






文章目录
- 1.ElasticSearch简介
- 2. Lucene全文检索框架
- 3. Elasticsearch中的核心概念
- 4. 安装Elasticsearch
- 5 客户端Kibana安装
- 6 安装IK分词器
- 7、指定IK分词器作为默认分词器
- 8.ES数据管理
- 9.Restful认识
- 10.查询操作
- 11.文档批量操作
- 12.DSL语言高级查询
- 13.文档映射
- 14.核心类型(Core datatype)
- 15.keyword 与 text 映射类型的区别
- 16.创建静态映射时指定text类型的ik分词器
- 17.对已存在的mapping映射进行修改
- 18.Elasticsearch乐观并发控制
- 19.Java API操作ES
- 20.ES集群环境搭建
- 21.Elasticsearch-head插件
- 22.Elasticsearch架构原理
- 23.分片和副本机制
- 24.Elasticsearch重要工作流程
- 25.Elasticsearch准实时索引实现
- 26.手工控制搜索结果精准度
- 27.经验分享
- 28.前缀搜索 prefix search
- 29.通配符搜索
- 30.正则搜索
- 31.搜索推荐
- 32.fuzzy模糊搜索技术
- 33.ElasticSearch文档分值_score计算底层原理
- 34.分词器工作流程
- 35.高亮显示
- 36.聚合搜索技术深入
- 37.es生产集群部署之针对生产集群的脑裂问题专门定制的重要参数
- 38.数据建模
- 39、根据关键字分页搜索
- 40、Elasticsearch SQL
- 41.Java API操作ES
- 42.Java API整合ElasticSearch以及Logstash、FileBeat使用
1.ElasticSearch简介
1.1 ElasticSearch(简称ES)
Elasticsearch是用Java开发并且是当前最流行的开源的企业级搜索引擎。能够达到实时搜索,稳定,可靠,快速,安装使用方便。客户端支持Java、.NET(C#)、PHP、Python、Ruby等多种语言。
官方网站: https://www.elastic.co/
下载地址:https://www.elastic.co/cn/start
1.2 ElasticSearch与Lucene的关系
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库(框架)但是想要使用Lucene,必须使用Java来作为开发语言并将其直接集成到你的应用中,并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Lucene缺点:
1)只能在Java项目中使用,并且要以jar包的方式直接集成项目中.
2)使用非常复杂-创建索引和搜索索引代码繁杂
3)不支持集群环境-索引数据不同步(不支持大型项目)
4)索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬盘.共用空间少.
上述Lucene框架中的缺点,ES全部都能解决.
1.3 哪些公司在使用Elasticsearch
- 京东
- 携程
- 去哪儿
- 58同城
- 滴滴
- 今日头条
- 小米
- 哔哩哔哩
- 联想
- GitHup
- 微软
等等…
1.4 ES vs Solr比较
1.4.1 ES vs Solr 检索速度
当单纯的对已有数据进行搜索时,Solr更快。
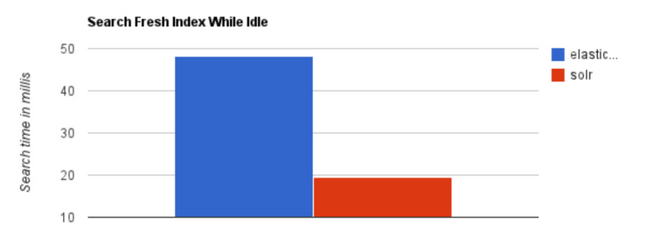
当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
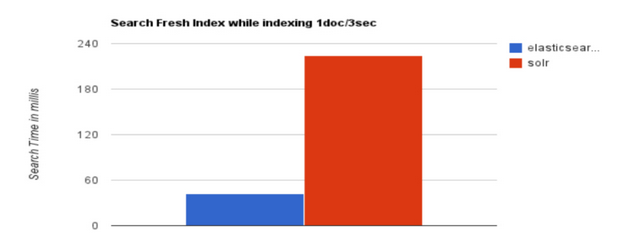
大型互联网公司,实际生产环境测试,将搜索引擎从Solr转到 Elasticsearch以后的平均查询速度有了50倍的提升。
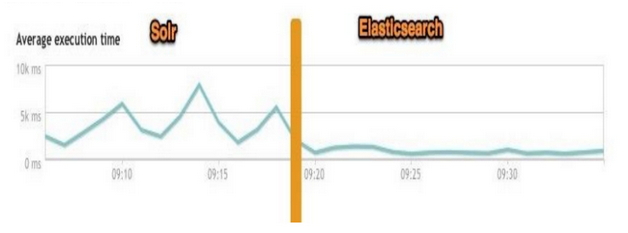
总结:
二者安装都很简单。
1、Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能。
2、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
3、Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
4、Solr 是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时搜索应用。
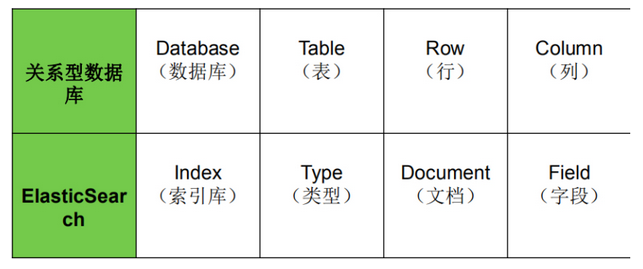
1.4.2 ES vs 关系型数据库
2. Lucene全文检索框架
2.1 什么是全文检索
通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数。用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了。
2.2 分词原理之倒排索引
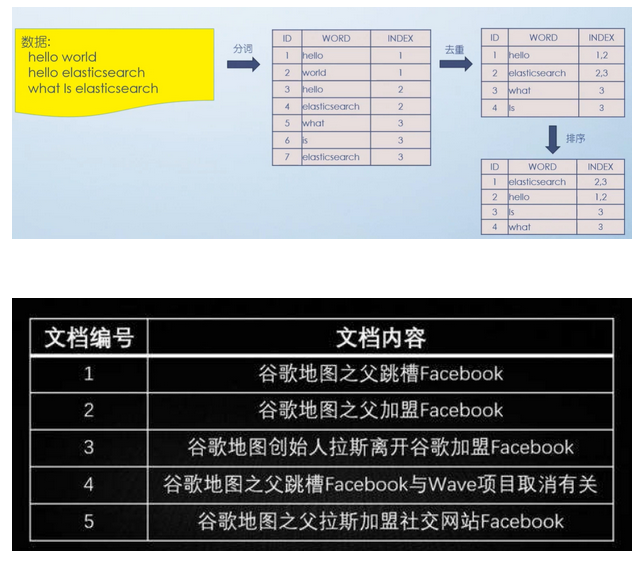
倒排索引总结:
索引就类似于目录,平时我们使用的都是索引,都是通过主键定位到某条数据,那么倒排索引呢,刚好相反,数据对应到主键。
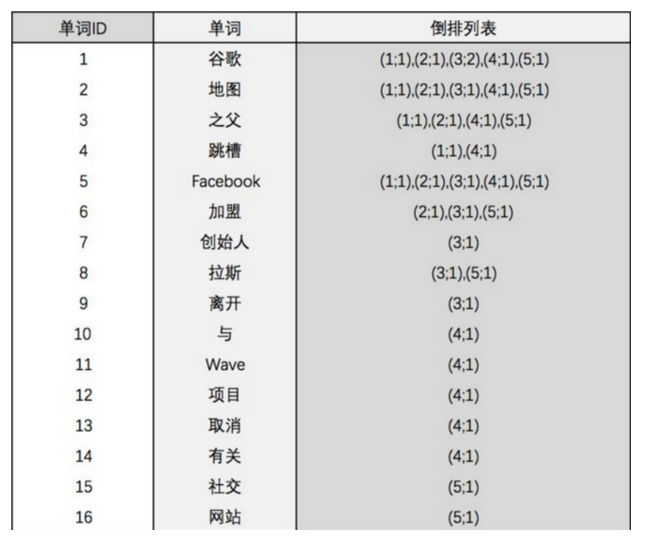
以一个博客文章的内容为例:
1.索引

2.倒排索引
假如,我们有一个站内搜索的功能,通过某个关键词来搜索相关的文章,那么这个关键词可能出现在标题中,也可能出现在文章内容中,那我们将会在创建或修改文章的时候,建立一个关键词与文章的对应关系表,这种,我们可以称之为倒排索引,因此倒排索引,也可称之为反向索引。
3. Elasticsearch中的核心概念
3.1 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
3.2 映射 mapping
ElasticSearch中的映射(Mapping)用来定义一个文档。mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的
3.3 字段Field
相当于是数据表的字段|列
3.4 字段类型 Type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
3.5 文档 document
一个文档是一个可被索引的基础信息单元,类似一条记录。文档以JSON(Javascript Object Notation)格式来表示;
3.6 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
3.7 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个“elasticsearch”的集群中。在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
3.8 分片和副本 shards&replicas
3.8.1 分片
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
当创建一个索引的时候,可以指定你想要的分片的数量,每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上,分片很重要,主要有两方面的原因:允许水平分割/扩展你的内容容量允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户来说,这些都是透明的
3.8.2 副本
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本。
副本之所以重要,有两个主要原因
- 在分片/节点失败的情况下,提供了高可用性。注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。每个索引可以被分成多个分片。一个索引有0个或者多个副本
一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引。创建的时候指定,在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量。
4. 安装Elasticsearch
软件安装包:
链接:https://pan.baidu.com/s/1XRGHX9lqF21k0gaaHv8ReA?pwd=2022
提取码:2022
–来自百度网盘超级会员V2的分享
安装es可能会出现的错误解决办法:https://blog.youkuaiyun.com/ADCadc123456789/article/details/104806771
4.1 安装Elasticsearch
4.1.1 创建普通用户
ES不能使用root用户来启动,必须使用普通用户来安装启动。这里我们创建一个普通用户以及定义一些常规目录用于存放我们的数据文件以及安装包等。
创建一个es专门的用户(必须)
使用root用户在服务器执行以下命令
先创建组, 再创建用户:
1)创建 elasticsearch 用户组
groupadd elasticsearch
2)创建用户 liaozhiwei 并设置密码
useradd liaozhiwei
passwd liaozhiwei
3)# 创建es文件夹,
并修改owner为 liaozhiwei用户
mkdir -p /usr/local/es
4)用户es 添加到 elasticsearch 用户组
usermod -G elasticsearch liaozhiwei
先上传安装包elasticsearch-7.6.1-linux-x86_64.tar.gz进行解压,解压目录为/usr/local/es,然后授权
tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz
chown -R liaozhiwei /usr/local/es/elasticsearch-7.6.1
5)设置sudo权限
#为了让普通用户有更大的操作权限,我们一般都会给普通用户设置sudo权限,方便普通用户的操作
#三台机器使用root用户执行visudo命令然后为es用户添加权限
visudo
#在root ALL=(ALL) ALL 一行下面
#添加liaozhiwei用户 如下:
liaozhiwei ALL=(ALL) ALL
#添加成功保存后切换到liaozhiwei用户操作
[root@localhost ~]# su liaozhiwei
[liaozhiwei@localhost root]$
4.1.2 上传压缩包并解压
将es的安装包下载并上传到服务器的/user/local/es路径下,然后进行解压
使用liaozhiwei用户来执行以下操作,将es安装包上传到指定服务器,并使用es用户执行以下命令解压。
# 解压Elasticsearch
su root
cd /usr/local/es/
sudo chmod 777 elasticsearch-7.6.1-linux-x86_64.tar.gz
tar -zvxf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /usr/local/es/
4.1.3 修改配置文件
4.1.3.1 修改elasticsearch.yml
进入服务器使用baiqi用户来修改配置文件
cd /usr/local/es/elasticsearch-7.6.1/config
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/data
rm -rf elasticsearch.yml
vim elasticsearch.yml
cluster.name: liaozhiwei-es
node.name: node1
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: 192.168.160.128
http.port: 9200
discovery.seed_hosts: ["192.168.160.128"]
cluster.initial_master_nodes: ["node1"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
4.1.3.2 修改jvm.option
修改jvm.option配置文件,调整jvm堆内存大小。
node1.liaozhiwei.cn使用liaozhiwei用户执行以下命令调整jvm堆内存大小,每个人根据自己服务器的内存大小来进行调整。
cd /usr/local/es/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2g
4.2 修改系统配置,解决启动时候的问题
由于现在使用普通用户来安装es服务,且es服务对服务器的资源要求比较多,包括内存大小,线程数等。所以我们需要给普通用户解开资源的束缚。
4.2.1 普通用户打开文件的最大数限制
问题错误信息描述:
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错,三台机器使用baiqi用户执行以下命令解除打开文件数据的限制。
sudo vi /etc/security/limits.conf
添加如下内容: 注意*不要去掉了
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
4.2.2 此文件修改后需要重新登录用户,才会生效
普通用户启动线程数限制
问题错误信息描述
max number of threads [1024] for user [es] likely too low, increase to at least [4096]
修改普通用户可以创建的最大线程数
max number of threads [1024] for user [es] likely too low, increase to at least [4096]
原因:无法创建本地线程问题,用户最大可创建线程数太小
解决方案:修改90-nproc.conf 配置文件。
三台机器使用baiqi用户执行以下命令修改配置文件
Centos6
sudo vi /etc/security/limits.d/90-nproc.conf
Centos7
sudo vi /etc/security/limits.d/20-nproc.conf
找到如下内容:
* soft nproc 1024#修改为
* soft nproc 4096
4.2.3 普通用户调大虚拟内存
错误信息描述:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
原因:最大虚拟内存太小,解决方案:调大系统的虚拟内存,每次启动机器都手动执行下。三台机器执行以下命令
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存后,执行:
sysctl -p
备注:以上三个问题解决完成之后,重新连接secureCRT或者重新连接xshell生效
4.2.4 设置用户密码登录
cd /usr/local/es/elasticsearch-7.6.1/bin
./elasticsearch-setup-passwords interactive
这里会设置六个账号的密码:elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user.
我这里统一使用liaozhiwei作为这六个账号的密码
elastic作为我直接访问es的账号
4.3 启动ES服务
三台机器使用liaozhiwei用户执行以下命令启动es服务
nohup /usr/local/es/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
后台启动ES 进入bin目录 ./elasticsearch -d
启动成功之后jsp即可看到es的服务进程,并且访问页面
http://192.168.160.128:9200/?pretty
上面配置了用户密码这里访问也需要输入
elastic
liaozhiwei
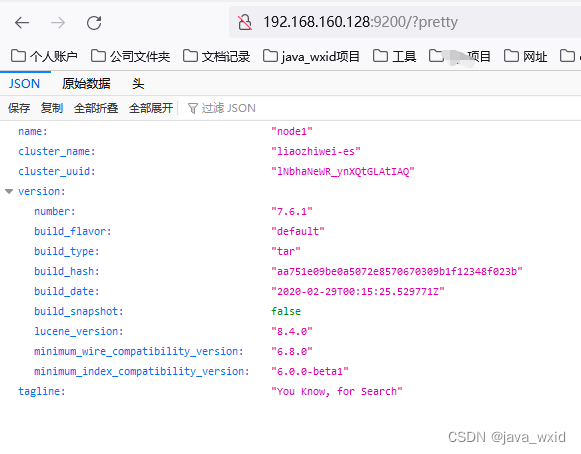
能够看到es启动之后的一些信息
注意:如果哪一台机器服务启动失败,那么就到哪一台机器的
/usr/local/es/elasticsearch-7.6.1/log
这个路径下面去查看错误日志
开启Linux防火墙
systemctl start firewalld
systemctl enable firewalld
centos开放端口宿主机访问
firewall-cmd --add-port=9200/tcp --permanent
firewall-cmd --reload
查询端口是否开启命令
firewall-cmd --query-port=9200/tcp
注意:启动ES的时候出现 Permission denied。原因:当前的用户没有对XX文件或目录的操作权限。
5 客户端Kibana安装
5.1客户端可以分为图形界面客户端,和代码客户端.
5.2 ES主流客户端Kibana,开放9200端口与图形界面客户端交互
1)下载Kibana放之/usr/local/es目录中
2)解压文件:tar -zxvf kibana-X.X.X-linux-x86_64.tar.gz
3)进入/usr/local/es/kibana-X.X.X-linux-x86_64/config目录
4)使用vi编辑器:
vi /usr/local/es/kibana-7.6.1-linux-x86_64/config/kibana.yml
server.port: 5601
server.host: "192.168.160.128"
elasticsearch.hosts: ["http://192.168.160.128:9200"]
elasticsearch.username: "kibana"
elasticsearch.password: "liaozhiwei"
i18n.locale: "zh-CN"
centos开放端口宿主机访问
firewall-cmd --add-port=5601/tcp --permanent
firewall-cmd --reload
查询端口是否开启命令
firewall-cmd --query-port=5601/tcp
切换root用户 给es用户这个文件的权限
su root
sudo chown -R liaozhiwei /usr/local/es/kibana-7.6.1-linux-x86_64
5)启动Kibana
./usr/local/es/kibana-7.6.1-linux-x86_64/bin/kibana
后台启动kibana
cd /usr/local/es/kibana-7.6.1-linux-x86_64/bin/
nohup ./kibana &
6)访问Kibana
http://192.168.160.128:5601/app/kibana
上面配置了用户密码这里访问也需要输入
elastic
liaozhiwei
6 安装IK分词器
我们后续也需要使用Elasticsearch来进行中文分词,所以需要单独给Elasticsearch安装IK分词器插件。以下为具体安装步骤:
6.1 下载Elasticsearch IK分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
6.2 切换到baiqi用户,并在es的安装目录下/plugins创建ik
mkdir -p /usr/local/es/elasticsearch-7.6.1/plugins/ik
6.3 将下载的ik分词器上传并解压到该目录
cd /usr/local/es/elasticsearch-7.6.1/plugins/ik
unzip elasticsearch-analysis-ik-7.6.1.zip
6.4 重启Elasticsearch
6.5 测试分词效果
POST _analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
#ik_smart:会做最粗粒度的拆分
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国"
}
#ik_max_word:会将文本做最细粒度的拆分
7、指定IK分词器作为默认分词器
ES的默认分词设置是standard,这个在中文分词时就比较尴尬了,会单字拆分,比如我搜索关键词“清华大学”,这时候会按“清”,“华”,“大”,“学”去分词,然后搜出来的都是些“清清的河水”,“中华儿女”,“地大物博”,“学而不思则罔”之类的莫名其妙的结果,这里我们就想把这个分词方式修改一下,于是呢,就想到了ik分词器,有两种ik_smart和ik_max_word。ik_smart会将“清华大学”整个分为一个词,而ik_max_word会将“清华大学”分为“清华大学”,“清华”和“大学”,按需选其中之一就可以了。修改默认分词方法(这里修改school_index索引的默认分词为:ik_max_word):
PUT /school_index
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
8.ES数据管理
8.1 ES数据管理概述
ES是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES使用JSON作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。
ES存储的一个员工文档的格式示例:
{
"email": "584614151@qq.com",
"name": "张三",
"age": 30,
"interests": [ "篮球", "健身" ]
}
8.2 基本操作
1) 创建索引
格式: PUT /索引名称
举例: PUT /es_db
2) 查询索引
格式: GET /索引名称
举例: GET /es_db
3) 删除索引
格式: DELETE /索引名称
举例: DELETE /es_db
4) 添加文档
格式: PUT /索引名称/类型/id
举例:
PUT /es_db/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "上海徐汇",
"remark": "java developer"
}
PUT /es_db/_doc/2
{
"name": "李四",
"sex": 1,
"age": 28,
"address": "上海黄浦",
"remark": "java assistant"
}
PUT /es_db/_doc/3
{
"name": "rod",
"sex": 0,
"age": 26,
"address": "上海浦东",
"remark": "php developer"
}
PUT /es_db/_doc/4
{
"name": "admin",
"sex": 0,
"age": 22,
"address": "陆家嘴",
"remark": "python assistant"
}
PUT /es_db/_doc/5
{
"name": "小明",
"sex": 0,
"age": 19,
"address": "东方明珠",
"remark": "java architect assistant"
}
5) 修改文档
格式: PUT /索引名称/类型/id
举例:
PUT /es_db/_doc/1
{
"name": "你廖哥",
"sex": 1,
"age": 25,
"address": "上海",
"remark": "php developer assistant"
}
注意:POST和PUT都能起到创建/更新的作用
1、需要注意的是PUT需要对一个具体的资源进行操作也就是要确定id才能进行更新/创建,而POST是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建==新文档,如果填了id那就针对这个id的文档进行创建/更新
2、PUT只会将json数据都进行替换,POST只会更新相同字段的值。
3、PUT与DELETE都是幂等性操作,即不论操作多少次, 结果都一样。
6) 查询文档
格式: GET /索引名称/类型/id
举例: GET /es_db/_doc/1
7) 删除文档
格式: DELETE /索引名称/类型/id
举例: DELETE /es_db/_doc/1
9.Restful认识
Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作。 基于Restful API ES和所有客户端的交互都是使用JSON格式的数据,其他所有程序语言都可以使用RESTful API,通过9200端口的与ES进行通信
用户做crud
Get http://localhost:8080/employee/1
Get http://localhost:8080/employees
put http://localhost:8080/employee
{
}
delete http://localhost:8080/employee/1
Post http://localhost:8080/employee/1
{
}
使用Restful的好处:透明性,暴露资源存在。充分利用 HTTP 协议本身语义,不同请求方式进行不同的操作
10.查询操作
10.1 查询当前类型中的所有文档 _search
格式: GET /索引名称/类型/_search
举例: GET /es_db/_doc/_search
SQL: select * from student
10.2 条件查询, 如要查询age等于28岁的 _search?q=:**
格式: GET /索引名称/类型/_search?q=:**
举例: GET /es_db/_doc/_search?q=age:28
SQL: select * from student where age = 28
10.3 范围查询, 如要查询age在25至26岁之间的 _search?q=*[ TO **] 注意: TO 必须为大写
格式: GET /索引名称/类型/_search?q=***[25 TO 26]
举例: GET /es_db/_doc/_search?q=age[25 TO 26]
SQL: select * from student where age between 25 and 26
10.4 根据多个ID进行批量查询 _mget
格式: GET /索引名称/类型/_mget
举例: GET /es_db/_doc/_mget
{
“ids”:[“1”,“2”]
}
SQL: select * from student where id in (1,2)
10.5 查询年龄小于等于28岁的 :<=
格式: GET /索引名称/类型/_search?q=age:<=**
举例: GET /es_db/_doc/_search?q=age:<=28
SQL: select * from student where age <= 28
10.6 查询年龄大于28前的 :>
格式: GET /索引名称/类型/_search?q=age:>**
举例: GET /es_db/_doc/_search?q=age:>28
SQL: select * from student where age > 28
10.7 分页查询 from=&size=
格式: GET /索引名称/类型/_search?q=age[25 TO 26]&from=0&size=1
举例: GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1
SQL: select * from student where age between 25 and 26 limit 0, 1
10.8 对查询结果只输出某些字段 _source=字段,字段
格式: GET /索引名称/类型/_search?_source=字段,字段
举例: GET /es_db/_doc/_search?_source=name,age
SQL: select name,age from student
10.9 对查询结果排序 sort=字段:desc/asc
格式: GET /索引名称/类型/_search?sort=字段 desc
举例: GET /es_db/_doc/_search?sort=age:desc
SQL: select * from student order by age desc
11.文档批量操作
1.批量获取文档数据
批量获取文档数据是通过_mget的API来实现的
(1)在URL中不指定index和type
请求方式:GET
请求地址:_mget
功能说明 : 可以通过ID批量获取不同index和type的数据
请求参数:
docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
GET _mget
{
"docs": [
{
"_index": "es_db",
"_type": "_doc",
"_id": 1
},
{
"_index": "es_db",
"_type": "_doc",
"_id": 2
}
]
}
响应结果如下:
{
"docs" : [
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"_seq_no" : 7,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "张三666",
"sex" : 1,
"age" : 25,
"address" : "上海徐汇",
"remark" : "java developer"
}
},
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "李四",
"sex" : 1,
"age" : 28,
"address" : "上海黄浦",
"remark" : "java assistant"
}
}
]
}
(2)在URL中指定index
请求方式:GET
请求地址:/{{indexName}}/_mget
功能说明 : 可以通过ID批量获取不同index和type的数据
请求参数:
docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
GET /es_db/_mget
{
"docs": [
{
"_type":"_doc",
"_id": 3
},
{
"_type":"_doc",
"_id": 4
}
]
}
(3)在URL中指定index和type
请求方式:GET
请求地址:/{{indexName}}/{{typeName}}/_mget
功能说明 : 可以通过ID批量获取不同index和type的数据
请求参数:
docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
GET /es_db/_doc/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 2
}
]
}
2.批量操作文档数据
批量对文档进行写操作是通过_bulk的API来实现的
请求方式:POST
请求地址:_bulk
请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
第一行参数为指定操作的类型及操作的对象(index,type和id)
第二行参数才是操作的数据
参数类似于:
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}
actionName:表示操作类型,主要有create,index,delete和update
(1)批量创建文档create
POST _bulk
{"create":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"老师1","content":"666","tags":["java", "面向对象"],"create_time":1554015482530}
{"create":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"老师2","content":"NB","tags":["java", "面向对象"],"create_time":1554015482530}
(2)普通创建或全量替换index
POST _bulk
{"index":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"老师(一)","content":"666","tags":["java", "面向对象"],"create_time":1554015482530}
{"index":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"老师(二)","content":"NB","tags":["java", "面向对象"],"create_time":1554015482530}
如果原文档不存在,则是创建
如果原文档存在,则是替换(全量修改原文档)
(3)批量删除delete
POST _bulk
{"delete":{"_index":"article", "_type":"_doc", "_id":3}}
{"delete":{"_index":"article", "_type":"_doc", "_id":4}}
(4)批量修改update
POST _bulk
{"update":{"_index":"article", "_type":"_doc", "_id":3}}
{"doc":{"title":"ES大法必修内功"}}
{"update":{"_index":"article", "_type":"_doc", "_id":4}}
{"doc":{"create_time":1554018421008}}
12.DSL语言高级查询
1.Query DSL概述
Domain Specific Language
领域专用语言
Elasticsearch provides a ful1 Query DSL based on JSON to define queries
Elasticsearch提供了基于JSON的DSL来定义查询。
DSL由叶子查询子句和复合查询子句两种子句组成。
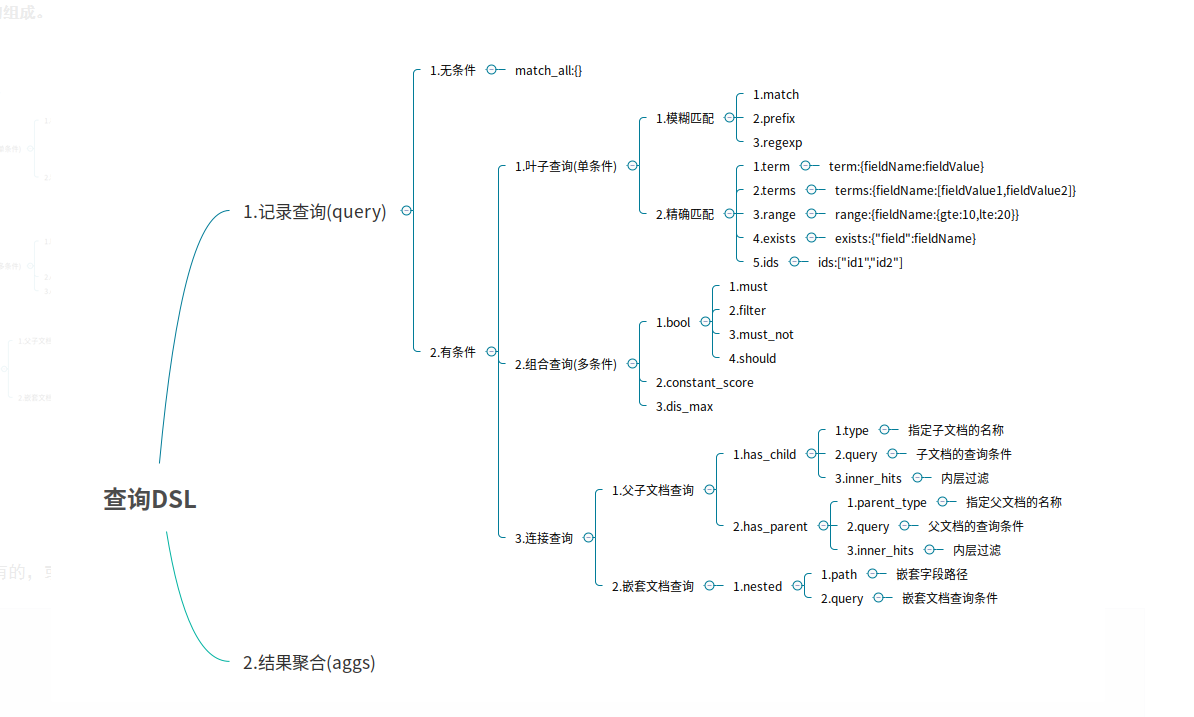
2.无查询条件
无查询条件是查询所有,默认是查询所有的,或者使用match_all表示所有
GET /es_db/_doc/_search
{
"query":{
"match_all":{}
}
}
3.有查询条件
3.1 叶子条件查询(单字段查询条件)
3.1.1 模糊匹配
模糊匹配主要是针对文本类型的字段,文本类型的字段会对内容进行分词,对查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据,模糊匹配主要通过match等参数来实现
match : 通过match关键词模糊匹配条件内容
prefix : 前缀匹配
regexp : 通过正则表达式来匹配数据
match的复杂用法
match条件还支持以下参数:
query : 指定匹配的值
operator : 匹配条件类型
and : 条件分词后都要匹配
or : 条件分词后有一个匹配即可(默认)
minmum_should_match : 指定最小匹配的数量
3.1.2 精确匹配
term : 单个条件相等
terms : 单个字段属于某个值数组内的值
range : 字段属于某个范围内的值
exists : 某个字段的值是否存在
ids : 通过ID批量查询
3.2 组合条件查询(多条件查询)
组合条件查询是将叶子条件查询语句进行组合而形成的一个完整的查询条件
bool : 各条件之间有and,or或not的关系
must : 各个条件都必须满足,即各条件是and的关系
should : 各个条件有一个满足即可,即各条件是or的关系
must_not : 不满足所有条件,即各条件是not的关系
filter : 不计算相关度评分,它不计算_score即相关度评分,效率更高
constant_score : 不计算相关度评分
must/filter/shoud/must_not 等的子条件是通过 term/terms/range/ids/exists/match 等叶子条件为参数的
注:以上参数,当只有一个搜索条件时,must等对应的是一个对象,当是多个条件时,对应的是一个数组
3.3 连接查询(多文档合并查询)
父子文档查询:parent/child
嵌套文档查询: nested
3.4 DSL查询语言中存在两种:查询DSL(query DSL)和过滤DSL(filter DSL)
它们两个的区别如下图:

query DSL
在查询上下文中,查询会回答这个问题——“这个文档匹不匹配这个查询,它的相关度高么?”
如何验证匹配很好理解,如何计算相关度呢?ES中索引的数据都会存储一个_score分值,分值越高就代表越匹配。另外关于某个搜索的分值计算还是很复杂的,因此也需要一定的时间。
filter DSL
在过滤器上下文中,查询会回答这个问题——“这个文档匹不匹配?”
答案很简单,是或者不是。它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。
过滤上下文 是在使用filter参数时候的执行环境,比如在bool查询中使用must_not或者filter
另外,经常使用过滤器,ES会自动的缓存过滤器的内容,这对于查询来说,会提高很多性能。
3.5 Query方式查询:案例
根据名称精确查询姓名 term, term查询不会对字段进行分词查询,会采用精确匹配
注意: 采用term精确查询, 查询字段映射类型属于为keyword.
举例:
POST /es_db/_doc/_search
{
"query": {
"term": {
"name": "admin"
}
}
}
SQL: select * from student where name = 'admin'
根据备注信息模糊查询 match, match会根据该字段的分词器,进行分词查询
举例:
POST /es_db/_doc/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"address": "上海"
}
}
}
SQL: select * from user where address like '%上海%' limit 0, 2
多字段模糊匹配查询与精准查询 multi_match
POST /es_db/_doc/_search
{
"query":{
"multi_match":{
"query":"张三",
"fields":["address","name"]
}
}
}
SQL: select * from student where name like '%张三%' or address like '%张三%'
未指定字段条件查询 query_string , 含 AND 与 OR 条件
POST /es_db/_doc/_search
{
"query":{
"query_string":{
"query":"北京OR 上海"
}
}
}
指定字段条件查询 query_string , 含 AND 与 OR 条件
POST /es_db/_doc/_search
{
"query":{
"query_string":{
"query":"admin OR 上海",
"fields":["name","address"]
}
}
}
范围查询
注:json请求字符串中部分字段的含义
range:范围关键字
gte 大于等于
lte 小于等于
gt 大于
lt 小于
now 当前时间
POST /es_db/_doc/_search
{
"query" : {
"range" : {
"age" : {
"gte":25,
"lte":28
}
}
}
}
SQL: select * from user where age between 25 and 28
分页、输出字段、排序综合查询
POST /es_db/_doc/_search
{
"query" : {
"range" : {
"age" : {
"gte":25,
"lte":28
}
}
},
"from": 0,
"size": 2,
"_source": ["name", "age", "book"],
"sort": {"age":"desc"}
}
3.6 Filter过滤器方式查询
它的查询不会计算相关性分值,也不会对结果进行排序, 因此效率会高一点,查询的结果可以被缓存。
Filter Context 对数据进行过滤
POST /es_db/_doc/_search
{
"query" : {
"bool" : {
"filter" : {
"term":{
"age":25
}
}
}
}
}
总结:
-
match:模糊匹配,需要指定字段名,但是输入会进行分词,比如"hello world"会进行拆分为hello和world,然后匹配,如果字段中包含hello或者world,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相对来说比较宽松。
-
term: 这种查询和match在有些时候是等价的,比如我们查询单个的词hello,那么会和match查询结果一样,但是如果查询"hello world",结果就相差很大,因为这个输入不会进行分词,就是说查询的时候,是查询字段分词结果中是否有"hello world"的字样,而不是查询字段中包含"hello world"的字样。当保存数据"hello world"时,elasticsearch会对字段内容进行分词,“hello world"会被分成hello和world,不存在"hello world”,因此这里的查询结果会为空。这也是term查询和match的区别。
-
match_phase:会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样。以"hello world"为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的,hello that world不满足,world hello也不满足条件。
-
query_string:和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
13.文档映射
ES中映射可以分为动态映射和静态映射
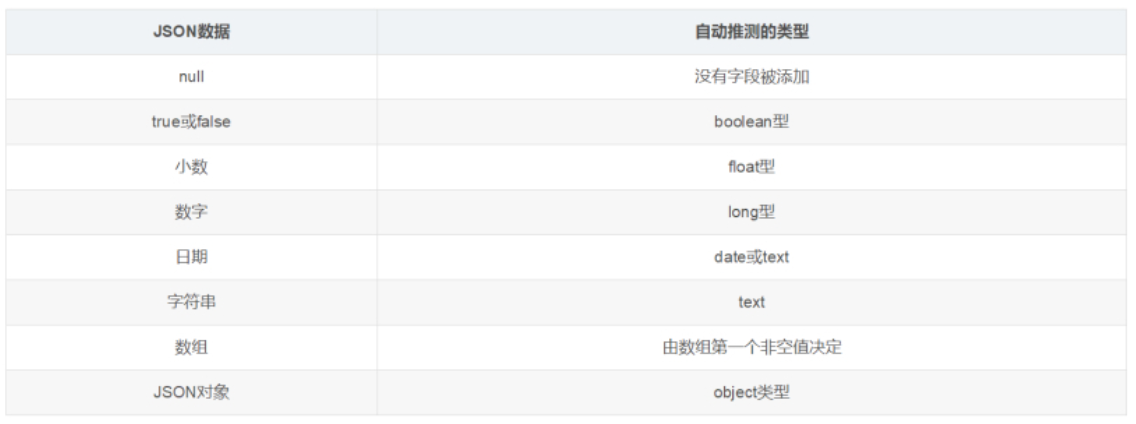
1.动态映射
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
动态映射规则如下:
1 动态映射
1.1 删除原创建的索引
DELETE /es_db
1.2 创建索引
PUT /es_db
1.3 创建文档(ES根据数据类型, 会自动创建映射)
PUT /es_db/_doc/1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "java精通",
"address": "广州"
}
1.4 获取文档映射
GET /es_db/_mapping
2.静态映射
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
2.1 删除原创建的索引
DELETE /es_db
2.2 创建索引
PUT /es_db
2.3 设置文档映射
PUT /es_db
{
"mappings":{
"properties":{
"name":{"type":"keyword","index":true,"store":true},
"sex":{"type":"integer","index":true,"store":true},
"age":{"type":"integer","index":true,"store":true},
"book":{"type":"text","index":true,"store":true},
"address":{"type":"text","index":true,"store":true}
}
}
}
2.4 根据静态映射创建文档
PUT /es_db/_doc/1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "elasticSearch入门至精通",
"address": "广州车陂"
}
2.5 获取文档映射
GET /es_db/_mapping
14.核心类型(Core datatype)
字符串:string,string类型包含 text 和 keyword。
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。
keyword:该类型不能分词,可以被用来检索过滤、排序和聚合,keyword类型不可用text进行分词模糊检索。
数值型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
15.keyword 与 text 映射类型的区别
将 book 字段设置为 keyword 映射 (只能精准查询, 不能分词查询,能聚合、排序)
POST /es_db/_doc/_search
{
"query": {
"term": {
"book": "elasticSearch入门至精通"
}
}
}
将 book 字段设置为 text 映射能模糊查询, 能分词查询,不能聚合、排序)
POST /es_db/_doc/_search
{
"query": {
"match": {
"book": "elasticSearch入门至精通"
}
}
}
16.创建静态映射时指定text类型的ik分词器
1.设置ik分词器的文档映射
先删除之前的es_db
再创建新的es_db
定义ik_smart的映射
PUT /es_db
{
"mappings":{
"properties":{
"name":{"type":"keyword","index":true,"store":true},
"sex":{"type":"integer","index":true,"store":true},
"age":{"type":"integer","index":true,"store":true},
"book":{"type":"text","index":true,"store":true,"analyzer":"ik_smart","search_analyzer":"ik_smart"},
"address":{"type":"text","index":true,"store":true}
}
}
}
2.分词查询
POST /es_db/_doc/_search
{
"query": {
"match": {"address": "广"}
}
}
POST /es_db/_doc/_search
{
"query": {
"match": {"address": "广州"}
}
}
17.对已存在的mapping映射进行修改
具体方法
1)如果要推倒现有的映射, 你得重新建立一个静态索引
2)然后把之前索引里的数据导入到新的索引里
3)删除原创建的索引
4)为新索引起个别名, 为原索引名
POST _reindex
{
"source": {
"index": "db_index"
},
"dest": {
"index": "db_index_2"
}
}
DELETE /db_index
PUT /db_index_2/_alias/db_index
注意: 通过这几个步骤就实现了索引的平滑过渡,并且是零停机
18.Elasticsearch乐观并发控制
在数据库领域中,有两种方法来确保并发更新,不会丢失数据:
1、悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
2、乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
3、再以创建一个文档为例 ES老版本
PUT /db_index/_doc/1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "Spring Boot 入门到精通",
"remark": "hello world"
}
4、实现_version乐观锁更新文档
PUT /db_index/_doc/1?version=1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "Spring Boot 入门到精通",
"remark": "hello world"
}
5、ES新版本(7.x)不使用version进行并发版本控制 if_seq_no=版本值&if_primary_term=文档位置
_seq_no:文档版本号,作用同_version
_primary_term:文档所在位置
POST /es_sc/_search
DELETE /es_sc
POST /es_sc/_doc/1
{
"id": 1,
"name": "大帅比",
"desc": "大帅比",
"create_date": "2022-02-24"
}
POST /es_sc/_update/1
{
"doc": {
"name": "大帅比666"
}
}
POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1
{
"doc": {
"name": "大帅比1"
}
}
POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1
{
"doc": {
"name": "大帅比2"
}
}
19.Java API操作ES
参考实际代码讲解
20.ES集群环境搭建
1.将安装包分发到其他服务器上面
2.修改elasticsearch.yml
node1.192.168.160.128 服务器使用baiqi用户来修改配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/data
cd /usr/local/es/elasticsearch-7.6.1/config
rm -rf elasticsearch.yml
vim elasticsearch.yml
cluster.name: baiqi-es
node.name: node1.192.168.160.128
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node1.192.168.160.128
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
3.修改jvm.option
修改jvm.option配置文件,调整jvm堆内存大小
node1.192.168.160.128使用baiqi用户执行以下命令调整jvm堆内存大小,每个人根据自己服务器的内存大小来进行调整。
cd /usr/local/es/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2g
4.node2与node3修改es配置文件
node2.centos1与node3.centos1也需要修改es配置文件
node2.centos1使用liaozhiwei用户执行以下命令修改es配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/data
cd /usr/local/es/elasticsearch-7.6.1/config
vim elasticsearch.yml
cluster.name: baiqi-es
node.name: node2.192.168.160.128
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node2.192.168.160.128
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
node3.192.168.160.128使用baiqi用户执行以下命令修改配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/data
cd /usr/local/es/elasticsearch-7.6.1/config
vim elasticsearch.yml
cluster.name: baiqi-es
node.name: node3.192.168.160.128
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node3.192.168.160.128
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
查看集群状态:
GET _cat/nodes?v
GET _cat/health?v
21.Elasticsearch-head插件
由于es服务启动之后,访问界面比较丑陋,为了更好的查看索引库当中的信息,我们可以通过安装elasticsearch-head这个插件来实现,这个插件可以更方便快捷的看到es的管理界面,elasticsearch-head这个插件是es提供的一个用于图形化界面查看的一个插件工具,可以安装上这个插件之后,通过这个插件来实现我们通过浏览器查看es当中的数据,安装elasticsearch-head这个插件这里提供两种方式进行安装,第一种方式就是自己下载源码包进行编译,耗时比较长,网络较差的情况下,基本上不可能安装成功。第二种方式就是直接使用我已经编译好的安装包,进行修改配置即可。要安装elasticsearch-head插件,需要先安装Node.js
1 安装nodejs
Node.js是一个基于 Chrome V8 引擎的 JavaScript 运行环境。Node.js是一个Javascript运行环境(runtime environment),发布于2009年5月,由Ryan Dahl开发,实质是对Chrome V8引擎进行了封装。Node.js 不是一个 JavaScript 框架,不同于CakePHP、Django、Rails。Node.js 更不是浏览器端的库,不能与 jQuery、ExtJS 相提并论。Node.js 是一个让 JavaScript 运行在服务端的开发平台,它让 JavaScript 成为与PHP、Python、Perl、Ruby 等服务端语言平起平坐的脚本语言。
1.1 下载安装包
node1.centos1机器执行以下命令下载安装包,然后进行解压
cd /usr/local/es
wget https://npm.taobao.org/mirrors/node/v8.1.0/node-v8.1.0-linux-x64.tar.gz
tar -zxvf node-v8.1.0-linux-x64.tar.gz -C /usr/local/es/
1.2 创建软连接
node1.centos1执行以下命令创建软连接
sudo ln -s /usr/local/es/node-v8.1.0-linux-x64/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm
sudo ln -s /usr/local/es/node-v8.1.0-linux-x64/bin/node /usr/local/bin/node
1.3 修改环境变量
node1.centos1服务器添加环境变量
vi /etc/profile
export NODE_HOME=/usr/local/es/node-v8.1.0-linux-x64
export PATH=:$PATH:$NODE_HOME/bin
修改完环境变量使用source生效
source /etc/profile
1.4 验证安装成功
node1.centos1执行以下命令验证安装生效
node -v
npm -v
2 本地安装
2.1 上传压缩包到/usr/local/es路径下去
将我们的压缩包 elasticsearch-head-compile-after.tar.gz 上传到服务器的/usr/local/es 路径下面去
2.2 解压安装包
在服务器中执行以下命令解压安装包
cd /usr/local/es/
tar -zxvf elasticsearch-head-compile-after.tar.gz -C /usr/local/es/
2.3 node1.192.168.160.128机器修改Gruntfile.js
修改Gruntfile.js这个文件
cd /usr/local/es/elasticsearch-head
vim Gruntfile.js
找到代码中的93行:hostname: ‘192.168.100.200’, 修改为:192.168.160.128
connect: {
server: {
options: {
hostname: '192.168.160.128',
port: 9100,
base: '.',
keepalive: true
}
}
}
2.4 node1机器修改app.js
第一台机器修改app.js
cd /usr/local/es/elasticsearch-head/_site
vim app.js
在Vim中输入「:4354」,定位到第4354行,修改 http://localhost:9200为http://192.168.160.128:9200
2.5 启动head服务
node1.centos1启动elasticsearch-head插件
cd /usr/local/es/elasticsearch-head/node_modules/grunt/bin/
进程前台启动命令
./grunt server
进程后台启动命令
nohup ./grunt server >/dev/null 2>&1 &
Running “connect:server” (connect) taskWaiting forever…Started connect web server on http://192.168.52.100:9100
如何停止:elasticsearch-head进程
执行以下命令找到elasticsearch-head的插件进程,然后使用kill -9 杀死进程即可
netstat -nltp | grep 9100
kill -9 8328
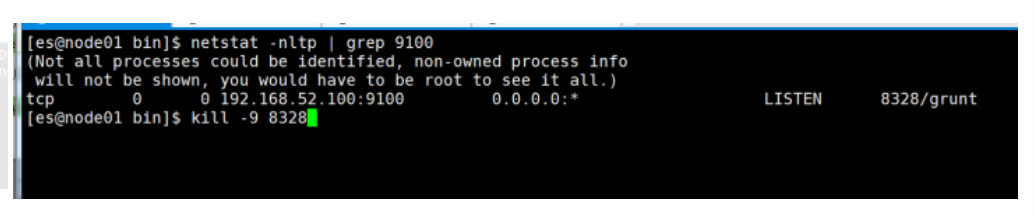
2.6 访问elasticsearch-head界面
打开Google Chrome访问
http://192.168.160.128:9100/
注意:搭建es集群,启动三个es节点,访问elasticsearch-head时只显示一个master
解决方案:进到节点2、3的/elasticsearch-7.6.1/data/目录下删除nodes文件,之后重启节点2、3的es进程即可
22.Elasticsearch架构原理
1、Elasticsearch的节点类型
在Elasticsearch主要分成两类节点,一类是Master,一类是DataNode。
1.1 Master节点
在Elasticsearch启动时,会选举出来一个Master节点。当某个节点启动后,然后使用Zen Discovery机制找到集群中的其他节点,并建立连接。
discovery.seed_hosts: [“192.168.21.130”, “192.168.21.131”, “192.168.21.132”]
并从候选主节点中选举出一个主节点。
cluster.initial_master_nodes: [“node1”, “node2”,“node3”]
Master节点主要负责:
管理索引(创建索引、删除索引)、分配分片
维护元数据
管理集群节点状态
不负责数据写入和查询,比较轻量级
一个Elasticsearch集群中,只有一个Master节点。在生产环境中,内存可以相对小一点,但机器要稳定。
1.2 DataNode节点
在Elasticsearch集群中,会有N个DataNode节点。DataNode节点主要负责:
数据写入、数据检索,大部分Elasticsearch的压力都在DataNode节点上
在生产环境中,内存最好配置大一些
23.分片和副本机制
2.1 分片(Shard)
Elasticsearch是一个分布式的搜索引擎,索引的数据也是分成若干部分,分布在不同的服务器节点中,分布在不同服务器节点中的索引数据,就是分片(Shard)。Elasticsearch会自动管理分片,如果发现分片分布不均衡,就会自动迁移,一个索引(index)由多个shard(分片)组成,而分片是分布在不同的服务器上的。
2.2 副本
为了对Elasticsearch的分片进行容错,假设某个节点不可用,会导致整个索引库都将不可用。所以,需要对分片进行副本容错。每一个分片都会有对应的副本。在Elasticsearch中,默认创建的索引为1个分片、每个分片有1个主分片和1个副本分片。
每个分片都会有一个Primary Shard(主分片),也会有若干个Replica Shard(副本分片)Primary Shard和Replica Shard不在同一个节点上。
2.3 指定分片、副本数量
创建指定分片数量、副本数量的索引
PUT /job_idx_shard_temp
{
"mappings":{
"properties":{
"id":{"type":"long","store":true},
"area":{"type":"keyword","store":true},
"exp":{"type":"keyword","store":true},
"edu":{"type":"keyword","store":true},
"salary":{"type":"keyword","store":true},
"job_type":{"type":"keyword","store":true},
"cmp":{"type":"keyword","store":true},
"pv":{"type":"keyword","store":true},
"title":{"type":"text","store":true},
"jd":{"type":"text"}
}
},
"settings":{
"number_of_shards":3,
"number_of_replicas":2
}
}
查看分片、主分片、副本分片
GET /_cat/indices?v
24.Elasticsearch重要工作流程
1 Elasticsearch文档写入原理
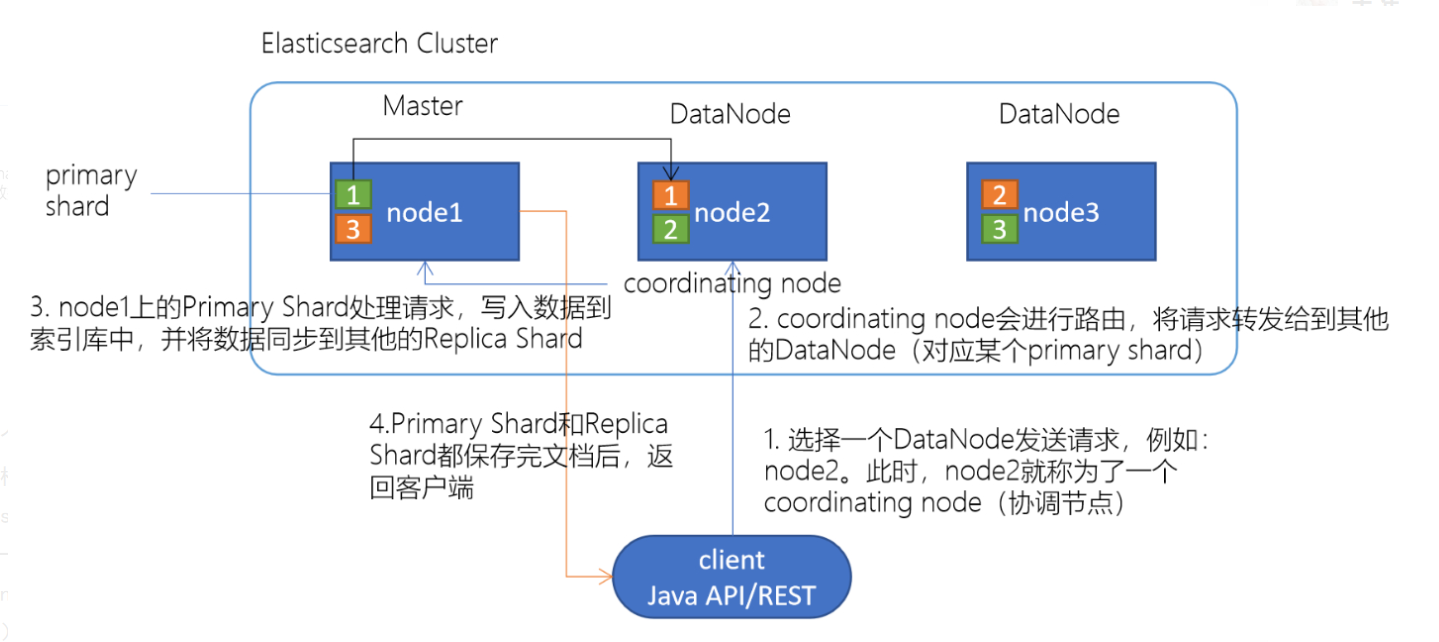 1.选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个coordinating node(协调节点)
1.选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个coordinating node(协调节点)
2.计算得到文档要写入的分片
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id
3.coordinating node会进行路由,将请求转发给对应的primary shard所在的DataNode(假设primary shard在node1、replica shard在node2)
4.node1节点上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到Replica shard
5.Primary Shard和Replica Shard都保存好了文档,返回client
2 Elasticsearch检索原理
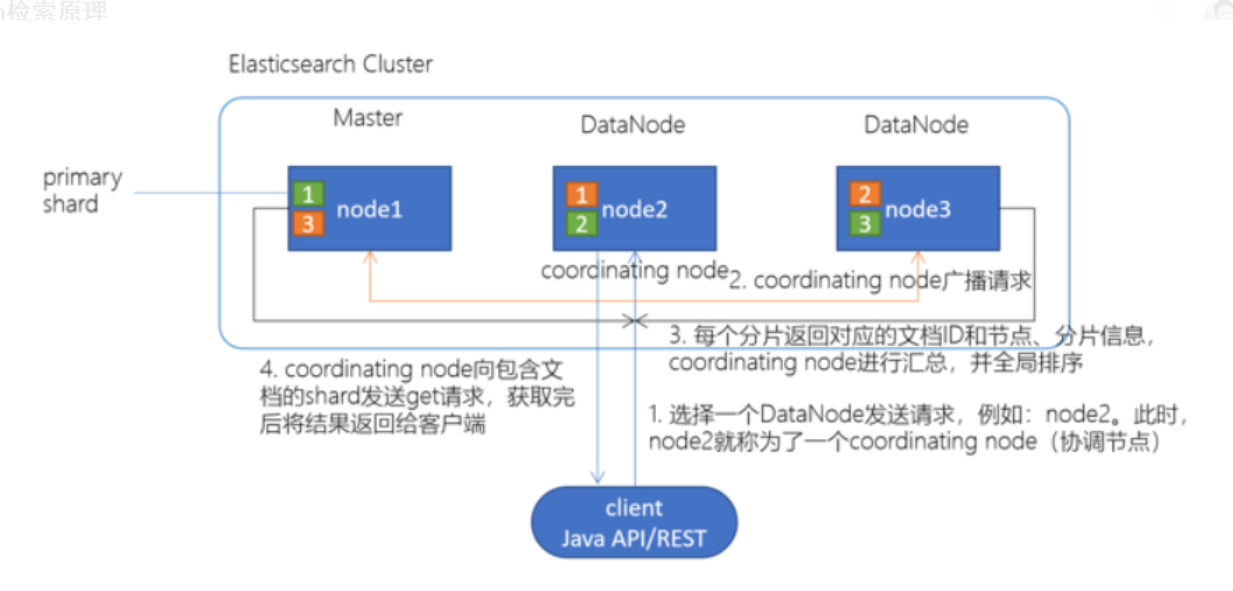 client发起查询请求,某个DataNode接收到请求,该DataNode就会成为协调节点(Coordinating Node)。协调节点(Coordinating Node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求,每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点,协调节点将所有的结果进行汇总,并进行全局排序。协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端。
client发起查询请求,某个DataNode接收到请求,该DataNode就会成为协调节点(Coordinating Node)。协调节点(Coordinating Node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求,每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点,协调节点将所有的结果进行汇总,并进行全局排序。协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端。
25.Elasticsearch准实时索引实现
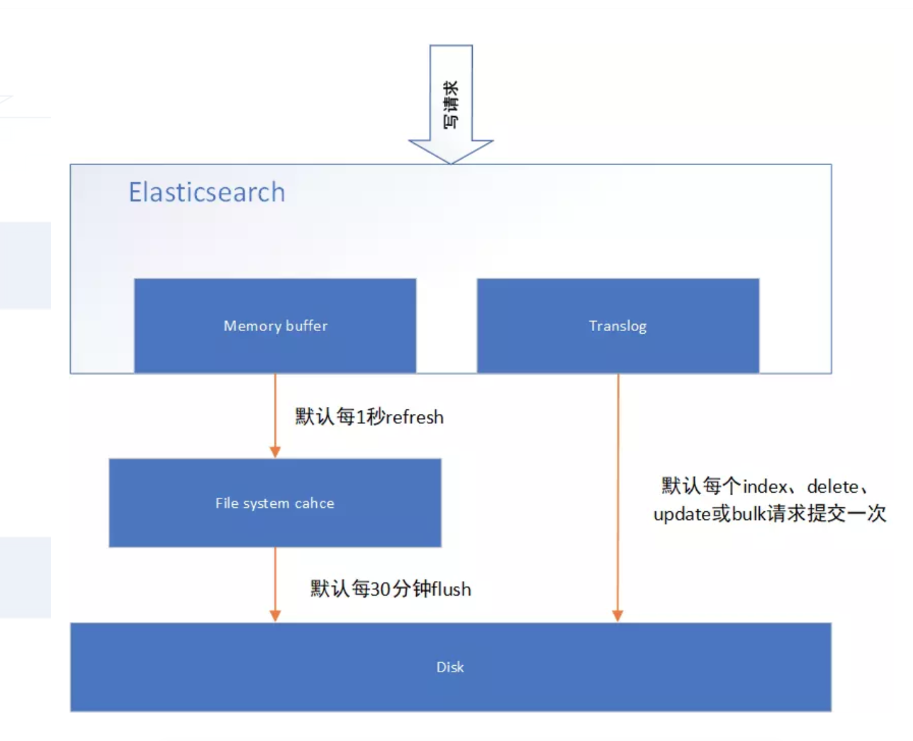
1 溢写到文件系统缓存
当数据写入到ES分片时,会首先写入到内存中,然后通过内存的buffer生成一个segment,并刷到文件系统缓存中,数据可以被检索(注意不是直接刷到磁盘),ES中默认1秒,refresh一次。
2 写translog保障容错
在写入到内存中的同时,也会记录translog日志,在refresh期间出现异常,会根据translog来进行数据恢复,等到文件系统缓存中的segment数据都刷到磁盘中,清空translog文件。
3 flush到磁盘
ES默认每隔30分钟会将文件系统缓存的数据刷入到磁盘
4 segment合并
Segment太多时,ES定期会将多个segment合并成为大的segment,减少索引查询时IO开销,此阶段ES会真正的物理删除(之前执行过的delete的数据)
26.手工控制搜索结果精准度
1.remark
如果document中的remark字段包含java或developer词组,都符合搜索条件。
GET /es_db/_search
{
"query": {
"match": {
"remark": "java developer"
}
}
}
如果需要搜索的document中的remark字段,包含java和developer词组,则需要使用下述语法:
GET /es_db/_search
{
"query": {
"match": {
"remark": {
"query": "java developer",
"operator": "and"
}
}
}
}
上述语法中,如果将operator的值改为or。则与第一个案例搜索语法效果一致。默认的ES执行搜索的时候,operator就是or。
如果在搜索的结果document中,需要remark字段中包含多个搜索词条中的一定比例,可以使用下述语法实现搜索。其中minimum_should_match可以使用百分比或固定数字。百分比代表query搜索条件中词条百分比,如果无法整除,向下匹配(如,query条件有3个单词,如果使用百分比提供精准度计算,那么是无法除尽的,如果需要至少匹配两个单词,则需要用67%来进行描述。如果使用66%描述,ES则认为匹配一个单词即可。)。固定数字代表query搜索条件中的词条,至少需要匹配多少个。
GET /es_db/_search
{
"query": {
"match": {
"remark": {
"query": "java architect assistant",
"minimum_should_match": "68%"
}
}
}
}
如果使用should+bool搜索的话,也可以控制搜索条件的匹配度。具体如下:下述案例代表搜索的document中的remark字段中,必须匹配java、developer、assistant三个词条中的至少2个。
GET /es_db/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"remark": "java"
}
},
{
"match": {
"remark": "developer"
}
},
{
"match": {
"remark": "assistant"
}
}
],
"minimum_should_match": 2
}
}
}
2.match 的底层转换
其实在ES中,执行match搜索的时候,ES底层通常都会对搜索条件进行底层转换,来实现最终的搜索结果。如:
GET /es_db/_search
{
"query": {
"match": {
"remark": "java developer"
}
}
}
转换后是:
GET /es_db/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"remark": "java"
}
},
{
"term": {
"remark": {
"value": "developer"
}
}
}
]
}
}
}
GET /es_db/_search
{
"query": {
"match": {
"remark": {
"query": "java developer",
"operator": "and"
}
}
}
}
转换后是:
GET /es_db/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"remark": "java"
}
},
{
"term": {
"remark": {
"value": "developer"
}
}
}
]
}
}
}
GET /es_db/_search
{
"query": {
"match": {
"remark": {
"query": "java architect assistant",
"minimum_should_match": "68%"
}
}
}
}
转换后为:
GET /es_db/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"remark": "java"
}
},
{
"term": {
"remark": "architect"
}
},
{
"term": {
"remark": "assistant"
}
}
],
"minimum_should_match": 2
}
}
}
如果不怕麻烦,尽量使用转换后的语法执行搜索,效率更高。
如果开发周期短,工作量大,使用简化的写法。
3.boost权重控制
搜索document中remark字段中包含java的数据,如果remark中包含developer或architect,则包含architect的document优先显示。(就是将architect数据匹配时的相关度分数增加)。一般用于搜索时相关度排序使用。如:电商中的综合排序。将一个商品的销量,广告投放,评价值,库存,单价比较综合排序。在上述的排序元素中,广告投放权重最高,库存权重最低。
GET /es_db/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"remark": "java"
}
}
],
"should": [
{
"match": {
"remark": {
"query": "developer",
"boost" : 1
}
}
},
{
"match": {
"remark": {
"query": "architect",
"boost" : 3
}
}
}
]
}
}
}
4.基于dis_max实现best fields策略进行多字段搜索
best fields策略: 搜索的document中的某一个field,尽可能多的匹配搜索条件。与之相反的是,尽可能多的字段匹配到搜索条件(most fields策略)。如百度搜索使用这种策略。
优点:精确匹配的数据可以尽可能的排列在最前端,且可以通过minimum_should_match来去除长尾数据,避免长尾数据字段对排序结果的影响。长尾数据比如说我们搜索4个关键词,但很多文档只匹配1个,也显示出来了,这些文档其实不是我们想要的
缺点:相对排序不均匀。
dis_max语法: 直接获取搜索的多条件中的,单条件query相关度分数最高的数据,以这个数据做相关度排序。
下述的案例中,就是找name字段中rod匹配相关度分数或remark字段中java developer匹配相关度分数,哪个高,就使用哪一个相关度分数进行结果排序。
GET /es_db/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"name": "rod"
}
},
{
"match": {
"remark": "java developer"
}
}
]
}
}
}
5.基于tie_breaker参数优化dis_max搜索效果
dis_max是将多个搜索query条件中相关度分数最高的用于结果排序,忽略其他query分数,在某些情况下,可能还需要其他query条件中的相关度介入最终的结果排序,这个时候可以使用tie_breaker参数来优化dis_max搜索。tie_breaker参数代表的含义是:将其他query搜索条件的相关度分数乘以参数值,再参与到结果排序中。如果不定义此参数,相当于参数值为0。所以其他query条件的相关度分数被忽略。
GET /es_db/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"name": "rod"
}
},
{
"match": {
"remark": "java developer"
}
}
],
"tie_breaker":0.5
}
}
}
6.使用multi_match简化dis_max+tie_breaker
ES中相同结果的搜索也可以使用不同的语法语句来实现。不需要特别关注,只要能够实现搜索,就是完成任务!
如:
GET /es_db/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"name": "rod"
}
},
{
"match": {
"remark": {
"query": "java developer",
"boost" : 2,
"minimum_should_match": 2
}
}
}
],
"tie_breaker": 0.5
}
}
}
使用multi_match语法为:其中type常用的有best_fields和most_fields。^n代表权重,相当于"boost":n。
GET /es_db/_search
{
"query": {
"multi_match": {
"query": "rod java developer",
"fields": ["name", "remark^2"],
"type": "best_fields",
"tie_breaker": 0.5,
"minimum_should_match" : "50%"
}
}
}
7.cross fields搜索
cross fields : 一个唯一的标识,分部在多个fields中,使用这种唯一标识搜索数据就称为cross fields搜索。如:人名可以分为姓和名,地址可以分为省、市、区县、街道等。那么使用人名或地址来搜索document,就称为cross fields搜索。
实现这种搜索,一般都是使用most fields搜索策略。因为这就不是一个field的问题。
Cross fields搜索策略,是从多个字段中搜索条件数据。默认情况下,和most fields搜索的逻辑是一致的,计算相关度分数是和best fields策略一致的。一般来说,如果使用cross fields搜索策略,那么都会携带一个额外的参数operator。用来标记搜索条件如何在多个字段中匹配。
当然,在ES中也有cross fields搜索策略。具体语法如下:
GET /es_db/_search
{
"query": {
"multi_match": {
"query": "java developer",
"fields": ["name", "remark"],
"type": "cross_fields",
"operator" : "and"
}
}
}
上述语法代表的是,搜索条件中的java必须在name或remark字段中匹配,developer也必须在name或remark字段中匹配。
most field策略问题:most fields策略是尽可能匹配更多的字段,所以会导致精确搜索结果排序问题。又因为cross fields搜索,不能使用minimum_should_match来去除长尾数据。
所以在使用most fields和cross fields策略搜索数据的时候,都有不同的缺陷。所以商业项目开发中,都推荐使用best fields策略实现搜索。
8.copy_to组合fields
京东中,如果在搜索框中输入“手机”,点击搜索,那么是在商品的类型名称、商品的名称、商品的卖点、商品的描述等字段中,哪一个字段内进行数据的匹配?如果使用某一个字段做搜索不合适,那么使用_all做搜索是否合适?也不合适,因为_all字段中可能包含图片,价格等字段。
假设,有一个字段,其中的内容包括(但不限于):商品类型名称、商品名称、商品卖点等字段的数据内容。是否可以在这个特殊的字段上进行数据搜索匹配?
{
"category_name" : "手机",
"product_name" : "一加6T手机",
"price" : 568800,
"sell_point" : "国产最好的Android手机",
"tags": ["8G+128G", "256G可扩展"],
"color" : "红色",
"keyword" : "手机 一加6T手机 国产最好的Android手机"
}
copy_to : 就是将多个字段,复制到一个字段中,实现一个多字段组合。copy_to可以解决cross fields搜索问题,在商业项目中,也用于解决搜索条件默认字段问题。
如果需要使用copy_to语法,则需要在定义index的时候,手工指定mapping映射策略。
copy_to语法:
PUT /es_db/_mapping
{
"properties": {
"provice" : {
"type": "text",
"analyzer": "standard",
"copy_to": "address"
},
"city" : {
"type": "text",
"analyzer": "standard",
"copy_to": "address"
},
"street" : {
"type": "text",
"analyzer": "standard",
"copy_to": "address"
},
"address" : {
"type": "text",
"analyzer": "standard"
}
}
}
上述的mapping定义中,是新增了4个字段,分别是provice、city、street、address,其中provice、city、street三个字段的值,会自动复制到address字段中,实现一个字段的组合。那么在搜索地址的时候,就可以在address字段中做条件匹配,从而避免most fields策略导致的问题。在维护数据的时候,不需对address字段特殊的维护。因为address字段是一个组合字段,是由ES自动维护的。类似java代码中的推导属性。在存储的时候,未必存在,但是在逻辑上是一定存在的,因为address是由3个物理存在的属性province、city、street组成的。
9.近似匹配
前文都是精确匹配。如doc中有数据java assistant,那么搜索jave是搜索不到数据的。因为jave单词在doc中是不存在的。
如果搜索的语法是:
GET _search
{
"query" : {
"match" : {
"name" : "jave"
}
}
}
如果需要的结果是有特殊要求,如:hello world必须是一个完整的短语,不可分割;或document中的field内,包含的hello和world单词,且两个单词之间离的越近,相关度分数越高。那么这种特殊要求的搜索就是近似搜索。包括hell搜索条件在hello world数据中搜索,包括h搜索提示等都数据近似搜索的一部分。
如何上述特殊要求的搜索,使用match搜索语法就无法实现了。
10.match phrase
短语搜索。就是搜索条件不分词。代表搜索条件不可分割。
如果hello world是一个不可分割的短语,我们可以使用前文学过的短语搜索match phrase来实现。语法如下:
GET _search
{
"query": {
"match_phrase": {
"remark": "java assistant"
}
}
}
-1)、 match phrase原理 – term position
ES是如何实现match phrase短语搜索的?其实在ES中,使用match phrase做搜索的时候,也是和match类似,首先对搜索条件进行分词-analyze。将搜索条件拆分成hello和world。既然是分词后再搜索,ES是如何实现短语搜索的?
这里涉及到了倒排索引的建立过程。在倒排索引建立的时候,ES会先对document数据进行分词,如:
GET _analyze
{
"text": "hello world, java spark",
"analyzer": "standard"
}
分词的结果是:
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "java",
"start_offset": 13,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "spark",
"start_offset": 18,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 3
}
]
}
从上述结果中,可以看到。ES在做分词的时候,除了将数据切分外,还会保留一个position。position代表的是这个词在整个数据中的下标。当ES执行match phrase搜索的时候,首先将搜索条件hello world分词为hello和world。然后在倒排索引中检索数据,如果hello和world都在某个document的某个field出现时,那么检查这两个匹配到的单词的position是否是连续的,如果是连续的,代表匹配成功,如果是不连续的,则匹配失败。
-2). match phrase搜索参数 – slop
在做搜索操作的是,如果搜索参数是hello spark。而ES中存储的数据是hello world, java spark。那么使用match phrase则无法搜索到。在这个时候,可以使用match来解决这个问题。但是,当我们需要在搜索的结果中,做一个特殊的要求:hello和spark两个单词距离越近,document在结果集合中排序越靠前,这个时候再使用match则未必能得到想要的结果。
ES的搜索中,对match phrase提供了参数slop。slop代表match phrase短语搜索的时候,单词最多移动多少次,可以实现数据匹配。在所有匹配结果中,多个单词距离越近,相关度评分越高,排序越靠前。
这种使用slop参数的match phrase搜索,就称为近似匹配(proximity search)
如:
数据为: hello world, java spark
搜索为: match phrase : hello spark。
slop为: 3 (代表单词最多移动3次。)
执行短语搜索的时候,将条件hello spark分词为hello和spark两个单词。并且连续。
hello spark
接下来,可以根据slop参数执行单词的移动。
下标 : 0 1 2 3
doc : hello world java spark
搜索 : hello spark
移动1: hello spark
移动2: hello spark
匹配成功,不需要移动第三次即可匹配。
如果:
数据为: hello world, java spark
搜索为: match phrase : spark hello。
slop为: 5 (代表单词最多移动5次。)
执行短语搜索的时候,将条件hello spark分词为hello和spark两个单词。并且连续。
spark hello
接下来,可以根据slop参数执行单词的移动。
下标 : 0 1 2 3
doc : hello world java spark
搜索 : spark hello
移动1: spark/hello
移动2: hello spark
移动3: hello spark
移动4: hello spark
匹配成功,不需要移动第五次即可匹配。
如果当slop移动次数使用完毕,还没有匹配成功,则无搜索结果。如果使用中文分词,则移动次数更加复杂,因为中文词语有重叠情况,很难计算具体次数,需要多次尝试才行。
测试案例:
英文:
GET _analyze
{
"text": "hello world, java spark",
"analyzer": "standard"
}
POST /test_a/_doc/3
{
"f" : "hello world, java spark"
}
GET /test_a/_search
{
"query": {
"match_phrase": {
"f" : {
"query": "hello spark",
"slop" : 2
}
}
}
}
GET /test_a/_search
{
"query": {
"match_phrase": {
"f" : {
"query": "spark hello",
"slop" : 4
}
}
}
}
中文:
GET _analyze
{
"text": "中国,一个世界上最强的国家",
"analyzer": "ik_max_word"
}
POST /test_a/_doc/1
{
"f" : "中国,一个世界上最强的国家"
}
GET /test_a/_search
{
"query": {
"match_phrase": {
"f" : {
"query": "中国最强",
"slop" : 5
}
}
}
}
GET /test_a/_search
{
"query": {
"match_phrase": {
"f" : {
"query": "最强中国",
"slop" : 9
}
}
}
}
27.经验分享
使用match和proximity search实现召回率和精准度平衡。
召回率:召回率就是搜索结果比率,如:索引A中有100个document,搜索时返回多少个document,就是召回率(recall)。
精准度:就是搜索结果的准确率,如:搜索条件为hello java,在搜索结果中尽可能让短语匹配和hello java离的近的结果排序靠前,就是精准度(precision)。
如果在搜索的时候,只使用match phrase语法,会导致召回率底下,因为搜索结果中必须包含短语(包括proximity search)。
如果在搜索的时候,只使用match语法,会导致精准度底下,因为搜索结果排序是根据相关度分数算法计算得到。
那么如果需要在结果中兼顾召回率和精准度的时候,就需要将match和proximity search混合使用,来得到搜索结果。
测试案例:
POST /test_a/_doc/3
{
"f" : "hello, java is very good, spark is also very good"
}
POST /test_a/_doc/4
{
"f" : "java and spark, development language "
}
POST /test_a/_doc/5
{
"f" : "Java Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs."
}
POST /test_a/_doc/6
{
"f" : "java spark and, development language "
}
GET /test_a/_search
{
"query": {
"match": {
"f": "java spark"
}
}
}
GET /test_a/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"f": "java spark"
}
}
],
"should": [
{
"match_phrase": {
"f": {
"query": "java spark",
"slop" : 50
}
}
}
]
}
}
}
28.前缀搜索 prefix search
使用前缀匹配实现搜索能力。通常针对keyword类型字段,也就是不分词的字段。
语法:
GET /test_a/_search
{
"query": {
"prefix": {
"f.keyword": {
"value": "J"
}
}
}
}
注意:针对前缀搜索,是对keyword类型字段而言。而keyword类型字段数据大小写敏感。
前缀搜索效率比较低。前缀搜索不会计算相关度分数。前缀越短,效率越低。如果使用前缀搜索,建议使用长前缀。因为前缀搜索需要扫描完整的索引内容,所以前缀越长,相对效率越高。
29.通配符搜索
ES中也有通配符。但是和java还有数据库不太一样。通配符可以在倒排索引中使用,也可以在keyword类型字段中使用。
常用通配符:
? - 一个任意字符
-
- 0~n个任意字符
GET /test_a/_search
{
"query": {
"wildcard": {
"f.keyword": {
"value": "?e*o*"
}
}
}
}
性能也很低,也是需要扫描完整的索引。不推荐使用。
30.正则搜索
ES支持正则表达式。可以在倒排索引或keyword类型字段中使用。
常用符号:
[] - 范围,如: [0-9]是0~9的范围数字
. - 一个字符
+ - 前面的表达式可以出现多次。
GET /test_a/_search
{
"query": {
"regexp" : {
"f.keyword" : "[A-z].+"
}
}
}
性能也很低,需要扫描完整索引。
31.搜索推荐
搜索推荐: search as your type, 搜索提示。如:索引中有若干数据以“hello”开头,那么在输入hello的时候,推荐相关信息。(类似百度输入框)
语法:
GET /test_a/_search
{
"query": {
"match_phrase_prefix": {
"f": {
"query": "java s",
"slop" : 10,
"max_expansions": 10
}
}
}
}
其原理和match phrase类似,是先使用match匹配term数据(java),然后在指定的slop移动次数范围内,前缀匹配(s),max_expansions是用于指定prefix最多匹配多少个term(单词),超过这个数量就不再匹配了。
这种语法的限制是,只有最后一个term会执行前缀搜索。
执行性能很差,毕竟最后一个term是需要扫描所有符合slop要求的倒排索引的term。
因为效率较低,如果必须使用,则一定要使用参数max_expansions。
32.fuzzy模糊搜索技术
搜索的时候,可能搜索条件文本输入错误,如:hello world -> hello word。这种拼写错误还是很常见的。fuzzy技术就是用于解决错误拼写的(在英文中很有效,在中文中几乎无效。)。其中fuzziness代表value的值word可以修改多少个字母来进行拼写错误的纠正(修改字母的数量包含字母变更,增加或减少字母。)。f代表要搜索的字段名称。
GET /test_a/_search
{
"query": {
"fuzzy": {
"f" : {
"value" : "word",
"fuzziness": 2
}
}
}
}
33.ElasticSearch文档分值_score计算底层原理
1)boolean model
根据用户的query条件,先过滤出包含指定term的doc
query “hello world” --> hello / world / hello & world
bool --> must/must not/should --> 过滤 --> 包含 / 不包含 / 可能包含
doc --> 不打分数 --> 正或反 true or false --> 为了减少后续要计算的doc的数量,提升性能
2)relevance score算法
简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度
Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法
1.Term frequency
搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
搜索请求:hello world
doc1:hello you, and world is very good
doc2:hello, how are you
2.Inverse document frequency
搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关
搜索请求:hello world
doc1:hello, tuling is very good
doc2:hi world, how are you
比如说,在index中有1万条document,hello这个单词在所有的document中,一共出现了1000次;world这个单词在所有的document中,一共出现了100次
3)Field-length norm
field长度,field越长,相关度越弱
搜索请求:hello world
doc1:{ "title": "hello article", "content": "...... N个词" }
doc2:{ "title": "my article", "content": "...... N个词,hi world" }
hello world在整个index中出现的次数是一样多的
doc1更相关,title field更短
4)分析一个document上的_score是如何被计算出来的
GET /es_db/_doc/1/_explain
{
"query": {
"match": {
"remark": "java developer"
}
}
}
5)vector space model
多个term对一个doc的总分数
hello world --> es会根据hello world在所有doc中的评分情况,计算出一个query vector,query向量
hello这个term,给的基于所有doc的一个评分就是3
world这个term,给的基于所有doc的一个评分就是6
[3, 6]
query vector
doc vector,3个doc,一个包含hello,一个包含world,一个包含hello 以及 world
3个doc
doc1:包含hello --> [3, 0]
doc2:包含world --> [0, 6]
doc3:包含hello, world --> [3, 6]
会给每一个doc,拿每个term计算出一个分数来,hello有一个分数,world有一个分数,再拿所有term的分数组成一个doc vector
画在一个图中,取每个doc vector对query vector的弧度,给出每个doc对多个term的总分数
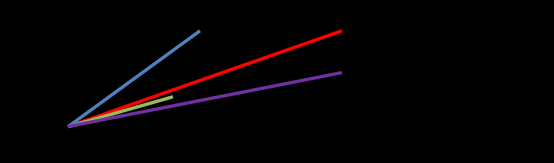
每个doc vector计算出对query vector的弧度,最后基于这个弧度给出一个doc相对于query中多个term的总分数
弧度越大,分数月底; 弧度越小,分数越高
如果是多个term,那么就是线性代数来计算,无法用图表示
34.分词器工作流程
1、切分词语,normalization
给你一段句子,然后将这段句子拆分成一个一个的单个的单词,同时对每个单词进行normalization(时态转换,单复数转换),分词器
recall,召回率:搜索的时候,增加能够搜索到的结果的数量
character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello --> hello),& --> and(I&you --> I and you)
tokenizer:分词,hello you and me --> hello, you, and, me
token filter:lowercase,stop word,synonymom,liked --> like,Tom --> tom,a/the/an --> 干掉,small --> little
一个分词器,很重要,将一段文本进行各种处理,最后处理好的结果才会拿去建立倒排索引
2、内置分词器的介绍
Set the shape to semi-transparent by calling set_trans(5)
standard analyzer:set, the, shape, to, semi, transparent, by, calling, set_trans, 5(默认的是standard)
simple analyzer:set, the, shape, to, semi, transparent, by, calling, set, trans
whitespace analyzer:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
stop analyzer:移除停用词,比如a the it等等
测试:
POST _analyze
{
"analyzer":"standard",
"text":"Set the shape to semi-transparent by calling set_trans(5)"
}
3、定制分词器
1)默认的分词器
standard
standard tokenizer:以单词边界进行切分
standard token filter:什么都不做
lowercase token filter:将所有字母转换为小写
stop token filer(默认被禁用):移除停用词,比如a the it等等
2)修改分词器的设置
启用english停用词token filter
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
GET /my_index/_analyze
{
"analyzer": "standard",
"text": "a dog is in the house"
}
GET /my_index/_analyze
{
"analyzer": "es_std",
"text":"a dog is in the house"
}
3)定制化自己的分词器
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and"]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "a"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["html_strip", "&_to_and"],
"tokenizer": "standard",
"filter": ["lowercase", "my_stopwords"]
}
}
}
}
}
GET /my_index/_analyze
{
"text": "tom&jerry are a friend in the house, <a>, HAHA!!",
"analyzer": "my_analyzer"
}
PUT /my_index/_mapping/my_type
{
"properties": {
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
4)ik分词器详解
ik配置文件地址:es/plugins/ik/config目录
IKAnalyzer.cfg.xml:用来配置自定义词库
main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起
quantifier.dic:放了一些单位相关的词
suffix.dic:放了一些后缀
surname.dic:中国的姓氏
stopword.dic:英文停用词
ik原生最重要的两个配置文件
main.dic:包含了原生的中文词语,会按照这个里面的词语去分词
stopword.dic:包含了英文的停用词,一般,像停用词,会在分词的时候,直接被干掉,不会建立在倒排索引中
5)IK分词器自定义词库
(1)自己建立词库
每年都会涌现一些特殊的流行词,网红,蓝瘦香菇,喊麦,鬼畜,一般不会在ik的原生词典里。自己补充自己的最新的词语,到ik的词库里面去。IKAnalyzer.cfg.xml:ext_dict,custom/mydict.dic补充自己的词语,然后需要重启es,才能生效
(2)自己建立停用词库
比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索。custom/ext_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,然后重启es。IK分词器源码下载:https://github.com/medcl/elasticsearch-analysis-ik/tree
6)IK热更新
每次都是在es的扩展词典中,手动添加新词语,很坑
(1)每次添加完,都要重启es才能生效,非常麻烦
(2)es是分布式的,可能有数百个节点,你不能每次都一个一个节点上面去修改
es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载到这些新词语
IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">location</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">location</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">words_location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">words_location</entry>
</properties>
35.高亮显示
在搜索中,经常需要对搜索关键字做高亮显示,高亮显示也有其常用的参数,在这个案例中做一些常用参数的介绍。
现在搜索cars索引中remark字段中包含“大众”的document。并对“XX关键字”做高亮显示,高亮效果使用html标签,并设定字体为红色。如果remark数据过长,则只显示前20个字符。
PUT /news_website
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
PUT /news_website
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
PUT /news_website/_doc/1
{
"title": "这是我写的第一篇文章",
"content": "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"
}
GET /news_website/_doc/_search
{
"query": {
"match": {
"title": "文章"
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
{
"took" : 458,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "news_website",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"title" : "我的第一篇文章",
"content" : "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"
},
"highlight" : {
"title" : [
"我的第一篇<em>文章</em>"
]
}
}
]
}
}
<em></em>表现,会变成红色,所以说你的指定的field中,如果包含了那个搜索词的话,就会在那个field的文本中,对搜索词进行红色的高亮显示
GET /news_website/_doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "文章"
}
},
{
"match": {
"content": "文章"
}
}
]
}
},
"highlight": {
"fields": {
"title": {},
"content": {}
}
}
}
highlight中的field,必须跟query中的field一一对齐的
常用的highlight介绍
plain highlight,lucene highlight,默认
posting highlight,index_options=offsets
(1)性能比plain highlight要高,因为不需要重新对高亮文本进行分词
(2)对磁盘的消耗更少
DELETE news_website
PUT /news_website
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"index_options": "offsets"
}
}
}
}
PUT /news_website/_doc/1
{
"title": "我的第一篇文章",
"content": "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"
}
GET /news_website/_doc/_search
{
"query": {
"match": {
"content": "文章"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}
fast vector highlight
index-time term vector设置在mapping中,就会用fast verctor highlight
(1)对大field而言(大于1mb),性能更高
delete /news_website
PUT /news_website
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"term_vector" : "with_positions_offsets"
}
}
}
}
强制使用某种highlighter,比如对于开启了term vector的field而言,可以强制使用plain highlight
GET /news_website/_doc/_search
{
"query": {
"match": {
"content": "文章"
}
},
"highlight": {
"fields": {
"content": {
"type": "plain"
}
}
}
}
总结一下,其实可以根据你的实际情况去考虑,一般情况下,用plain highlight也就足够了,不需要做其他额外的设置。
如果对高亮的性能要求很高,可以尝试启用posting highlight,如果field的值特别大,超过了1M,那么可以用fast vector highlight
设置高亮html标签,默认是<em>标签
GET /news_website/_doc/_search
{
"query": {
"match": {
"content": "文章"
}
},
"highlight": {
"pre_tags": ["<span color='red'>"],
"post_tags": ["</span>"],
"fields": {
"content": {
"type": "plain"
}
}
}
}
高亮片段fragment的设置
GET /_search
{
"query" : {
"match": { "content": "文章" }
},
"highlight" : {
"fields" : {
"content" : {"fragment_size" : 150, "number_of_fragments" : 3 }
}
}
}
fragment_size: 你一个Field的值,比如有长度是1万,但是你不可能在页面上显示这么长啊。设置要显示出来的fragment文本判断的长度,默认是100。
number_of_fragments:你可能你的高亮的fragment文本片段有多个片段,你可以指定就显示几个片段。
36.聚合搜索技术深入
1.bucket和metric概念简介
bucket就是一个聚合搜索时的数据分组。如:销售部门有员工张三和李四,开发部门有员工王五和赵六。那么根据部门分组聚合得到结果就是两个bucket。销售部门bucket中有张三和李四,
开发部门 bucket中有王五和赵六。
metric就是对一个bucket数据执行的统计分析。如上述案例中,开发部门有2个员工,销售部门有2个员工,这就是metric。
metric有多种统计,如:求和,最大值,最小值,平均值等。
用一个大家容易理解的SQL语法来解释,如:select count() from table group by column。那么group by column分组后的每组数据就是bucket。对每个分组执行的count()就是metric。
2.准备案例数据
PUT /cars
{
"mappings": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"model": {
"type": "keyword"
},
"sold_date": {
"type": "date"
},
"remark" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
POST /cars/_bulk
{ "index": {}}
{ "price" : 258000, "color" : "金色", "brand":"大众", "model" : "大众迈腾", "sold_date" : "2021-10-28","remark" : "大众中档车" }
{ "index": {}}
{ "price" : 123000, "color" : "金色", "brand":"大众", "model" : "大众速腾", "sold_date" : "2021-11-05","remark" : "大众神车" }
{ "index": {}}
{ "price" : 239800, "color" : "白色", "brand":"标志", "model" : "标志508", "sold_date" : "2021-05-18","remark" : "标志品牌全球上市车型" }
{ "index": {}}
{ "price" : 148800, "color" : "白色", "brand":"标志", "model" : "标志408", "sold_date" : "2021-07-02","remark" : "比较大的紧凑型车" }
{ "index": {}}
{ "price" : 1998000, "color" : "黑色", "brand":"大众", "model" : "大众辉腾", "sold_date" : "2021-08-19","remark" : "大众最让人肝疼的车" }
{ "index": {}}
{ "price" : 218000, "color" : "红色", "brand":"奥迪", "model" : "奥迪A4", "sold_date" : "2021-11-05","remark" : "小资车型" }
{ "index": {}}
{ "price" : 489000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪A6", "sold_date" : "2022-01-01","remark" : "政府专用?" }
{ "index": {}}
{ "price" : 1899000, "color" : "黑色", "brand":"奥迪", "model" : "奥迪A 8", "sold_date" : "2022-02-12","remark" : "很贵的大A6。。。" }
3.聚合操作案例
1、根据color分组统计销售数量
只执行聚合分组,不做复杂的聚合统计。在ES中最基础的聚合为terms,相当于SQL中的count。
在ES中默认为分组数据做排序,使用的是doc_count数据执行降序排列。可以使用_key元数据,根据分组后的字段数据执行不同的排序方案,也可以根据_count元数据,根据分组后的统计值执行不同的排序方案。
GET /cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"_count": "desc"
}
}
}
}
}
2、统计不同color车辆的平均价格
本案例先根据color执行聚合分组,在此分组的基础上,对组内数据执行聚合统计,这个组内数据的聚合统计就是metric。同样可以执行排序,因为组内有聚合统计,且对统计数据给予了命名avg_by_price,所以可以根据这个聚合统计数据字段名执行排序逻辑。
GET /cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price": "asc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
size可以设置为0,表示不返回ES中的文档,只返回ES聚合之后的数据,提高查询速度,当然如果你需要这些文档的话,也可以按照实际情况进行设置
GET /cars/_search
{
"size" : 0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"group_by_brand" : {
"terms": {
"field": "brand",
"order": {
"avg_by_price": "desc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
3、统计不同color不同brand中车辆的平均价格
先根据color聚合分组,在组内根据brand再次聚合分组,这种操作可以称为下钻分析。
Aggs如果定义比较多,则会感觉语法格式混乱,aggs语法格式,有一个相对固定的结构,简单定义:aggs可以嵌套定义,可以水平定义。
嵌套定义称为下钻分析。水平定义就是平铺多个分组方式。
GET /index_name/type_name/_search
{
“aggs” : {
“定义分组名称(最外层)”: {
“分组策略如:terms、avg、sum” : {
“field” : “根据哪一个字段分组”,
“其他参数” : “”
},
“aggs” : {
“分组名称1” : {},
“分组名称2” : {}
}
}
}
}
GET /cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price_color": "asc"
}
},
"aggs": {
"avg_by_price_color" : {
"avg": {
"field": "price"
}
},
"group_by_brand" : {
"terms": {
"field": "brand",
"order": {
"avg_by_price_brand": "desc"
}
},
"aggs": {
"avg_by_price_brand": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
4、统计不同color中的最大和最小价格、总价
GET /cars/_search
{
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price" : {
"min": {
"field": "price"
}
},
"sum_price" : {
"sum": {
"field": "price"
}
}
}
}
}
}
在常见的业务常见中,聚合分析,最常用的种类就是统计数量,最大,最小,平均,总计等。通常占有聚合业务中的60%以上的比例,小型项目中,甚至占比85%以上。
5、统计不同品牌汽车中价格排名最高的车型
在分组后,可能需要对组内的数据进行排序,并选择其中排名高的数据。那么可以使用s来实现:top_top_hithits中的属性size代表取组内多少条数据(默认为10);sort代表组内使用什么字段什么规则排序(默认使用_doc的asc规则排序);_source代表结果中包含document中的那些字段(默认包含全部字段)。
GET cars/_search
{
"size" : 0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"top_car": {
"top_hits": {
"size": 1,
"sort": [
{
"price": {
"order": "desc"
}
}
],
"_source": {
"includes": ["model", "price"]
}
}
}
}
}
}
}
6、histogram 区间统计
histogram类似terms,也是进行bucket分组操作的,是根据一个field,实现数据区间分组。
如:以100万为一个范围,统计不同范围内车辆的销售量和平均价格。那么使用histogram的聚合的时候,field指定价格字段price。区间范围是100万-interval : 1000000。这个时候ES会将price价格区间划分为: [0, 1000000), [1000000, 2000000), [2000000, 3000000)等,依次类推。在划分区间的同时,histogram会类似terms进行数据数量的统计(count),可以通过嵌套aggs对聚合分组后的组内数据做再次聚合分析。
GET /cars/_search
{
"aggs": {
"histogram_by_price": {
"histogram": {
"field": "price",
"interval": 1000000
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
7、date_histogram区间分组
date_histogram可以对date类型的field执行区间聚合分组,如每月销量,每年销量等。
如:以月为单位,统计不同月份汽车的销售数量及销售总金额。这个时候可以使用date_histogram实现聚合分组,其中field来指定用于聚合分组的字段,interval指定区间范围(可选值有:year、quarter、month、week、day、hour、minute、second),format指定日期格式化,min_doc_count指定每个区间的最少document(如果不指定,默认为0,当区间范围内没有document时,也会显示bucket分组),extended_bounds指定起始时间和结束时间(如果不指定,默认使用字段中日期最小值所在范围和最大值所在范围为起始和结束时间)。
ES7.x之前的语法
GET /cars/_search
{
"aggs": {
"histogram_by_date" : {
"date_histogram": {
"field": "sold_date",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count": 1,
"extended_bounds": {
"min": "2021-01-01",
"max": "2022-12-31"
}
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
执行后出现
#! Deprecation: [interval] on [date_histogram] is deprecated, use [fixed_interval] or [calendar_interval] in the future.
8.X之后
GET /cars/_search
{
"aggs": {
"histogram_by_date" : {
"date_histogram": {
"field": "sold_date",
"calendar_interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count": 1,
"extended_bounds": {
"min": "2021-01-01",
"max": "2022-12-31"
}
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
9、_global bucket
在聚合统计数据的时候,有些时候需要对比部分数据和总体数据。
如:统计某品牌车辆平均价格和所有车辆平均价格。global是用于定义一个全局bucket,这个bucket会忽略query的条件,检索所有document进行对应的聚合统计。
GET /cars/_search
{
"size" : 0,
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"volkswagen_of_avg_price": {
"avg": {
"field": "price"
}
},
"all_avg_price" : {
"global": {},
"aggs": {
"all_of_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
10、aggs+order
对聚合统计数据进行排序。
如:统计每个品牌的汽车销量和销售总额,按照销售总额的降序排列。
GET /cars/_search
{
"aggs": {
"group_of_brand": {
"terms": {
"field": "brand",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
如果有多层aggs,执行下钻聚合的时候,也可以根据最内层聚合数据执行排序。
如:统计每个品牌中每种颜色车辆的销售总额,并根据销售总额降序排列。这就像SQL中的分组排序一样,只能组内数据排序,而不能跨组实现排序。
GET /cars/_search
{
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
}
}
11、search+aggs
聚合类似SQL中的group by子句,search类似SQL中的where子句。在ES中是完全可以将search和aggregations整合起来,执行相对更复杂的搜索统计。
如:统计某品牌车辆每个季度的销量和销售额。
GET /cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"histogram_by_date": {
"date_histogram": {
"field": "sold_date",
"calendar_interval": "quarter",
"min_doc_count": 1
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
12、filter+aggs
在ES中,filter也可以和aggs组合使用,实现相对复杂的过滤聚合分析。
如:统计10万~50万之间的车辆的平均价格。
GET /cars/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 100000,
"lte": 500000
}
}
}
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
13、聚合中使用filter
filter也可以使用在aggs句法中,filter的范围决定了其过滤的范围。
如:统计某品牌汽车最近一年的销售总额。将filter放在aggs内部,代表这个过滤器只对query搜索得到的结果执行filter过滤。如果filter放在aggs外部,过滤器则会过滤所有的数据。
12M/M 表示 12 个月。
1y/y 表示 1年。
d 表示天
GET /cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"count_last_year": {
"filter": {
"range": {
"sold_date": {
"gte": "now-12M"
}
}
},
"aggs": {
"sum_of_price_last_year": {
"sum": {
"field": "price"
}
}
}
}
}
}
37.es生产集群部署之针对生产集群的脑裂问题专门定制的重要参数
集群脑裂是什么?
所谓脑裂问题,就是同一个集群中的不同节点,对于集群的状态有了不一样的理解,比如集群中存在两个master。
如果因为网络的故障,导致一个集群被划分成了两片,每片都有多个node,以及一个master,那么集群中就出现了两个master了。但是因为master是集群中非常重要的一个角色,主宰了集群状态的维护,以及shard的分配,因此如果有两个master,可能会导致数据异常。
如:
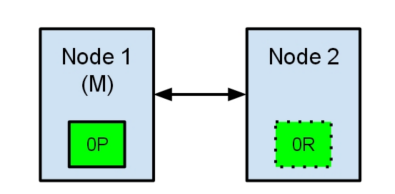
节点1在启动时被选举为主节点并保存主分片标记为0P,而节点2保存复制分片标记为0R。
现在,如果在两个节点之间的通讯中断了,会发生什么?由于网络问题或只是因为其中一个节点无响应,这是有可能发生的。
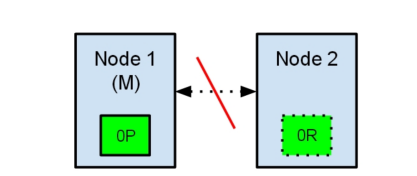
两个节点都相信对方已经挂了。节点1不需要做什么,因为它本来就被选举为主节点。但是节点2会自动选举它自己为主节点,因为它相信集群的一部分没有主节点了。
在elasticsearch集群,是有主节点来决定将分片平均的分布到节点上的。节点2保存的是复制分片,但它相信主节点不可用了。所以它会自动提升Node2节点为主节点。
现在我们的集群在一个不一致的状态了。打在节点1上的索引请求会将索引数据分配在主节点,同时打在节点2的请求会将索引数据放在分片上。在这种情况下,分片的两份数据分开了,如果不做一个全量的重索引很难对它们进行重排序。在更坏的情况下,一个对集群无感知的索引客户端(例如,使用REST接口的),这个问题非常透明难以发现,无论哪个节点被命中索引请求仍然在每次都会成功完成。问题只有在搜索数据时才会被隐约发现:取决于搜索请求命中了哪个节点,结果都会不同。
那个参数的作用,就是告诉es直到有足够的master候选节点时,才可以选举出一个master,否则就不要选举出一个master。这个参数必须被设置为集群中master候选节点的quorum数量,也就是大多数。至于quorum的算法,就是:master候选节点数量 / 2 + 1。
比如我们有10个节点,都能维护数据,也可以是master候选节点,那么quorum就是10 / 2 + 1 = 6。
如果我们有三个master候选节点,还有100个数据节点,那么quorum就是3 / 2 + 1 = 2
如果我们有2个节点,都可以是master候选节点,那么quorum是2 / 2 + 1 = 2。此时就有问题了,因为如果一个node挂掉了,那么剩下一个master候选节点,是无法满足quorum数量的,也就无法选举出新的master,集群就彻底挂掉了。此时就只能将这个参数设置为1,但是这就无法阻止脑裂的发生了。
综上所述,一个生产环境的es集群,至少要有3个节点,同时将这个参数设置为quorum,也就是2。discovery.zen.minimum_master_nodes设置为2,如何避免脑裂呢?
那么这个是参数是如何避免脑裂问题的产生的呢?比如我们有3个节点,quorum是2.现在网络故障,1个节点在一个网络区域,另外2个节点在另外一个网络区域,不同的网络区域内无法通信。这个时候有两种情况情况:
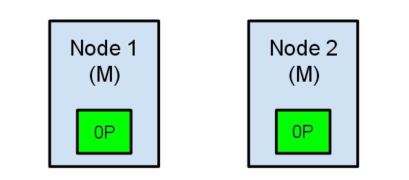
(1)如果master是单独的那个节点,另外2个节点是master候选节点,那么此时那个单独的master节点因为没有指定数量的候选master
node在自己当前所在的集群内,因此就会取消当前master的角色,尝试重新选举,但是无法选举成功。然后另外一个网络区域内的node因为无法连接到master,就会发起重新选举,因为有两个master候选节点,满足了quorum,因此可以成功选举出一个master。此时集群中就会还是只有一个master。(2)如果master和另外一个node在一个网络区域内,然后一个node单独在一个网络区域内。那么此时那个单独的node因为连接不上master,会尝试发起选举,但是因为master候选节点数量不到quorum,因此无法选举出master。而另外一个网络区域内,原先的那个master还会继续工作。这也可以保证集群内只有一个master节点。
综上所述,集群中master节点的数量至少3台,三台主节点通过在elasticsearch.yml中配置discovery.zen.minimum_master_nodes: 2,就可以避免脑裂问题的产生。
38.数据建模
1、案例
设计一个用户document数据类型,其中包含一个地址数据的数组,这种设计方式相对复杂,但是在管理数据时,更加的灵活。
PUT /user_index
{
"mappings": {
"properties": {
"login_name" : {
"type" : "keyword"
},
"age " : {
"type" : "short"
},
"address" : {
"properties": {
"province" : {
"type" : "keyword"
},
"city" : {
"type" : "keyword"
},
"street" : {
"type" : "keyword"
}
}
}
}
}
}
但是上述的数据建模有其明显的缺陷,就是针对地址数据做数据搜索的时候,经常会搜索出不必要的数据,如:在下述数据环境中,搜索一个province为北京,city为天津的用户。
PUT /user_index/_doc/1
{
"login_name" : "jack",
"age" : 25,
"address" : [
{
"province" : "北京",
"city" : "北京",
"street" : "枫林三路"
},
{
"province" : "天津",
"city" : "天津",
"street" : "华夏路"
}
]
}
PUT /user_index/_doc/2
{
"login_name" : "rose",
"age" : 21,
"address" : [
{
"province" : "河北",
"city" : "廊坊",
"street" : "燕郊经济开发区"
},
{
"province" : "天津",
"city" : "天津",
"street" : "华夏路"
}
]
}
执行的搜索应该如下:
GET /user_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address.province": "北京"
}
},
{
"match": {
"address.city": "天津"
}
}
]
}
}
}
但是得到的结果并不准确,这个时候就需要使用nested object来定义数据建模。
2、nested object
使用nested object作为地址数组的集体类型,可以解决上述问题,document模型如下:
PUT /user_index
{
"mappings": {
"properties": {
"login_name" : {
"type" : "keyword"
},
"age" : {
"type" : "short"
},
"address" : {
"type": "nested",
"properties": {
"province" : {
"type" : "keyword"
},
"city" : {
"type" : "keyword"
},
"street" : {
"type" : "keyword"
}
}
}
}
}
}
这个时候就需要使用nested对应的搜索语法来执行搜索了,语法如下:
GET /user_index/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "address",
"query": {
"bool": {
"must": [
{
"match": {
"address.province": "北京"
}
},
{
"match": {
"address.city": "天津"
}
}
]
}
}
}
}
]
}
}
}
虽然语法变的复杂了,但是在数据的读写操作上都不会有错误发生,是推荐的设计方式。
其原因是:
普通的数组数据在ES中会被扁平化处理,处理方式如下:(如果字段需要分词,会将分词数据保存在对应的字段位置,当然应该是一个倒排索引,这里只是一个直观的案例)
{
"login_name" : "jack",
"address.province" : [ "北京", "天津" ],
"address.city" : [ "北京", "天津" ]
"address.street" : [ "枫林三路", "华夏路" ]
}
那么nested object数据类型ES在保存的时候不会有扁平化处理,保存方式如下:所以在搜索的时候一定会有需要的搜索结果。
{
"login_name" : "jack"
}
{
"address.province" : "北京",
"address.city" : "北京",
"address.street" : "枫林三路"
}
{
"address.province" : "天津",
"address.city" : "天津",
"address.street" : "华夏路",
}
3、父子关系数据建模
nested object的建模,有个不好的地方,就是采取的是类似冗余数据的方式,将多个数据都放在一起了,维护成本就比较高
每次更新,需要重新索引整个对象(包括跟对象和嵌套对象)。
ES 提供了类似关系型数据库中 Join 的实现。使用 Join 数据类型实现,可以通过 Parent / Child 的关系,从而分离两个对象
父文档和子文档是两个独立的文档
更新父文档无需重新索引整个子文档。子文档被新增,更改和删除也不会影响到父文档和其他子文档。
要点:父子关系元数据映射,用于确保查询时候的高性能,但是有一个限制,就是父子数据必须存在于一个shard中
父子关系数据存在一个shard中,而且还有映射其关联关系的元数据,那么搜索父子关系数据的时候,不用跨分片,一个分片本地自己就搞定了,性能当然高
父子关系
定义父子关系的几个步骤
- 设置索引的 Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
设置 Mapping

DELETE my_blogs
# 设定 Parent/Child Mapping
PUT my_blogs
{
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}
索引父文档
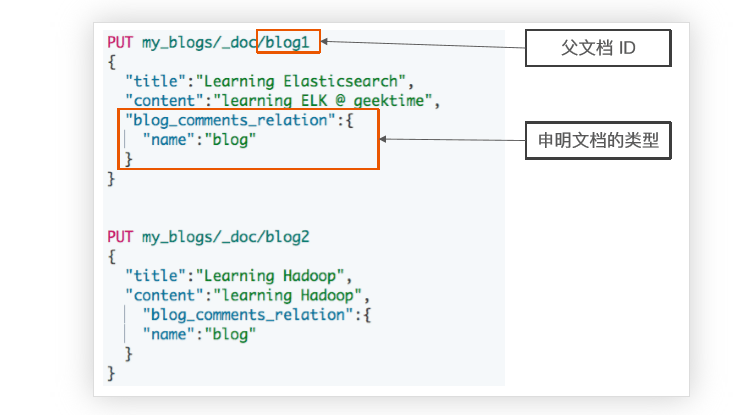
PUT my_blogs/_doc/blog1
{
"title":"Learning Elasticsearch",
"content":"learning ELK is happy",
"blog_comments_relation":{
"name":"blog"
}
}
PUT my_blogs/_doc/blog2
{
"title":"Learning Hadoop",
"content":"learning Hadoop",
"blog_comments_relation":{
"name":"blog"
}
}
索引子文档
- 父文档和子文档必须存在相同的分片上,确保查询 join 的性能
- 当指定文档时候,必须指定它的父文档 ID,使用 route参数来保证,分配到相同的分片
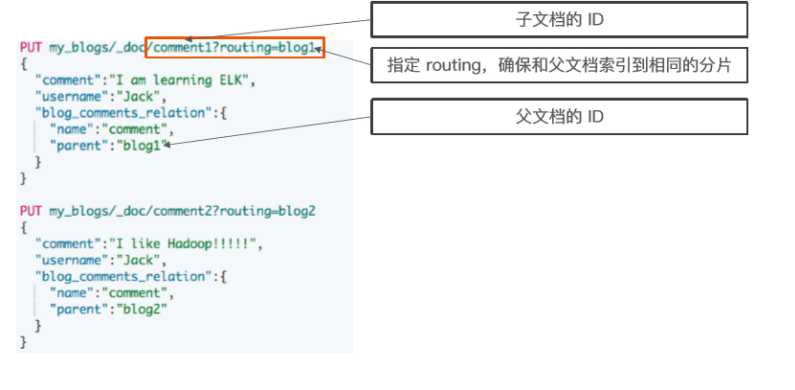
#索引子文档
PUT my_blogs/_doc/comment1?routing=blog1
{
"comment":"I am learning ELK",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog1"
}
}
PUT my_blogs/_doc/comment2?routing=blog2
{
"comment":"I like Hadoop!!!!!",
"username":"Jack",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment":"Hello Hadoop",
"username":"Bob",
"blog_comments_relation":{
"name":"comment",
"parent":"blog2"
}
}
4、Parent / Child 所支持的查询
- 查询所有文档
- Parent Id 查询
- Has Child 查询
- Has Parent 查询
# 查询所有文档
POST my_blogs/_search
{}
#根据父文档ID查看
GET my_blogs/_doc/blog2
# Parent Id 查询
POST my_blogs/_search
{
"query": {
"parent_id": {
"type": "comment",
"id": "blog2"
}
}
}
# Has Child 查询,返回父文档
POST my_blogs/_search
{
"query": {
"has_child": {
"type": "comment",
"query" : {
"match": {
"username" : "Jack"
}
}
}
}
}
# Has Parent 查询,返回相关的子文档
POST my_blogs/_search
{
"query": {
"has_parent": {
"parent_type": "blog",
"query" : {
"match": {
"title" : "Learning Hadoop"
}
}
}
}
}
5、使用 has_child 查询
返回父文档
通过对子文档进行查询
- 返回具体相关子文档的父文档
- 父子文档在相同的分片上,因此 Join 效率高
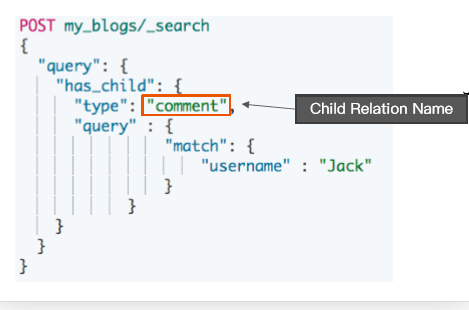
6、使用 has_parent 查询
返回相关性的子文档
通过对父文档进行查询
- 返回相关的子文档
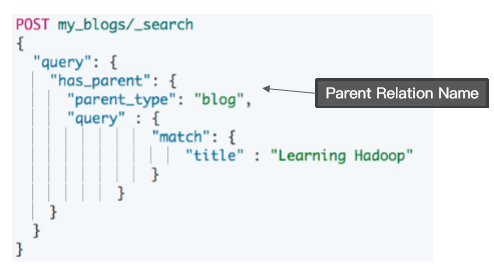
7、使用 parent_id 查询
返回所有相关子文档
通过对付文档 Id 进行查询
- 返回所有相关的子文档
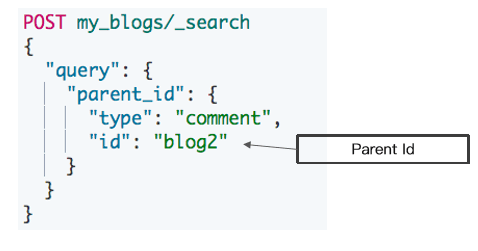
8、访问子文档
需指定父文档 routing 参数
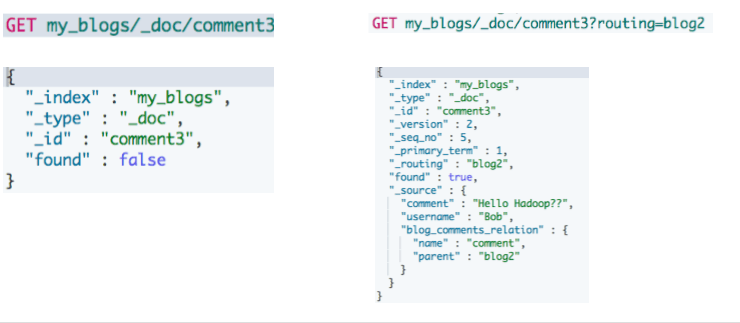
#通过ID ,访问子文档
GET my_blogs/_doc/comment2
#通过ID和routing ,访问子文档
GET my_blogs/_doc/comment3?routing=blog2
9、更新子文档
更新子文档不会影响到父文档
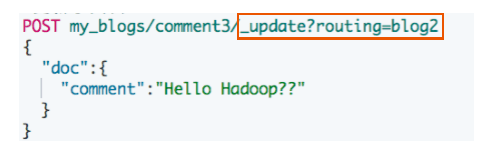
#更新子文档
PUT my_blogs/_doc/comment3?routing=blog2
{
"comment": "Hello Hadoop??",
"blog_comments_relation": {
"name": "comment",
"parent": "blog2"
}
}
10、嵌套对象 v.s 父子文档
Nested Object Parent / Child
优点:文档存储在一起,读取性能高、父子文档可以独立更新
缺点:更新嵌套的子文档时,需要更新整个文档、需要额外的内存去维护关系。读取性能相对差,适用场景子文档偶尔更新,以查询为主、子文档更新频繁。
11、文件系统数据建模
思考一下,github中可以使用代码片段来实现数据搜索。这是如何实现的?
在github中也使用了ES来实现数据的全文搜索。其ES中有一个记录代码内容的索引,大致数据内容如下:
{
"fileName" : "HelloWorld.java",
"authName" : "baiqi",
"authID" : 110,
"productName" : "first-java",
"path" : "/com/baiqi/first",
"content" : "package com.baiqi.first; public class HelloWorld { //code... }"
}
我们可以在github中通过代码的片段来实现数据的搜索。也可以使用其他条件实现数据搜索。但是,如果需要使用文件路径搜索内容应该如何实现?这个时候需要为其中的字段path定义一个特殊的分词器。具体如下:
PUT /codes
{
"settings": {
"analysis": {
"analyzer": {
"path_analyzer" : {
"tokenizer" : "path_hierarchy"
}
}
}
},
"mappings": {
"properties": {
"fileName" : {
"type" : "keyword"
},
"authName" : {
"type" : "text",
"analyzer": "standard",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"authID" : {
"type" : "long"
},
"productName" : {
"type" : "text",
"analyzer": "standard",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"path" : {
"type" : "text",
"analyzer": "path_analyzer",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"content" : {
"type" : "text",
"analyzer": "standard"
}
}
}
}
PUT /codes/_doc/1
{
"fileName" : "HelloWorld.java",
"authName" : "baiqi",
"authID" : 110,
"productName" : "first-java",
"path" : "/com/baiqi/first",
"content" : "package com.baiqi.first; public class HelloWorld { // some code... }"
}
GET /codes/_search
{
"query": {
"match": {
"path": "/com"
}
}
}
GET /codes/_analyze
{
"text": "/a/b/c/d",
"field": "path"
}
############################################################################################################
PUT /codes
{
"settings": {
"analysis": {
"analyzer": {
"path_analyzer" : {
"tokenizer" : "path_hierarchy"
}
}
}
},
"mappings": {
"properties": {
"fileName" : {
"type" : "keyword"
},
"authName" : {
"type" : "text",
"analyzer": "standard",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"authID" : {
"type" : "long"
},
"productName" : {
"type" : "text",
"analyzer": "standard",
"fields": {
"keyword" : {
"type" : "keyword"
}
}
},
"path" : {
"type" : "text",
"analyzer": "path_analyzer",
"fields": {
"keyword" : {
"type" : "text",
"analyzer": "standard"
}
}
},
"content" : {
"type" : "text",
"analyzer": "standard"
}
}
}
}
GET /codes/_search
{
"query": {
"match": {
"path.keyword": "/com"
}
}
}
GET /codes/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"path": "/com"
}
},
{
"match": {
"path.keyword": "/com/baiqi"
}
}
]
}
}
}
39、根据关键字分页搜索
在存在大量数据时,一般我们进行查询都需要进行分页查询。例如:我们指定页码、并指定每页显示多少条数据,然后Elasticsearch返回对应页码的数据。
1、使用from和size来进行分页
在执行查询时,可以指定from(从第几条数据开始查起)和size(每页返回多少条)数据,就可以轻松完成分页。
l from = (page – 1) * size
POST /es_db/_doc/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"address": "广州天河"
}
}
}
2、使用scroll方式进行分页
前面使用from和size方式,查询在1W条数据以内都是OK的,但如果数据比较多的时候,会出现性能问题。Elasticsearch做了一个限制,不允许查询的是10000条以后的数据。如果要查询1W条以后的数据,需要使用Elasticsearch中提供的scroll游标来查询。
在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样非常浪费性能。使用scroll是将要用的数据一次性排序好,然后分批取出。性能要比from + size好得多。使用scroll查询后,排序后的数据会保持一定的时间,后续的分页查询都从该快照取数据即可。
2.1、第一次使用scroll分页查询
此处,我们让排序的数据保持1分钟,所以设置scroll为1m
GET /es_db/_search?scroll=1m
{
"query": {
"multi_match":{
"query":"广州长沙张三",
"fields":["address","name"]
}
},
"size":100
}
执行后,我们注意到,在响应结果中有一项:
"_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAZEWY2VQZXBia1JTVkdhTWkwSl9GaUYtQQ=="
后续,我们需要根据这个_scroll_id来进行查询
2.2、第二次直接使用scroll id进行查询
GET _search/scroll?scroll=1m
{
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAZoWY2VQZXBia1JTVkdhTWkwSl9GaUYtQQ=="
}
40、Elasticsearch SQL

Elasticsearch SQL允许执行类SQL的查询,可以使用REST接口、命令行或者是JDBC,都可以使用SQL来进行数据的检索和数据的聚合。
Elasticsearch SQL特点:
- 本地集成
Elasticsearch SQL是专门为Elasticsearch构建的。每个SQL查询都根据底层存储对相关节点有效执行。
- 没有额外的要求
不依赖其他的硬件、进程、运行时库,Elasticsearch SQL可以直接运行在Elasticsearch集群上
- 轻量且高效
像SQL那样简洁、高效地完成查询
1、SQL与Elasticsearch对应关系

2、Elasticsearch SQL语法
SELECT select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition]
[ ORDER BY expression [ ASC | DESC ] [, ...] ]
[ LIMIT [ count ] ]
[ PIVOT ( aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] ) ) ]
目前FROM只支持单表
3、职位查询案例
3.1、查询职位索引库中的一条数据
format:表示指定返回的数据类型
//1.查询职位信息
GET /_sql?format=txt
{
"query":"SELECT * FROM es_db limit 1"
}
除了txt类型,Elasticsearch SQL还支持以下类型
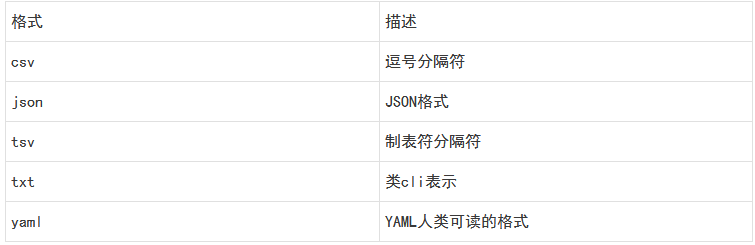
3.2、将SQL转换为DSL
GET /_sql/translate
{
"query":"SELECT * FROM es_db limit 1"
}
结果如下:
{
"size" : 1,
"_source" : {
"includes" : [
"age",
"remark",
"sex"
],
"excludes" : [ ]
},
"docvalue_fields" : [
{
"field" : "address"
},
{
"field" : "book"
},
{
"field" : "name"
}
],
"sort" : [
{
"_doc" : {
"order" : "asc"
}
}
]
}
3.3、职位全文检索
3.3.1、需求
检索address包含广州和name中包含张三的用户。
3.3.2、MATCH函数
在执行全文检索时,需要使用到MATCH函数。
MATCH(
field_exp,
constant_exp
[, options])
field_exp:匹配字段
constant_exp:匹配常量表达式
3.3.3、实现
GET /_sql?format=txt
{
"query":"select * from es_db where MATCH(address, '广州') or MATCH(name, '张三') limit 10"
}
3.4、通过Elasticsearch SQL方式实现分组统计
3.4.2、基于Elasticsearch SQL方式实现
GET /_sql?format=txt
{
"query":"select age, count(*) as age_cnt from es_db group by age"
}
这种方式要更加直观、简洁。
Elasticsearch SQL目前的一些限制。目前Elasticsearch SQL还存在一些限制。例如:不支持JOIN、不支持较复杂的子查询。所以,有一些相对复杂一些的功能,还得借助于DSL方式来实现。
41.Java API操作ES
相关依赖
<dependencies>
<!-- ES的高阶的客户端API -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
<!-- 阿里巴巴出品的一款将Java对象转换为JSON、将JSON转换为Java对象的库 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
使用JavaAPI来操作ES集群
初始化连接
使用的是RestHighLevelClient去连接ES集群,后续操作ES中的数据
private RestHighLevelClient restHighLevelClient;
public JobFullTextServiceImpl() {
// 建立与ES的连接
// 1. 使用RestHighLevelClient构建客户端连接。
// 2. 基于RestClient.builder方法来构建RestClientBuilder
// 3. 用HttpHost来添加ES的节点
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost("192.168.21.130", 9200, "http")
, new HttpHost("192.168.21.131", 9200, "http")
, new HttpHost("192.168.21.132", 9200, "http"));
restHighLevelClient = new RestHighLevelClient(restClientBuilder);
}
添加职位数据到ES中
- 使用IndexRequest对象来描述请求
- 可以设置请求的参数:设置ID、并设置传输ES的数据——注意因为ES都是使用JSON(DSL)来去操作数据的,所以需要使用一个FastJSON的库来将对象转换为JSON字符串进行操作
@Override
public void add(JobDetail jobDetail) throws IOException {
//1. 构建IndexRequest对象,用来描述ES发起请求的数据。
IndexRequest indexRequest = new IndexRequest(JOB_IDX);
//2. 设置文档ID。
indexRequest.id(jobDetail.getId() + "");
//3. 使用FastJSON将实体类对象转换为JSON。
String json = JSONObject.toJSONString(jobDetail);
//4. 使用IndexRequest.source方法设置文档数据,并设置请求的数据为JSON格式。
indexRequest.source(json, XContentType.JSON);
//5. 使用ES High level client调用index方法发起请求,将一个文档添加到索引中。
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
}
查询/删除/搜索/分页
* 新增:IndexRequest
* 更新:UpdateRequest
* 删除:DeleteRequest
* 根据ID获取:GetRequest
* 关键字检索:SearchRequest
@Override
public JobDetail findById(long id) throws IOException {
// 1. 构建GetRequest请求。
GetRequest getRequest = new GetRequest(JOB_IDX, id + "");
// 2. 使用RestHighLevelClient.get发送GetRequest请求,并获取到ES服务器的响应。
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
// 3. 将ES响应的数据转换为JSON字符串
String json = getResponse.getSourceAsString();
// 4. 并使用FastJSON将JSON字符串转换为JobDetail类对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 5. 记得:单独设置ID
jobDetail.setId(id);
return jobDetail;
}
@Override
public void update(JobDetail jobDetail) throws IOException {
// 1. 判断对应ID的文档是否存在
// a) 构建GetRequest
GetRequest getRequest = new GetRequest(JOB_IDX, jobDetail.getId() + "");
// b) 执行client的exists方法,发起请求,判断是否存在
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
if(exists) {
// 2. 构建UpdateRequest请求
UpdateRequest updateRequest = new UpdateRequest(JOB_IDX, jobDetail.getId() + "");
// 3. 设置UpdateRequest的文档,并配置为JSON格式
updateRequest.doc(JSONObject.toJSONString(jobDetail), XContentType.JSON);
// 4. 执行client发起update请求
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
}
}
@Override
public void deleteById(long id) throws IOException {
// 1. 构建delete请求
DeleteRequest deleteRequest = new DeleteRequest(JOB_IDX, id + "");
// 2. 使用RestHighLevelClient执行delete请求
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
}
@Override
public List<JobDetail> searchByKeywords(String keywords) throws IOException {
// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5.执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
}
return jobDetailArrayList;
}
@Override
public Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException {
// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 每页显示多少条
searchSourceBuilder.size(pageSize);
// 设置从第几条开始查询
searchSourceBuilder.from((pageNum - 1) * pageSize);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5.执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
}
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
long totalNum = searchResponse.getHits().getTotalHits().value;
HashMap hashMap = new HashMap();
hashMap.put("total", totalNum);
hashMap.put("content", jobDetailArrayList);
return hashMap;
}
使用scroll分页方式查询
- 第一次查询,不带scroll_id,所以要设置scroll超时时间
- 超时时间不要设置太短,否则会出现异常
- 第二次查询,SearchSrollRequest
@Override
public Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) throws IOException {
SearchResponse searchResponse = null;
if(scrollId == null) {
// 1.构建SearchRequest检索请求
// 专门用来进行全文检索、关键字检索的API
SearchRequest searchRequest = new SearchRequest(JOB_IDX);
// 2.创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keywords, "title", "jd");
// 将查询条件设置到查询请求构建器中
searchSourceBuilder.query(multiMatchQueryBuilder);
// 每页显示多少条
searchSourceBuilder.size(pageSize);
// 4.调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
//--------------------------
// 设置scroll查询
//--------------------------
searchRequest.scroll(TimeValue.timeValueMinutes(5));
// 5.执行RestHighLevelClient.search发起请求
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
}
// 第二次查询的时候,直接通过scroll id查询数据
else {
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(TimeValue.timeValueMinutes(5));
// 使用RestHighLevelClient发送scroll请求
searchResponse = restHighLevelClient.scroll(searchScrollRequest, RequestOptions.DEFAULT);
}
//--------------------------
// 迭代ES响应的数据
//--------------------------
SearchHit[] hitArray = searchResponse.getHits().getHits();
// 6.遍历结果
ArrayList<JobDetail> jobDetailArrayList = new ArrayList<>();
for (SearchHit documentFields : hitArray) {
// 1)获取命中的结果
String json = documentFields.getSourceAsString();
// 2)将JSON字符串转换为对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 3)使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(documentFields.getId()));
jobDetailArrayList.add(jobDetail);
}
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
long totalNum = searchResponse.getHits().getTotalHits().value;
HashMap hashMap = new HashMap();
hashMap.put("scroll_id", searchResponse.getScrollId());
hashMap.put("content", jobDetailArrayList);
return hashMap;
}
高亮查询
1. 配置高亮选项
// 设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.field("jd");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
2. 需要将高亮的字段拼接在一起,设置到实体类中
// 设置高亮的一些文本到实体类中
// 封装了高亮
Map<String, HighlightField> highlightFieldMap = documentFields.getHighlightFields();
HighlightField titleHL = highlightFieldMap.get("title");
HighlightField jdHL = highlightFieldMap.get("jd");
if(titleHL != null) {
// 获取指定字段的高亮片段
Text[] fragments = titleHL.getFragments();
// 将这些高亮片段拼接成一个完整的高亮字段
StringBuilder builder = new StringBuilder();
for(Text text : fragments) {
builder.append(text);
}
// 设置到实体类中
jobDetail.setTitle(builder.toString());
}
if(jdHL != null) {
// 获取指定字段的高亮片段
Text[] fragments = jdHL.getFragments();
// 将这些高亮片段拼接成一个完整的高亮字段
StringBuilder builder = new StringBuilder();
for(Text text : fragments) {
builder.append(text);
}
// 设置到实体类中
jobDetail.setJd(builder.toString());
}
42.Java API整合ElasticSearch以及Logstash、FileBeat使用
一、search template
搜索模板,search template,高级功能,就可以将我们的一些搜索进行模板化,然后的话,每次执行这个搜索,就直接调用模板,给传入一些参数就可以了
1. template入门案例
简单定义参数并传递
GET /cars/_search/template
{
"source" : {
"query" : {
"match" : {
"remark" : "{{kw}}"
}
},
"size" : "{{size}}"
},
"params": {
"kw" : "大众",
"size" : 2
}
}
toJson方式传递参数
GET cars/_search/template
{
"source": "{ \"query\": { \"match\": {{#toJson}}parameter{{/toJson}} }}",
"params": {
"parameter" : {
"remark" : "大众"
}
}
}
join方式传递参数
GET cars/_search/template
{
"source" : {
"query" : {
"match" : {
"remark" : "{{#join delimiter=' '}}kw{{/join delimiter=' '}}"
}
}
},
"params": {
"kw" : ["大众", "标致"]
}
}
default value定义:
GET cars/_search/template
{
"source" : {
"query" : {
"range" : {
"price" : {
"gte" : "{{start}}",
"lte" : "{{end}}{{^end}}200000{{/end}}"
}
}
}
},
"params": {
"start" : 100000
}
}
2.记录template实现重复调用
可以使用Mustache语言作为搜索请求的预处理,它提供了模板,然后通过键值对来替换模板中的变量。把脚本存储在本地磁盘中,默认的位置为:elasticsearch\config\scripts,通过引用脚本名称进行使用
2.1 保存template到ES
POST _scripts/test
{
"script": {
"lang": "mustache",
"source": {
"query": {
"match" : {
"remark" : "{{kw}}"
}
}
}
}
}
2.2 调用template执行搜索
GET cars/_search/template
{
"id": "test",
"params": {
"kw": "大众"
}
}
2.3 查询已定义的template
GET _scripts/test
2.4 删除已定义的template
DELETE _scripts/test
二、suggest search(completion suggest)
suggest search(completion suggest):就是建议搜索或称为搜索建议,也可以叫做自动完成-auto completion。类似百度中的搜索联想提示功能。
ES实现suggest的时候,性能非常高,其构建的不是倒排索引,也不是正排索引,就是纯的用于进行前缀搜索的一种特殊的数据结构,而且会全部放在内存中,所以suggest search进行的前缀搜索提示,性能是非常高。
需要使用suggest的时候,必须在定义index时,为其mapping指定开启suggest。具体如下:
PUT /movie
{
"mappings": {
"properties" : {
"title" : {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"suggest" : {
"type" : "completion",
"analyzer": "ik_max_word"
}
}
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
PUT /movie/_doc/1
{
"title": "西游记电影系列",
"content": "西游记之月光宝盒将与2021年进行......"
}
PUT /movie/_doc/2
{
"title": "西游记文学系列",
"content": "某知名网络小说作家已经完成了大话西游同名小说的出版"
}
PUT /movie/_doc/3
{
"title": "西游记之大话西游手游",
"content": "网易游戏近日出品了大话西游经典IP的手游,正在火爆内测中"
}
suggest 搜索:
GET /movie/_search
{
"suggest": {
"my-suggest" : {
"prefix" : "西游记",
"completion" : {
"field" : "title.suggest"
}
}
}
}
三、geo point - 地理位置搜索和聚合分析
ES支持地理位置的搜索和聚合分析,可实现在指定区域内搜索数据、搜索指定地点附近的数据、聚合分析指定地点附近的数据等操作。
ES中如果使用地理位置搜索的话,必须提供一个特殊的字段类型。GEO - geo_point。地理位置的坐标点。
1、定义geo point mapping
如果需要使用地址坐标,则需要定义一个指定的mapping类型。具体如下:
使用什么数据可以确定,地球上的一个具体的点?经纬度。
PUT /hotel_app
{
"mappings": {
"properties": {
"pin": {
"type": "geo_point"
},
"name" : {
"type" : "text",
"analyzer": "ik_max_word"
}
}
}
}
2、录入数据
新增一个基于geo point类型的数据,可以使用多种方式。
多种类型描述geo_point类型字段的时候,在搜索数据的时候,显示的格式和录入的格式是统一的。不影响搜索。任何数据描述的geo_point类型字段,都适用地理位置搜索。
数据范围要求:纬度范围是-9090之间,经度范围是-180180之间。经纬度数据都是浮点数或数字串(数字组成的字符串),最大精度:小数点后7位。(常用小数点后6位即可。)
基于对象:latitude:纬度、longitude:经度。语义清晰,建议使用。
PUT /hotel_app/_doc/1
{
"name": "七天连锁酒店",
"pin" : {
"lat" : 40.12,
"lon" : -71.34
}
}
基于字符串:依次定义纬度、经度。不推荐使用
PUT /hotel_app/_doc/2
{
"name": "维多利亚大酒店",
"pin" : "40.99, -70.81"
}
基于数组:依次定义经度、纬度。不推荐使用
PUT /hotel_app/_doc/3
{
"name": " 红树林宾馆",
"pin" : [40, -73.81]
}
3、搜索指定区域范围内的数据
总结:
矩形范围搜索:传入的top_left和bottom_right坐标点是有固定要求的。地图中以北作为top,南作为bottom,西作为left,东作为right。也就是top_left应该从西北向东南。Bottom_right应该从东南向西北。Top_left的纬度应该大于bottom_right的纬度,top_left的经度应该小于bottom_right的经度。
多边形范围搜索:对传入的若干点的坐标顺序没有任何的要求。只要传入若干地理位置坐标点,即可形成多边形。
搜索矩形范围内的数据
GET /hotel_app/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"geo_bounding_box": {
"pin": {
"top_left" : {
"lat" : 41.73,
"lon" : -74.1
},
"bottom_right" : {
"lat" : 40.01,
"lon" : -70.12
}
}
}
}
}
}
}
GET /hotel_app/_doc/_search
{
"query": {
"constant_score": {
"filter": {
"geo_bounding_box": {
"pin": {
"top_left": {
"lat": -70,
"lon": 39
},
"bottom_right": {
"lat": -75,
"lon": 41
}
}
}
}
}
}
}
//使用query方式查询
GET /hotel_app/_doc/_search
{
"query": {
"geo_bounding_box": {
"pin": {
"top_left" : {
"lat" : 41.73,
"lon" : -74.1
},
"bottom_right" : {
"lat" : 40.01,
"lon" : -70.12
}
}
}
}
}
搜索多边形范围内的数据
GET /hotel_app/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"geo_polygon": {
"pin": {
"points": [
{"lat" : 40.73, "lon" : -74.1},
{"lat" : 40.01, "lon" : -71.12},
{"lat" : 50.56, "lon" : -90.58}
]
}
}
}
}
}
}
4、搜索某地点附近的数据
这个搜索在项目中更加常用。类似附近搜索功能。
Distance距离的单位,常用的有米(m)和千米(km)。
建议使用filter来过滤geo_point数据。因为geo_point数据相关度评分计算比较耗时。使用query来搜索geo_point数据效率相对会慢一些。建议使用filter。
GET /hotel_app/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"geo_distance": {
"distance": "200km",
"pin": {
"lat": 40,
"lon": -70
}
}
}
}
}
}
GET hotel_app/_search
{
"query": {
"geo_distance" : {
"distance" : "90km",
"pin" : {
"lat" : 40.55,
"lon" : -71.12
}
}
}
}
5、统计某位置附近区域内的数据
聚合统计分别距离某位置80英里,300英里,1000英里范围内的数据数量。
其中unit是距离单位,常用单位有:米(m),千米(km),英里(mi)
distance_type是统计算法:sloppy_arc默认算法、arc最高精度、plane最高效率
GET /hotel_app/_doc/_search
{
"size": 0,
"aggs": {
"agg_by_pin" : {
"geo_distance": {
"distance_type": "arc",
"field": "pin",
"origin": {
"lat": 40,
"lon": -70
},
"unit": "mi",
"ranges": [
{
"to": 80
},
{
"from": 80,
"to": 300
},
{
"from": 300,
"to": 1000
}
]
}
}
}
}
四、Beats
Beats是一个开放源代码的数据发送器。我们可以把Beats作为一种代理安装在我们的服务器上,这样就可以比较方便地将数据发送到Elasticsearch或者Logstash中。Elastic Stack提供了多种类型的Beats组件。

Beats可以直接将数据发送到Elasticsearch或者发送到Logstash,基于Logstash可以进一步地对数据进行处理,然后将处理后的数据存入到Elasticsearch,最后使用Kibana进行数据可视化。
1、FileBeat简介
FileBeat专门用于转发和收集日志数据的轻量级采集工具。它可以为作为代理安装在服务器上,FileBeat监视指定路径的日志文件,收集日志数据,并将收集到的日志转发到Elasticsearch或者Logstash。
2、FileBeat的工作原理
启动FileBeat时,会启动一个或者多个输入(Input),这些Input监控指定的日志数据位置。FileBeat会针对每一个文件启动一个Harvester(收割机)。Harvester读取每一个文件的日志,将新的日志发送到libbeat,libbeat将数据收集到一起,并将数据发送给输出(Output)。
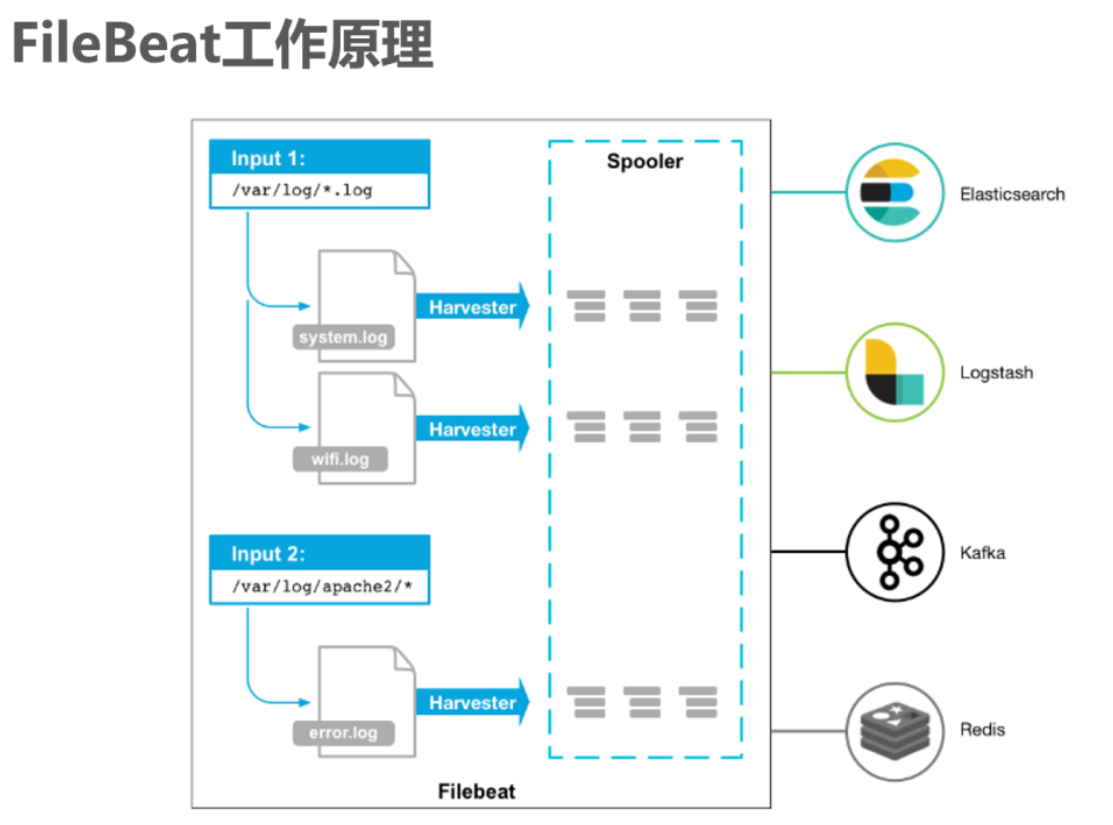
3、安装FileBeat
安装FileBeat只需要将FileBeat Linux安装包上传到Linux系统,并将压缩包解压到系统就可以了。
FileBeat官方下载地址:
https://www.elastic.co/cn/downloads/past-releases/filebeat-7-6-1
上传FileBeat安装到Linux,并解压。
tar -xvzf filebeat-7.6.1-linux-x86_64.tar.gz -C /usr/local/es/
4、使用FileBeat采集MQ日志到Elasticsearch
4.1、需求分析
在资料中有一个mq_server.log.tar.gz压缩包,里面包含了很多的MQ服务器日志,现在我们为了通过在Elasticsearch中快速查询这些日志,定位问题。我们需要用FileBeats将日志数据上传到Elasticsearch中。
问题:
首先,我们要指定FileBeat采集哪些MQ日志,因为FileBeats中必须知道采集存放在哪儿的日志,才能进行采集。
其次,采集到这些数据后,还需要指定FileBeats将采集到的日志输出到Elasticsearch,那么Elasticsearch的地址也必须指定。
4.2、配置FileBeats
FileBeats配置文件主要分为两个部分。
- inputs
- output
从名字就能看出来,一个是用来输入数据的,一个是用来输出数据的。
4.2.1、input配置
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
在FileBeats中,可以读取一个或多个数据源。
FileBeats配置文件 - input

4.2.2、output配置
FileBeat配置文件 - output
 默认FileBeat会将日志数据放入到名称为:filebeat-%filebeat版本号%-yyyy.MM.dd 的索引中。
默认FileBeat会将日志数据放入到名称为:filebeat-%filebeat版本号%-yyyy.MM.dd 的索引中。
PS:
FileBeats中的filebeat.reference.yml包含了FileBeats所有支持的配置选项。
4.3、配置文件
1. 创建配置文件
cd /usr/local/es/filebeat-7.6.1-linux-x86_64
touch filebeat_mq_log.yml
vim filebeat_mq_log.yml
2. 复制以下到配置文件中
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/mq/log/server.log.*
output.elasticsearch:
hosts: ["192.168.21.130:9200", "192.168.21.131:9200", "192.168.21.132:9200"]
4.4、运行FileBeat
1. 启动Elasticsearch
在每个节点上执行以下命令,启动Elasticsearch集群:
nohup /usr/local/es/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
2. 运行FileBeat
./filebeat -c filebeat_mq_log.yml -e
3. 将日志数据上传到/var/mq/log,并解压
mkdir -p /var/mq/log
cd /var/mq/log
tar -zxvf mq_server.log.tar.gz
4.5、查询数据
通过head插件,我们可以看到filebeat采集了日志消息,并写入到Elasticsearch集群中。
五、FileBeat是如何工作的
FileBeat主要由input和harvesters(收割机)组成。这两个组件协同工作,并将数据发送到指定的输出。
1、input和harvester
1.1、inputs(输入)
input是负责管理Harvesters和查找所有要读取的文件的组件
如果输入类型是 log,input组件会查找磁盘上与路径描述的所有文件,并为每个文件启动一个Harvester,每个输入都独立地运行
1.2、Harvesters(收割机)
Harvesters负责读取单个文件的内容,它负责打开/关闭文件,并逐行读取每个文件的内容,将读取到的内容发送给输出
每个文件都会启动一个Harvester
Harvester运行时,文件将处于打开状态。如果文件在读取时,被移除或者重命名,FileBeat将继续读取该文件
2、FileBeats如何保持文件状态
FileBeat保存每个文件的状态,并定时将状态信息保存在磁盘的「注册表」文件中
该状态记录Harvester读取的最后一次偏移量,并确保发送所有的日志数据
如果输出(Elasticsearch或者Logstash)无法访问,FileBeat会记录成功发送的最后一行,并在输出(Elasticsearch或者Logstash)可用时,继续读取文件发送数据
在运行FileBeat时,每个input的状态信息也会保存在内存中,重新启动FileBeat时,会从「注册表」文件中读取数据来重新构建状态。
在/usr/local/es/filebeat-7.6.1-linux-x86_64/data目录中有一个Registry文件夹,里面有一个data.json,该文件中记录了Harvester读取日志的offset。
六. Logstash
1、简介
Logstash是一个开源的数据采集引擎。它可以动态地将不同来源的数据统一采集,并按照指定的数据格式进行处理后,将数据加载到其他的目的地。最开始,Logstash主要是针对日志采集,但后来Logstash开发了大量丰富的插件,所以,它可以做更多的海量数据的采集。
它可以处理各种类型的日志数据,例如:Apache的web log、Java的log4j日志数据,或者是系统、网络、防火墙的日志等等。它也可以很容易的和Elastic Stack的Beats组件整合,也可以很方便的和关系型数据库、NoSQL数据库、MQ等整合。
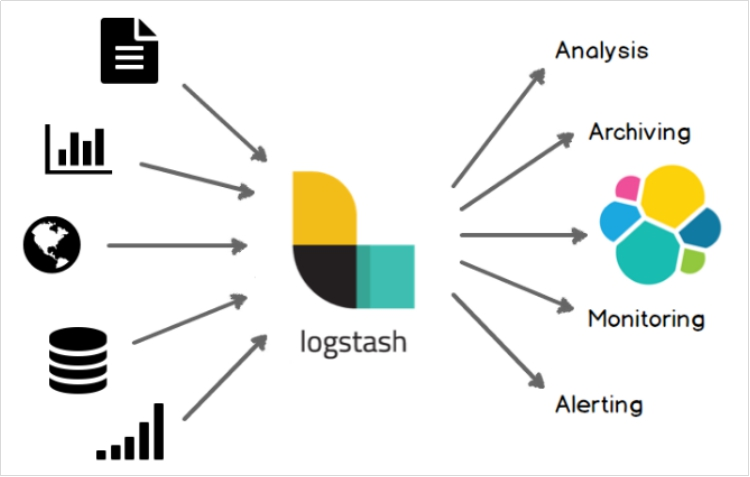
1.1 经典架构
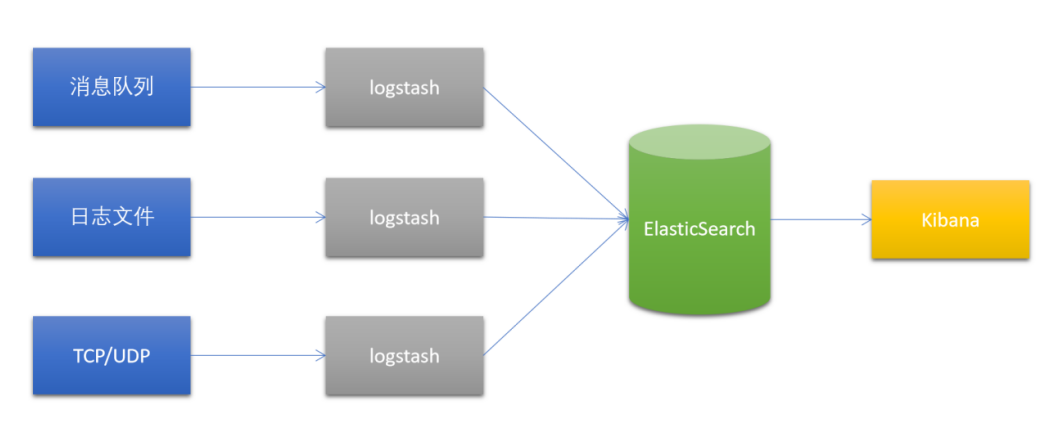
1.2 对比FileBeat
logstash是jvm跑的,资源消耗比较大
而FileBeat是基于golang编写的,功能较少但资源消耗也比较小,更轻量级
logstash 和filebeat都具有日志收集功能,Filebeat更轻量,占用资源更少
logstash 具有filter功能,能过滤分析日志
一般结构都是filebeat采集日志,然后发送到消息队列,redis,MQ中然后logstash去获取,利用filter功能过滤分析,然后存储到elasticsearch中
FileBeat和Logstash配合,实现背压机制
2 安装Logstash和Kibana
2.1 安装Logstash
1. 下载Logstash
https://www.elastic.co/cn/downloads/past-releases/logstash-7-6-1
此处:我们可以选择资料中的logstash-7.6.1.zip安装包。
2. 解压Logstash到指定目录
unzip logstash-7.6.1 -d /usr/local/es/
3. 运行测试
cd /usr/local/es/logstash-7.6.1/
bin/logstash -e 'input { stdin { } } output { stdout {} }'
等待一会,让Logstash启动完毕。
Sending Logstash logs to /usr/local/es/logstash-7.6.1/logs which is now configured via log4j2.properties
[2021-02-28T16:31:44,159][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2021-02-28T16:31:44,264][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.6.1"}
[2021-02-28T16:31:45,631][INFO ][org.reflections.Reflections] Reflections took 37 ms to scan 1 urls, producing 20 keys and 40 values
[2021-02-28T16:31:46,532][WARN ][org.logstash.instrument.metrics.gauge.LazyDelegatingGauge][main] A gauge metric of an unknown type (org.jruby.RubyArray) has been create for key: cluster_uuids. This may result in invalid serialization. It is recommended to log an issue to the responsible developer/development team.
[2021-02-28T16:31:46,560][INFO ][logstash.javapipeline ][main] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["config string"], :thread=>"#<Thread:0x3ccbc15b run>"}
[2021-02-28T16:31:47,268][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2021-02-28T16:31:47,348][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2021-02-28T16:31:47,550][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
然后,随便在控制台中输入内容,等待Logstash的输出。
{
"host" => "127.0.0.1",
"message" => "hello logstash",
"@version" => "1",
"@timestamp" => 2021-02-28:01:01.007Z
}
🍊廖志伟的新媒体平台🍊:https://www.yuque.com/docs/share/7287f4ec-5569-47f0-99a0-6c07b1c1d763



















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











