 浏览器核心知识点总结
浏览器核心知识点总结





🔥【面试系列】万字长文,让面试没有难撕的JS基础题
🔥【面试系列】万字长文,总结浏览器十大问题
🔥【面试系列】万字长文,速通TCP、HTTP(s)、DNS、CDN、websocket、SSE
🔥【面试系列】400行mini-react,图文解说React原理
我的博客在「掘金」持续更新…
一、浏览器对象模型(BOM)有哪些属性
这里不会详细介绍每个BOM属性(确实没必要哈)。主要是围绕BOM,发散一些常见的面试题,看看是如何回答的。
BOM的属性:
- window
- location
- navigator
- history
- screen
location - hash路由
http://foouser:barpassword@www.wrox.com:80/WileyCDA/?q=javascript#contents
| 属性名 | 例子 | 说明 |
|---|---|---|
| hash | “#contents” | utl中#后面的字符,没有则返回空串 |
| host | www.wrox.com:80 | 服务器名称和端口号 |
| hostname | www.wrox.com | 域名,不带端口号 |
| href | http://www.wrox.com:80/WileyCDA/?q=javascript#contents | 完整url |
| pathname | “/WileyCDA/” | 服务器下面的文件路径 |
| port | 80 | url的端口号,没有则为空 |
| protocol | http: | 使用的协议 |
| search | ?q=javascript | url的查询字符串,通常为?后面的内容 |
1.除了 hash之外,只要修改location的一个属性,就会导致页面重新加载新URL。现代前端框架react/vue的路由的hash模式就是基于这个属性实现的(下面会较详细介绍)。
2.location.reload(),此方法可以重新刷新当前页面。就像刷新按钮一样,如果本地有强缓存会走强缓存。
3.当传入参数true,location.reload(true)会强制重载,忽略缓存(包括强缓存和协商缓存)。默认为 false。仅在 Firefox 中支持。
navigator - 判断浏览器设备
关于navigator,我们重点回答这个2问题:
- 如何判断是Mobile还是PC?
- 如何判断是浏览器类型(chrome/edge/safari/微信/QQ/支付宝webview)?
navigator.userAgent 通常包含:
- 浏览器内核和版本
- 系统信息
- 特定 App 或 WebView 的标识
例如一个典型的UA:
Mozilla/5.0 (iPhone; CPU iPhone OS 16_0 like Mac OS X)
AppleWebKit/605.1.15 (KHTML, like Gecko)
Mobile/15E148 MicroMessenger/8.0.39(0x1800273f) NetType/WIFI Language/zh_CN
包含了操作系统信息iPhone,渲染引擎信息AppleWebKit,浏览器信息MicroMessenger/8.0.39。
如何判断是Mobile还是PC?
const ua = navigator.userAgent.toLowerCase();
const isMobile = /iphone|ipad|ipod|android|mobile|phone|tablet/i.test();
如何判断浏览器/webview的类型?
function getBrowserType() {
const ua = navigator.userAgent.toLowerCase();
if (ua.includes('micromessenger')) {
return 'WeChat';
} else if (ua.includes('qq') || ua.includes('mqqbrowser')) {
return 'QQ';
} else if (ua.includes('alipayclient')) {
return 'Alipay';
} else if (ua.includes('ucbrowser')) {
return 'UC';
} else if (ua.includes('baiduboxapp')) {
return 'Baidu';
} else if (ua.includes('aweme')) {
return 'Douyin';
} else if (ua.includes('safari') && !ua.includes('chrome')) {
return 'Safari';
} else if (ua.includes('chrome')) {
return 'Chrome';
} else {
return 'Other';
}
}
history - 框架路由实现
history这个API也需要重点关注下,因为现代前端框架的路由react-router, vue-router都是基于这个实现的。
下面以react-router为例(vue-router也是类似的原理),介绍它是如何基于history和location API实现的。
要实现路由导航需要解决核心两个问题:
- 如何导航时不刷新页面
- 如何监听路由的变化
BrowserRouter(history模式的路由)
首先介绍一下history API:
history.pushState(stateObj, title , url)history.replaceState(stateObj, title , url)history.go(delta)history.forward()history.back()
pushState和replaceState可以修改历史记录(往历史记录栈中加一个历史记录条目)。stateObj表示传递给下一个历史记录条目的状态,可以通过history.state获取;title通常被现代浏览器忽略,并不改变标签页的标题;url是字符串,表示新的 URL。
然后介绍下如何利用history API解决两个核心问题:
pushState/replaceState,这两个方法改变 URL 的 path 部分不会引起页面刷新。通过go/back方法在两个路由间导航也不会刷新页面。- 通过监听popstate事件来监听路由的变化,但是这个事件仅针对浏览器本身(通过浏览器按钮操作)的前进后退和
history.forward()/history.go(delta)/history.back()有效,对于<a>和pushState/replaceState可以通过拦截方法的调用来实现监听。
HashRouter(hash模式的路由)
介绍如何用location.hash解决两个核心问题:
- URL的
#后面的hash字符串作为路由, 通过location.hash="#/next"可以改变hash,并且不会刷新页面。 - hash字符串变化时会触发hashchange事件,从而可以在hashchange事件监听hash路由变化。
实现原理
react-router(vue-router也是如此)实际的实现上会使用history npm包,它基于浏览器的history API做了更统一的封装实现,提供了三种类型的history: browserHistory,hashHistory,memoryHistory.
1.当输入地址时:
- 从地址栏的URL解析出来的路径和配置好的routes做匹配,根据匹配到的route,更新内部维护的路由状态(location state,这个状态是放在RouterContext中)。
- 路由状态变化后,组件树重新渲染,此时在渲染
<Outlet/>(这种占位组件)时就会根据location state来决定具体渲染那个element组件。
2.当用API主动导航时:
- 使用react-router提供的navigate API进行导航,本质是调用pushState/replaceState这些API 来改变URL,从而匹配路由并改变路由状态,引起视图变化。
二、script和link标签属性
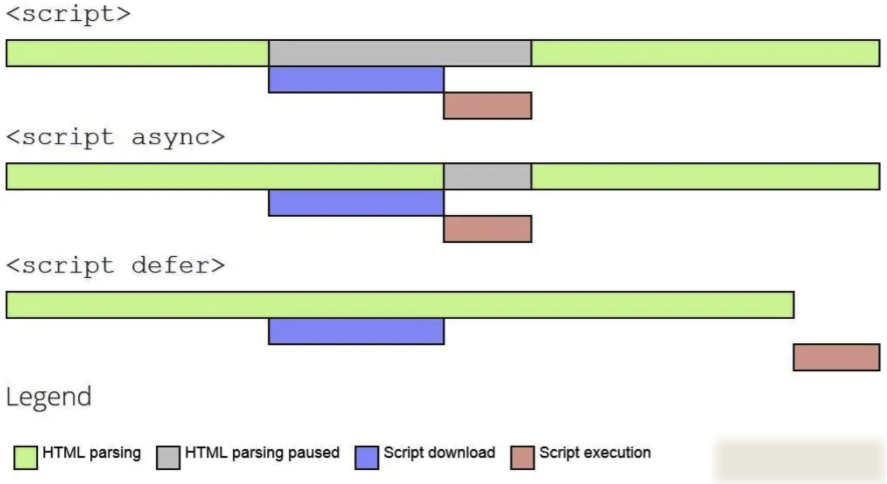
script标签的defer和async
async:立即下载,下载结束后立即执行,不等dom加载完成。(async脚本先下载的先执行,不按原本的在html中的位置顺序)
defer:立即下载,有序执行(按在html的位置顺序),等到dom加载完后执行。
(图来自网络)
link标签的preload和prefetch
preload:
作用:告知浏览器页面即将用到某些资源,并以较高优先级即时下载它们。
用途:适用于当前页面的资源:首屏css、字体等。
注意: 浏览器会立即加载,但不会执行,等用到该资源才会下载。
prefetch:
作用:提示浏览器在空闲时,在后台加载可能需要的资源。
用途:提升用户访问下一页面时的加载速度,比如电商网站对商品列表页/产品页等重要且高频访问页面提前预下载。
preload举例:css资源,避免css加载不及时导致闪烁。
<link rel="preload" href="critical-styles.css" as="style" onload="this.rel='stylesheet'">
prefetch举例:产品详情页,提前下载好产品页,加速进入产品页显示。
<link rel="prefetch" href="/js/product-detail.js" as="javascript" >
三、浏览器渲染流程
进程和线程
在浏览器篇我这里插入了「进程和线程」一小节,一方面是为了帮大家回顾一个进程和线程,另一方面这块也是很有可能被面试官提问的(作为操作系统的知识)。
进程和线程的区别
进程:
- 最小资源分配单元;
- 进程间相互隔离(1个进程崩溃不影响另外一个);
- 拥有独立的内存空间,包括虚拟地址空间、页表和TLB(快表)。
线程:
- 最小调度执行单元;
- 线程间不完全隔离,同一个进程内线程会互相影响(1个线程崩溃会影响另外一个);
- 有独立的执行栈和PC计数器,共享进程的代码和堆空间;
进程上下文切换比线程切换开销大的原因:
- 需要切换进程的页表和TLB(快表),而线程切换只需要切换执行栈和PC计数器。
- 进程切换需要保存和恢复更多的寄存器和上下文信息。
进程的通信方式
1、 管道:是操作系统在内核中开辟一段缓冲区,进程A可以将需要交互的数据拷贝到这个缓冲区里,进程B就可以读取了。特点如下:
- 内核的一块内存空间.
- 字节流,没有边界,半双工(数据流只能向一个方向)
- 多对多通信:需要多个管道。
- 大小: 4-6kb (较小)
2、消息队列:是操作系统在内核中开辟的一段内存空间,以链表结构形式存在,进程A和进程B都可以在这个列表中读写从而实现通信。特点如下:
- 内核中的一块内存空间,以链表数据结构形式存在。
- 有边界,消息是带有类型标识的,全双工通信(可以双方同时收发)。
- 多对多通信:1 个消息队列支持。
- 大小:比管道大很多(大概4M这种级别),但也有容量限制。
3、共享内存: 它通过将物理内存映射到不同进程的虚拟地址空间来实现,一个进程对共享内存的写入会立即被其他进程看到。多个进程同时进行读写,必须使用信号量、互斥锁等同步机制来避免数据混乱。它避免了数据在进程间的复制,是所有IPC机制中最快的一种。
4、信号量:信号量就是一个变量,用来表示系统中某个资源的数量。它是用来解决进程的同步和互斥问题,是进程通信的包含机制,本质上不用来传输真正的通信内容。
5、 socket:socket套接字通信是网络通信,是基于TCP/IP协议的网络通信基本单元。上述的通信方式都是同一台主机之间的进程通信,而在不同主机的进程通信就要用到socket的通信方式。
P.S. 管道和消息队列两者使用场景比较:
| 维度 | 管道 | 消息队列 |
|---|---|---|
| 速度 | 更高(内核缓冲区直接拷贝) | 略低(需处理消息结构) |
| 开发复杂度 | 简单(仅文件描述符操作) | 较高(需管理键值、类型等) |
| 扩展性 | 差(难以支持复杂通信模式) | 强(支持多对多、优先级等) |
| 持久化 | 否(进程退出后数据丢失) | 是(消息队列可以持久化) |
总结
选择管道:当需要简单、高效的字节流通信,且进程关系紧密(如父子进程)。
选择消息队列:当需要结构化消息、无关进程通信、或持久化支持。
浏览器的进程
- 浏览器进程:
作为总控进程,负责浏览器界面的显示、用户交互和子进程的创建与管理。 - 渲染进程(内核进程):
通常情况下,(不严谨的说)每个标签页(tab)会开启一个渲染进程。 它负责将HTML、CSS和JavaScript等转换为用户可视化的网页,V8引擎和Blink等核心组件都在此进程内运行,并且出于安全考虑,它运行在沙箱环境中。 - GPU进程:
专门用于处理图形渲染,尤其是对3D图形和GPU硬件加速的支持。 随着网页和浏览器UI界面的复杂化,GPU进程也变得越来越重要。 - 插件进程:
负责运行浏览器中安装的第三方插件。 为了防止插件崩溃影响整个浏览器,每个插件会拥有一个独立的进程。 - 网络进程:
负责处理页面的网络请求,如下载HTML、CSS、图片等资源。 该进程从浏览器进程中独立出来,以提高效率。
浏览器渲染
浏览器的线程
一般来说,现代浏览中同源的页面(是通过window.open, a标签跳转打开的,不是手动点击「加号」打开一个新tab输入地址打开的)会共享一个渲染进程。(实际要看浏览器是什么进程模型实现的,可自行了解)
渲染进程包括:主线程、光栅化线程、合成线程和Worker线程(Web worker/Service worker)
P.S.在前端的很多文章里提到:
“JavaScript 是单线程的,它和 GUI 渲染线程互斥。”
这里的 「GUI 线程」指的是:
- 负责 构建 DOM、样式计算、布局(layout)、绘制(paint)的那一套 UI 更新机制。
- 它与 JS 引擎线程(主线程)共存于同一个渲染进程中,但不能并行执行。
严格来说,GUI 渲染并不是一个独立的真实线程,而是主线程在某个阶段执行“渲染任务”的统称。
浏览渲染html页面的流程(5步)
1.解析html(执行JS)生成DOM;
2.计算样式,将样式应用到DOM生成Render Tree;
3.计算布局,生成Layout Tree;
4.绘制,描述低层GUI库如何绘制,产出一个绘制指令列表;
5.栅格化&合成(前面4步发生在渲染进程的主线程,这一步发生在合成线程)。
更具体的细节可以读一下这篇文章渲染流程:HTML、CSS和JavaScript是如何变成页面的?
关于上述渲染流程可以提几个问题:
a.display:none的元素会出现在Layout Tree上吗?
答:不会。构建布局树是遍历render tree上可见的元素生成的。
b.字体大小改变会触发回流吗?
答:会,font-size属于几何属性,会触发回流。
c.html解析和计算样式可以并行吗?
答:是存在局部并行的。最终的Render Tree构建是要依赖DOM的,并且要考虑样式继承,故无法直接并行。但这个过程中的一些步骤可以并行:将DOM构建好的子树划分成独立的chunk,可以使用worker并行计算chunk的样式,最后合并样式结果。
d.图片的下载会影响html的解析吗?
答:不会,图片的加载是异步的。
e.你知道什么是栅格化吗?
答:知道,栅格化是将页面的图层(Layer)或图块(Tile)转换为位图(Bitmap)的过程。(合成就是GPU将位图合成到屏幕上显示图像)
回流和重绘
当我们修改DOM、样式就会重新渲染,就是如下图(图来自网络)的的流程:
当修改/访问了元素的几何属性(比如样式的宽高和位置,增删元素)和访问offset/scroll/client家族属性和getComputedStyle属性,就会发生回流——即重新计算布局。然后会触发重绘。
当修改背景图、颜色color、不透明度opactiy、可见性visibility等不影响布局的属性,就会跳过「布局」,仅仅引起重绘。
对比:
回流的代价比较大,重绘的开销相对较小(重绘不一定导致回流,但回流一定会导致重绘)。
避免回流的优化:
- 移动元素:尽量使用transform属性的translate移动,不使用absolute定位移动元素。
- 避免分多次修改几何属性:集中在一起修改几何属性,不要分散到不同的任务(宏任务)。
- 先修改再挂载DOM:创建好的DOM元素,完成全部修改后再挂载到DOM树上(这块可以引申:用文档片段
Fragment来做这种优化); - 先修改再用display属性展示出来:先将元素脱离文档流(
display:none;),等元素的修改全部完成再显示(display:block;)。 - 动画:将动画效果应用到 position 属性为 absolute 或 fixed 的元素上,给 z-index 层级变高一点。
- 宽高计算:避免使用CSS表达式
calc。
四、存储
localStorage和sessionStorage
两者的存储大小5-10M,每个域名下的localStorage和sessionStorage的存储大小是独立的。两者区别如下:
- sessionStorage: 当tab页关闭时会被清除;
- localStorage:会长期存储,直到手动删除。
友情提示:localStorage 的API记一下哦:
setItem(key: string, value: string): 存储数据getItem(key: string): 获取数据removeItem(key: string): 删除指定数据clear(): 清空所有数据
localStorage满了会怎么样?
当localStorage存储达到上限时,浏览器会抛出 QuotaExceededError异常。
localStorage如何扩容?
原则是是无法对直接扩大localStorage容量。只能通过使用其他替代的存储方式(比如indexDB);另外可以对存储内容进行压缩和定期清理过期localStorage来高效利用localStorage。
Cookie
存储大小在4KB。可以由服务端设置Cookie(这个Cookie会被浏览器保存,这是HTTP协议的一部分)。因为HTTP是无状态的,所以需要Cookie来保存Client/浏览器的会话状态(比如:Cookie结合Session一起使用可以维护登录状态, Cookie还可以保存用户偏好、购物车数据等)。
浏览器端通过document.cookie来访问Cookie。比如加一段新Cookie:
document.cookie += newCookie;
下面是 Set-Cookie 字段的一些常见属性:
- Name: Cookie 的名称和值。
- Expires: 指定 Cookie 何时过期。如果没有指定,Cookie 将在会话结束(关闭Tab页)时过期。
- Max-Age: 指定 Cookie 的有效期(以秒为单位)。这个属性优先于 Expires。
- Domain: 指定 Cookie 所属的域名。
- Path: 指定 Cookie 的有效路径。
- Secure: 指定 Cookie 只能通过 HTTPS 传输。
- HttpOnly: 指定 Cookie 不能通过 JavaScript 访问,减少 XSS 攻击风险。
- SameSite: 控制 Cookie 是否随跨域(准确说是跨Domain)请求发送。可能的值有
Strict、Lax和None。Strict表示不携带cookie,Lax表示仅在a标签跳转请求携带,None表示可以携带。
例如,一个 Set-Cookie 头长这样:
Set-Cookie: sessionId=abc123; Expires=Wed, 09 Jun 2025 10:18:14 GMT; Path=/; Secure; HttpOnly
关于Cookie的其他注意事项:
Domain和Path两个属性决定cookie是否『同源』,也就是说cookie的「同源」限制和浏览器的同源策略是不一样的(即cookie的Domain与是否为子域名、协议、端口无关)- 默认情况下出现跨「域」(Domain),是不会携带cookie的(因为默认
SameSite=Lax;)。另外要区分:请求API中的withCredentials仅仅是控制请求时API带不带cookie,对于那些被设置了SameSite=Lax|Strict的cookie是不论怎样都不会被带到请求上的。因此,跨「域」想要携带cookie,只能设置Set-Cookie字段的属性:SameSite=None - 说起跨域,大家会联想起CORS,但是这个和Cookie的跨域携带没有联系。CORS解决的是跨域下请求响应被拦截的解决方案,而Cookie的“跨域”是不同“域”不能被访问、不能被携带的范畴。
IndexDB
IndexedDB 是一个事务型数据库系统, 是一个基于 JavaScript 的面向对象数据库。它有3个显著的特点:
- 支持事务、索引。
- 容量大,通常是几百M~GB级别。
- 存储是异步的。
使用示例:
/*1.连接*/
const request = window.indexedDB.open('myDatabase', 1);
request.onerror = (event) => {
// 使用 request.errorCode 来做点什么!
};
request.onsuccess = (event) => {
// 使用 request.result 来做点什么!
};
/*2.定义存储结构*/
// onupgradeneeded 是我们唯一可以修改数据库结构的地方(相当于初始化表结构)
request.onupgradeneeded = (event) => {
const db = event.target.result;
// 创建一个对象存储来存储我们客户的相关信息,keyPath类似主键,标识对象,具有唯一性。createObjectStore类似创建表,但是IndexDB是面向对象数据库(不是关系型数据库),所以是创建一个对象存储(也可以理解成集合,对象存储的结构并不固定,只需要有属性ssn)
const objectStore = db.createObjectStore("customers", { keyPath: "ssn" });
/*
客户数据看起来像这样的
const customerData = [
{ ssn: "444-44-4444", name: "Bill", age: 35, email: "bill@company.com" },
{ ssn: "555-55-5555", name: "Donna", age: 32, email: "donna@home.org" },
]; */
};
/*3.读写数据*/
//启动事务
const transaction = db.transaction(["customers"], "readwrite");
//添加数据
const objectStore = transaction.objectStore("customers");
customerData.forEach((customer) => {
const request = objectStore.add(customer);
request.onsuccess = (event) => {
// event.target.result === customer.ssn;
};
});
//使用游标,遍历所有数据
const objectStore = db.transaction("customers").objectStore("customers");
objectStore.openCursor().onsuccess = (event) => {
const cursor = event.target.result;
if (cursor) {
console.log(`SSN ${cursor.key} 对应的名字是 ${cursor.value.name}`);
cursor.continue();
} else {
console.log("没有更多记录了!");
}
};
IndexDB的使用场景:
- 前端日志上报和监控场景,需要本地存储日志(考虑离线、避免频繁发请求),例如美团的logan-web
- 即时通讯 (离线访问信息,包括文本、图片等等,数据量大)
Cookie和LocalStorage谁更适合存token?
首先比较下Cookie和LocalStorage两种存储方案
| 特性 | Cookie | localStorage |
|---|---|---|
| 存储大小 | 4KB | 5-10MB左右 |
| 请求携带 | 自动携带 | 不会自动携带 |
| 有效期 | 可设置有效期,过期自动删除 | 需要手动删除,或者通过存储额外的时间信息判断是否过期 |
| 安全性 | 可通过httpOnly不允许js读写来避免XSS攻击;可以通SameSite=Lax来避免CSRF攻击 | 数据可被JavaScript访问,容易受到XSS攻击;和CSRF攻击无关; |
答案:Cookie。首先两种方案都可以存token,下面将从安全性和使用场景分析为什么选Cookie方案。
- Cookie便捷:Cookie自动携带token,使用比localstorage方便(localStorage需要在请求头上手动设置);
- 安全性:Cookie可以通过httpOnly不允许js读写、secure保证仅在https下传输(避免了XSS和中间人攻击);Cookie容易受到CSRF攻击但可以通过SameSite和CSRF token等手段避免。 localStorage中的数据可以被JavaScript访问,因此容易受到XSS攻击。CSRF攻击是比较容易预防的,而XSS形式太多,相对不好预防,localStorage无法避免在XSS中不被访问,所以Cookie相对安全点。
- SSO场景使用Cookie实现更简单:
localStorage(受同源策略限制),不同域的应用无法读取,实现SSO就比较复杂。
综上,Cookie比localstorage更安全,更便捷,更适合存token.
五、跨域问题
同源策略
解释:同源策略是一种浏览器安全机制,用于限制一个源(协议、主机和端口相同)的文档或脚本如何与来自另一个源的资源进行交互。
这里的同源指下面三个条件一样:
协议(protocol) + 域名(host) + 端口(port)
为什么要同源策略:限制js,保障网站的用户信息。
- 不同源的网站的js不能互相访问对方的存储,包括cookie/localstorage/indexDB。
- 不同源的网站的js不能访问对方的DOM
- ajax请求不同源的话,会被浏览器拦截响应。
跨域解决方案:
浏览器的跨域问题:通常是指ajax请求了不同源的服务,导致响应被浏览器拦截了。解决方式有以下几种:
1. CORS(跨域资源共享)
CORS是现代浏览器支持的标准跨域解决方案,通过在服务器端设置响应头来实现:
- 设置响应头
Access-Control-Allow-Origin,值可以是*(允许任何域访问)或特定域名 - 域名可以动态设置,根据请求头的
Origin判断是否允许该域名访问 - 对于复杂请求(如PUT、DELETE等),浏览器会先发送预检请求(OPTIONS),服务器需设置
Access-Control-Allow-Methods和Access-Control-Allow-Headers等头信息 - 如需携带cookie,前端需设置
withCredentials: true,后端需设置Access-Control-Allow-Credentials: true
2. Nginx 反向代理
利用服务器不受浏览器同源策略限制的特点,在服务器端做转发:
- Nginx将前端页面和API接口配置在同一域名和端口下,通过不同的URL路径区分
- 对于浏览器来说,请求是发送到同源服务器,而Nginx则负责将请求转发到真正的API服务器
- location块通过指定模式来匹配客户端请求的URI,进行服务转发或静态资源匹配
例如Nginx配置:
server {
server_name website.com;
# 静态资源直接由nginx提供服务
location ^~ /static/ {
root /webroot/static/;
}
# 前端页面请求
location = / {
proxy_pass http://frontend-server:3000;
}
# API请求转发到后端服务
location /api/ {
proxy_pass http://backend-server:8080/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
3.Nodejs做中间层
当node提供网页服务时,ajax请求发给node,node代理请求,把数据返回给浏览器。原理本质是和Nginx代理一样。
4.JSONP
默认情况下浏览器没有对script标签进行同源限制(CSP可限制script的源),从而可以通过script标签发起一个get请求,把回调函数放到这个请求的query参数中,服务端把数据作为回调函数的参数写入js脚本交给浏览器。
script标签类似下面这样:
script.src = "http://jsonp.js?callback=cb";
服务端响应的内容类似下面这样:
res.send(`${callback}(${JSON.stringify(data)})`)
下面3种方式是开发时处理跨域可采用的:
- webpack/vite devServer
- 本地修改host文件——设置 域名映射环回地址
- whistle 服务 + proxy switchyOmega浏览器插件进行代理
六、浏览器安全
CSRF
解释
什么是 CSRF(Cross-Site Request Forgery):
- CSRF(跨网站请求伪造)是利用用户在已登录的网站上的身份,通过伪造的请求,在用户不知情的情况下,向目标网站发送请求,执行目标网站的操作。
- 举例:你在 A 网站已登录认证过,有人误导你去点他们的 B 网站的链接或页面,B 悄悄让你的浏览器去请求 A,此时浏览器会“自动带上 A 的 Cookie”,结果就用你的身份在 A 上做了你没授权的事。
为什么会发生:
- 浏览器只要发起到 A 的请求,就会自动附带 A 的 Cookie(这是“帮你保持登录”的机制)。
- 攻击者是不知道你的Cookie内容的(同源策略),但CSRF攻击并不需要知道Cookie内容,只要能“让你的浏览器把请求发出去并带上 Cookie”,就可能成功。
预防
1.Cookie 设置:
- 默认用
SameSite=Lax|Strict:跨站场景不带 Cookie。
2.校验来源:
- 优先看
Origin(非幂等方法通常会带),再回退Referer(可能被隐私或代理去掉)。 - 只允许同源或受信子域来源,其他直接拒绝。
3.令牌校验(CSRF Token):
- 做法一:服务端生成表单页面时,生成一个CSRF token作为一个隐藏字段注入到表单,同时这个CSRF token在服务端保存(session/redis)。表单提交时会携带CSRF token,然后服务端核对。这种在传统网站/SSR网站较为适用。
- 做法二(双cookie法):web页面托管服务在浏览器请求页面时,生成一个CSRF token并将其设置到Cookie(设置
httpOnly=false),然后当浏览器获取到这个CSRF token,在后续的业务请求的请求头带上CSRF token。
4.接口设计:
- 严禁用 GET 改数据(这点容易在开发时不经意间被忽略);
5.验证码:
- 通过强制用户与应用程序进行交互来预防CSRF 攻击;
补充:CSRF Token 双Cookie方法细节,惊艳面试官
将CSRF token存放到Cookie这种方案,像Spring Security和Axios请求库都是践行了这套方案的。初次接触你可能会疑惑既然是利用Cookie攻击,为啥还要将CSRF token存cookie里?不存localStorage里呢?
首先我们了解下双Cookie法的流程细节:
1.服务端响应页面请求时,设置Cookie:Name=XSRF-TOKEN。
// 中间件:检查或设置 CSRF Token
app.use((req, res, next) => {
if (!req.cookies['XSRF-TOKEN']) {
const token = crypto.randomBytes(20).toString('hex');
// 注意:CSRF token 必须能被前端读取,所以 HttpOnly 设为 false
res.cookie('XSRF-TOKEN', token, {
httpOnly: false,
sameSite: 'Strict', // 防止跨站携带
secure: false // 本地测试先关闭;线上建议启用 HTTPS 后开启
});
}
next();
});
2.js请求时,从cookie中读取XSRF-TOKEN属性值,并将之设置到请求头字段X-XSRF-TOKEN中。(如果你是使用axios请求库,这个读XSRF-TOKEN并设置X-XSRF-TOKEN是默认帮你做了的)
http.interceptors.request.use((req) => {
//jwt等操作
req.headers.set("client", "web");
req.headers.set("X-Requested-With", "XMLHttpRequest");
let csrf = utils.getCookieValue("XSRF-TOKEN");
if (csrf) {
req.headers.set("X-XSRF-TOKEN", csrf);
}
return req;
});
到这里你应该理解为啥是能存Cookie了吧,本质上还是需要读取Cookie拿到token,然后把token放到请求头上给后端校验。
为什么不用localStorage呢?我想是方便的缘故,存Cookie可以在请求页面的时候下发(通过拦截器/中间件把这层逻辑和业务隔开),如果是存localStorage那么就需要考虑CSRF token的下发时机,比如在登录时,有一定的业务侵入性。
【参考】
如何防止CSRF攻击?- 美团技术
CSRF 详解:攻击,防御,Spring Security应用等
asp.net core在vue等spa程序防止csrf攻击
XSS
解释
什么是XSS(Cross Site Scripting):
- XSS(跨站脚本):是一种常见的安全漏洞,攻击者利用它将恶意JS脚本注入到合法的网站中,然后执行这些恶意脚本来窃取用户敏感信息(如登录的token)、冒充身份和篡改网页等等。
根据攻击手段分为三种类型:
1.反射型
构造恶意的URL,参数包含JS脚本。服务端未对参数进行转义,直接渲染到页面。
2.存储型
用户输入的数据被存储在服务端的数据库中,当其他用户访问该数据时,会被直接渲染到页面(盗取cookie/localstorage的敏感信息)。常发生在注册、评论和发帖等输入交互场景。
3.DOM型
构造恶意的URL (目标网站的URL带一些恶意参数), 诱导用户点击后前端读取参数渲染页面时注入了JS脚本。
辨析:
- 反射型和存储型的区别:反射型的恶意代码在URL中,存储型代码在数据库中。
- 反射型和DOM型很类似,都是URL参数带有JS链接/JS协议代码导致的,区别在于一个是服务端渲染页面注入脚本的,一个是前端渲染时注入的。
- 反射型、存储型是后端的责任(需要后端过滤、转义),而DOM型是前端的责任。用大白话讲就是如果是服务度负责拼接HTML那么就是服务端责任,如果是前端拼接就是前端责任。
预防
总体上来说,有以下5种预防手段:
- 输入过滤
- 输出编码
- CSP(Content-Security-Policy 内容安全策略)
- Cookie: 设置httpOnly ,禁止 JavaScript 读取某些敏感 Cookie,攻击者完成 XSS 注入后也无法窃取此 Cookie。
- 输入字符串的长度限制
输入过滤&输出编码
输入过滤和输出转义,两者本质上处理方式有很大相同的——主要是对字符串转义(因为这些字符串最终是要拼接到HTML上渲染的)。
区别在于:
- 字符串作为数据要存入数据库时处理,这个时候转义行为属于"输入过滤"。
- 字符串在要拼接到HTML上渲染时处理,这个时候转义行为属于"输出编码"。
那么转义,需要转义哪些字符呢?
转义< , > , ' , " , & 这5个字符,通常能避免大多数JS注入了。代码如下:
function htmlEscape(str) {
return String(str)
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/'/g, ''')
.replace(/</g, '<')
.replace(/>/g, '>');
}
// 示例
let myString = "This is a string with < and > symbols and \"quotes\".";
let escapedString = htmlEscape(myString);
// 用于动态生成的文本
document.getElementById('output').innerHTML = htmlEscape(escapedString);
但实际上需要编码情况更为复杂,比如你还需要考虑javascript协议的脚本: javascript:恶意代码.
onerror/onload/onclick等内联事件能执行js协议字符串。
// src 是用用户数据拼接的
<img src="<%= imgSrc %>" />
// 如果用户数据如下
$imgSrc = './not-exist-img.png" onerror="javascript:恶意代码'
// 那么拼接后的 img 标签就是
<img src="./not-exist-img.png" onerror="javascript:恶意代码" />
location和<a>标签的href属性,也会执行 。
location.href = 'javascript:恶意代码'
<a href="javascript:恶意代码">1</a>
//可以通过限制只允许http/https协议,来避免。
eval/setTimeout/setInterval这些函数也能执行。
setTimeout("UNTRUSTED")
setInterval("UNTRUSTED")
eval("UNTRUSTED")
//应该避免这种调用执行
总之在转义的时候,需要采用成熟的白名单消毒库(比如DOMPurify)来处理。
P.S.
- 输入过滤其实并不是很推荐使用,因为字符串作为数据保存时,如果转义了,其实就不知道原本的字符串了,在要操作数据时就比较麻烦。当然也看场景,我觉得富文本编辑这种场景就比较适合输入过滤。
- vue的插值
{{}}语法,react的jsx动态插入内容,都是框架层面进行过非法字符转义的。应当避免使用v-html指令, react的dangerouslySetInnerHTML属性,因为这些不会进行转义,从而可能有XSS攻击的风险。
CSP
通过 HTTP 响应的头 Content-Security-Policy 字段来定义的。在响应页面的响应头加上这个字段,这个头部字段包含一系列指令,每个指令指定允许从哪些来源加载特定类型的资源。例如,script-src 指令可以用来限制从哪些域加载 JavaScript 脚本。
常见指令:
default-src: 为其他未显式指定的资源类型定义默认策略。script-src: 限制 JavaScript 资源的加载来源。style-src: 限制 CSS 样式表的加载来源。img-src: 限制图像的加载来源。connect-src: 限制 XHR、fetch、WebSocket 等请求的目的地。font-src: 限制字体的加载来源。child-src:限制 Web Worker 脚本文件或者其它 iframe 等内嵌到文档中的资源来源。report-to: 违规上报地址。
例如:
Content-Security-Policy: default-src 'self'; img-src 'self' https://cdn.example.com; script-src 'self';
这段策略的意思是:
default-src 'self':默认资源只允许从本站加载。img-src 'self' https://cdn.example.com:图片可从本站和指定 CDN 加载。script-src 'self':脚本只能从本站加载,禁止内联脚本和外部第三方脚本。
此外,处理在响应头上设置的形式外,还可以采用HTML的meta标签形式,比如,上面例子对应到meta标签就是:
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; img-src 'self' https://cdn.example.com; script-src 'self';">
Cookie设置httpOnly
Cookie的httpOnly这个并不能直接预防XSS,而是当收到XSS攻击后能一定程度上减少攻击范围,能包含cookie信息不被窃取。
Set-Cookie: sessionId=abc123; HttpOnly; Secure; SameSite=Strict;
长度限制
限制用户的输入内容长度可提高XSS攻击的难度。
【参考】:
如何防止XSS攻击?- 美团技术
七、垃圾回收机制
标记清除法
策略: 一定的频率执行一次GC(garbage collection)的流程。
- 遍历内存,给所有对象加标记0(表示无用)。
- 遍历
根对象window,访问到的对象加标记1(表示在用) - 再次遍历内存中所有对象,所有标记为0的清除,标记为1的改为0(等待下一次回收)。
优点:
实现简单,只需用一个二进制位表示用/无用两个状态,然后做遍历清除无用的。
缺点:
产生内存碎片。这会导致下一次分配内存慢(需要找到size大小的连续内存空间)。针对这个缺点,标记整理(Mark-Compact)算法可以有效解决(本质上就是标记结束后移动内存,让剩余空间连续)。
引用计数法
策略: 跟踪记录每个变量值被引用的次数
- 当对象赋值给变量,这个变量值引用次数+1
- 如果变量原本值,被其他值覆盖(比如null),则原本值的引用次数-1
- 当这个值引用次数变为0,则会被垃圾回收器回收。
let a = new Object() // 此对象的引用计数为 1(a引用)
let b = a // 此对象的引用计数是 2(a,b引用)
a = null // 此对象的引用计数为 1(b引用)
b = null // 此对象的引用计数为 0(无引用)
... // GC 回收此对象
优点: 实时性高,当一个对象的引用计数降为零时,该对象可以立即被回收,不会像其他算法那样需要等待特定时机。
缺点:
- 性能开销。引用计数法需要在每次引用关系发生变化时(如变量赋值、引用覆盖、对象属性修改、变量离开作用域)都立刻更新计数器。这带来了额外的性能负担,尤其是在引用关系变化频繁的场景下。
- 存储开销。每个对象都需要分配一个额外空间,存储计数值。
- 无法解决循环引用无法回收的问题,这是最严重的。
循环引用问题:
function problem() {
let objA = {};
let objB = {};
objA.someProp = objB; // objB 被 objA 引用,计数+1 -> 计数=2
objB.anotherProp = objA; // objA 被 objB 引用,计数+1 -> 计数=2
}
problem(); // 函数调用结束,栈上的 objA 和 objB 被清除,它们的引用计数各减1 -> 都变为1
// 此时 objA 和 objB 仍相互引用,计数永不为0,无法被引用计数算法回收
V8的分代式垃圾回收
策略: 将内存空间分为新生代和老生代。
- 新生代分为使用区和空闲区。使用「复制」算法,新对象被放入使用区,一段时间后进行GC时,对使用区的对象进行标记然后排序(清理没有引用的),将存活的对象放入空闲区(此时空闲区和使用区互换)。
- 对于复制(到空闲区)频繁的对象和比较大的对象,将被移入老生代。老生代使用 「标记清除法」
为什么要分代式?
基于“分代假说”(多数对象短命),将堆分为新生代与老生代。新生代空间较小、由两个半空间组成,采用复制回收(Minor GC)且触发频繁;对象若在多次回收后仍存活,会晋升到老生代。老生代空间更大,使用标记-清除/标记-整理(常见是增量、并发)进行较低频率的 Major GC。体积特别大的对象通常直接进入老生代的大对象空间,避免复制成本。分代机制把主要回收压力集中在短命对象上,提升吞吐并降低停顿,从而显著提高垃圾回收效率。
【参考】
「硬核JS」你真的了解垃圾回收机制吗
八、跨tab通信的方式
回答下面三种即可:
- Broadcast Channel
- Shared Worker
- localStorage/sessionStorage
【参考】
浏览器跨 Tab 窗口通信原理及应用实践
九、对JS引擎和异步实现的理解
JS引擎是只负责解释和执行JS代码,并不提供setTimeout/fetch这类API。JS引擎是单线程的,只管同步执行代码,异步代码的执行和管理是交给运行时来处理的。
JS引擎的功能:
- 解释(Interpreter)和及时编译(JIT, Just-In-Time Compilation)。
- 解释:引擎将对代码做词法分析,转AST,然后转为字节码(二进制);
- 编译:将字节码编译为机器码。
- 垃圾回收。
JS中的异步
“异步”由引擎 + 运行时(浏览器、Nodejs)配合实现 ; 其中运行时提供了异步API和任务队列(Macro Task和Micro Task等等),通过将异步任务的回调放入队列,等异步任务完成后把队列任务载入JS引擎的执行栈中执行。
JS中处理异步的三种方式:
- 回调函数
- Promise。解决地狱回调问题,需要JS引擎支持Promise语法。
- Async/Await。语法糖简化异步代码,类似生成器的原理处理了Promise。让异步代码从语法上变"同步代码"
十、浏览器的API
介绍下Worker
web worker可以细分为Worker、SharedWorker 和 ServiceWorker 等,接下来我们一一介绍其使用方法和适合的场景。
普通Worker
使用场景:处理一些长任务计算,避免主线程的阻塞。
代码示例:
在主线程:
const worker = new Worker('./worker.js'); // 参数是url,这个url必须与创建者同源
// 拿到句柄 worker后可以发送消息和接受消息
worker.postMessage('Hello World');
worker.onmessage = function (event) {
console.log('Received message ' + event.data);
doSomething();
}
worker.js 中接受和发送消息:
//通过self这个句柄/关键字,监听message事件接受消息,postMessage发消息
self.addEventListener('message', function (e) {
self.postMessage('Hello, 我是worker');
}, false);
SharedWorker
和普通Worker的区别: SharedWorker 的方法都在 port 上,这是它与普通 Worker 不同的地方。
使用场景: 可以跨window/tab/worker 共享数据(只要在同源范围内)。
代码示例:
每个页面的连接,产生的port句柄会被放入connections数组中。
// shared-worker.js
const connections = []; // 存储所有页面的端口
self.onconnect = function (e) {
// 获取新连接的端口
const port = e.ports[0];
// 将新端口存入连接列表
connections.push(port);
// 监听来自这个端口的消息
port.onmessage = function (event) {
// 接收到消息后,广播给所有其他连接的页面
connections.forEach(conn => {
if (conn !== port) { // 可选:不发送回消息来源页
conn.postMessage(event.data);
}
});
};
// 启动端口通信 (当使用 onmessage 隐式调用了 start, 但显式调用更安全)
port.start();
};
Tab 1/ Tab 2/ Tab …都使用下面类似的结构(每个页面都需要new SharedWorker建立连接)
// 检查浏览器支持
if (window.SharedWorker) {
// 创建 SharedWorker 实例,指向同一个脚本文件
const worker = new SharedWorker('shared-worker.js');
// 启动端口
worker.port.start();
// 监听来自 SharedWorker 的消息
worker.port.onmessage = function (e) {
console.log('Received message:', e.data);
// 在这里处理接收到的消息,更新页面DOM等
};
// 发送消息
function sendMessage(message) {
worker.port.postMessage(message);
}
// 例如,点击按钮发送消息
document.getElementById('sendBtn').addEventListener('click', () => {
sendMessage('Hello from Tab!');
});
} else {
console.error('Your browser does not support SharedWorker.');
}
ServiceWoker
ServiceWorker 一般作为 Web 应用程序、浏览器和网络之间的代理服务。他们旨在创建有效的离线体验,拦截网络请求,以及根据网络是否可用采取合适的行动,更新驻留在服务器上的资源。他们还将允许访问推送通知和后台同步 API。
【参考】
WebWorker、SharedWorker 和 ServiceWorker 有哪些区别?
为什么setTimeout不准确?
遇到这么个问题:“请实现一个倒计时的组件,要求倒计时要精准”。
这个时候相信聪明的你肯定想到用setTimeout/setInterval,但setTimeout/setInterval计时准确吗?
JavaScript 是单线程的,setTimeout() 的回调函数并不是在时间到了就立刻执行,而是:
“时间到了后,回调会被放入任务队列(task queue),等待主线程空闲时再执行。”
因此:
如果主线程正在执行其他任务(例如计算、渲染),回调就会被延迟执行。并且嵌套调用setTimeout会让这种误差慢慢累积,导致后面越来越不准确。
嵌套调用setTimeout:
let count = 60;
function tick() {
console.log(count);
count--;
setTimeout(tick, 1000); // 每次调用都会累积一点延迟,count并不会准确每秒减少1
}
tick();
解决方法: 使用 requestAnimationFrame()。
你可能会疑问:requestAnimationFrame的回调是在浏览器下一次重绘(repaint)前执行。这也收到主线程阻塞的影响啊。
确实,requestAnimationFrame (rAF) 也不能保证绝对精确,它同样会被主线程阻塞延迟。 并且当页面切到后台或浏览器标签页不可见时, rAF 会暂停或降低帧率(通常暂停执行)。
但是, rAF保证了一件事,就是页面出现变化前肯定会执行 rAF的回调(与浏览器绘制同步),这就意味着每次页面变化我都看到一定是准确的结果(这点不同setTimeout的倒计时可能页面看到不准确的结果)。然后,只需要么次 rAF调用时做时间校准就行,看下面的例子。
let count = 60; // 初始倒计时秒数
let startTime = performance.now(); // 开始的高精度时间
let lastSecond = 0; // 上一次减少 count 的时间
function tick(now) {
//now是一个当前时间的时间戳
const elapsed = Math.floor((now - startTime) / 1000); // 已经过的秒数
if (elapsed > lastSecond) {
const delta = elapsed - lastSecond; // 理论上应减少的秒数
count -= delta;
lastSecond = elapsed;
console.log(count);
}
if (count > 0) {
requestAnimationFrame(tick);
} else {
console.log('⏰ 倒计时结束');
}
}
requestAnimationFrame(tick);
就是说主线程阻塞了渲染导致页面没变化,这个无论都是没办法的,但是当页面重新渲染(发生变化)rAF能保证一定显示正确的count(倒计时)。
XHR, axios和fetch的区别?
xhr是最早浏览器的请求API, fetch是现代浏览器的请求API. axios则是基于xhr封装的支持promise语法形式的库。
一些具体的区别:
- json: xhr/fetch需要手动 解析json数据。axios直接自动将数据转json。
- 取消:axios/fetch支持AbortController 取消请求,xhr通过 xhr.abort()
- 处理错误:axios自动将 HTTP 错误状态码(如 404、500)转为 Promise 的
reject; xhr和fetch不会。 - 拦截:axios提供请求拦截和响应拦截。

















 2530
2530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









