




元数据即是数据的数据,是用来描述数据的,即和数据识别,产生,使用这一流向过程相关的直接的间接的所有相关的数据都可以称之为元数据,而不单单是数据表相关信息。比如:以大数据数仓常见的架构为例:
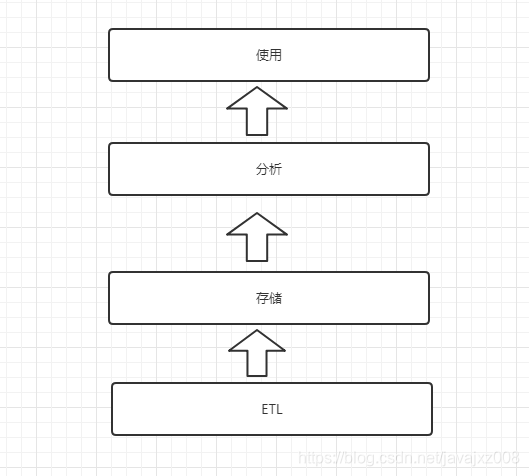
源数据通常通过ETL工具如kettle或canal或其他工具将数据抽到大数据平台中,存储在hdfs上,再经过数据分析(经典数仓按照ods->dwd->dws->ads)形成最终要使用的数据,最后通过接口或其他形式提供业务方或其他系统使用。在这一数据流转过程中,每个过程都有元数据并且在数据治理过程中发挥举足轻重的作用。
以统计销售人员销售额度为例:
user_id:销售人员ID
sales_amout:销售金额
来源表名:sales
统计SQL:select user_id,sum(sales_amout) from sales group by user_id;
1.数据源头元数据
我们知道这一统计sql数据来自sales表,如果源表sales发生某些变化,我们期望能够感知这些变化并做出相应的处理。比如,暂停统计,修改逻辑后重跑。这个时候我们就需要这些数据产生时的元数据,了解数据的变化。例如:
- 数据源来源IP和角色(主库还是从库)
- 抽取的用户名和密码
- 抽取清洗逻辑和频率
- 数据表开发系统及系统负责人
- 数据表结构和字段详细信息
- 数据表结构和字段变化记录
2.存储和分析元数据
标识数据存储的相关信息及数据加工时的信息,因为这部分数据有相同的地方,所以放在一起。比如:
- 存储格式和路径
- 产生时间和负责人
- 数据依赖关系
- 调度任务名及依赖,任务频率,任务失败重试机制
- 数据表的存储形式(增量,全量,快照,拉链,分区or不分区)
3.使用元数据
此类数据如:
- 数据使用部门或系统,使用人
- 使用形式、使用记录、使用频率
- 逻辑修改记录及负责人
有了上面的元数据,我们就可以方便的进行开发或运维,比如:
1.知晓企业数据资产及数据流向
可以知道企业一共有多少数据表,多少数据量,某个表的流向是怎么样的,使用这些表的频率和部门等等。
2.数据血缘分析和影响分析
因为有了数据依赖关系,所以上游某一环节出问题,可以分析出影响哪些下游任务。通过血缘分析可以清楚理清数据的来龙去脉。
3. 数据地图
通过可视化工具展示数据的整体流向。
元数据管理是数据治理中的核心,其本质还是为了更好的管理和利用数据。
4.数据质量控制
5.数据的生命周期
6.已有逻辑的修改和重构
构建元数据管理系统,首先要有元模型,针对异构系统产生的元数据可以通过元模型进行统一的管理和使用。其次通过自动化元数据采集工具实时采集元数据,并将采集的元数据存储起来。方便为各类数据治理应用使用。
即元模型->元数据采集->元数据存储->元数据使用,按照这一流程构建元数据管理系统。

















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









