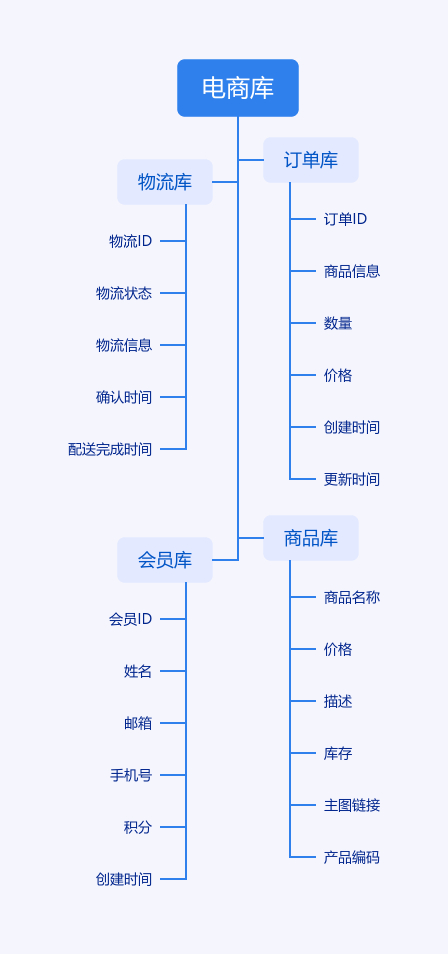
比较典型的分库的场景就是我们在做微服务拆分的时候,就会按照业务边界,把各个业务的数据从一个单一的数据库中拆分开,分别把订单、物流、商品、会员等数据,分别放到单独的数据库中。
例如:
2.分表
分表主要解决的是数据量大的问题。假如你的单表数据量非常大,因为并发不高,数据量连接可能还够,但是存储和查询的性能遇到了瓶颈了,你做了很多优化之后还是无法提升效率的时候,就需要考虑做分表了。
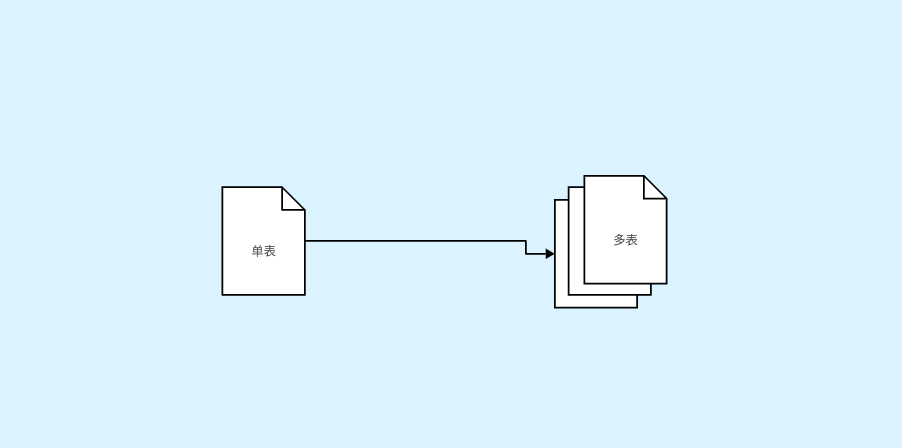
那么,当你的数据库链接也不够了,并且单表数据量也很大导致查询比较慢的时候,就需要做既分库又分表了。
3.优缺点
分库的优点:
- 提升系统吞吐量:通过将数据分散到多个数据库中,可以充分利用多个服务器的处理能力,从而提高系统的吞吐量。
- 提高数据管理效率:不同的业务或功能模块的数据拆分到不同的数据库中,数据维护更加清晰和便捷。
- 突破单一数据库的限制:解决单一数据库的性能瓶颈和数据量过大等问题,提升整个系统的稳定性和可扩展性。
分库的缺点:
- 跨库操作复杂:跨库的查询和操作需要通过中间层进行数据的整合和传输,增加了系统的复杂性和开发成本。
- 数据迁移和维护困难:在分库环境中,数据的迁移和维护需要考虑更多因素,如数据的一致性、完整性和迁移成本等。
- 事务一致性难以保证:由于数据分布在不同的数据库中,事务的一致性管理变得更加困难,需要采用分布式事务或其他解决方案。
分表的优点:
- 提高查询性能:通过将大表拆分成多个小表,可以减少单个表的数据量,提高查询性能。
- 简化数据管理:通过将数据进行归档或历史保留,或者将热点数据拆分到单独的表中,可以降低数据维护的复杂性。
- 灵活性:分表可以根据业务需求进行灵活的数据拆分和设计。
分表的缺点:
- 跨表操作复杂:跨表的查询和操作需要通过中间层进行数据的整合和传输,增加了系统的复杂性和开发成本。
- 维护成本增加:分表需要维护多个表的结构和数据关系,增加了数据库管理和维护的成本。
- 数据一致性难以保证:在分表环境中,需要更加关注数据的一致性管理,确保拆分后的表之间数据的一致性。
需要注意的是,分库和分表并不是孤立的解决方案,它们可以结合使用,取长补短,发挥更大的优势。在实际应用中,需要根据系统的需求、数据量、并发性能、数据安全性和可维护性等因素进行综合评估和选择。


















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











