



 本文作者分享了自己在阿里社招面试的经历,历经四轮面试,最终未能通过。面试涵盖了Java基础、JVM、并发、数据库、分布式等方面,虽然在面试中展现出了一些不足,但也得到了面试官的指导和建议。作者在反思后,加强学习,最终在京东获得 Offer。面试中保持冷静、适时表达、回避问题并持续提升自身能力是关键。
本文作者分享了自己在阿里社招面试的经历,历经四轮面试,最终未能通过。面试涵盖了Java基础、JVM、并发、数据库、分布式等方面,虽然在面试中展现出了一些不足,但也得到了面试官的指导和建议。作者在反思后,加强学习,最终在京东获得 Offer。面试中保持冷静、适时表达、回避问题并持续提升自身能力是关键。
本文素材来源于一位粉丝分享经验,希望能对大家有所帮助。
可能每个程序员都有个大厂梦,我也不例外。最近准备跳槽,前段时间在准备各种面试,也面了几个大厂,包括阿里、拼多多和京东等。但最后,我还是挂在了阿里第四轮。这篇文章来总结一下我在阿里四轮的面试经历,希望能对大家有所启发帮助。
阿里社招一般有四到五轮,我这次的流程是第一轮技术面、第二轮写代码、第三轮boss面、第四轮boss面、第五轮HR面。然而我没能和HR聊上一句。

阿里一面
首先自我介绍一下?
参加的比赛用到的技术?
Java的集合类有哪些?详细讲List、Set、Map
ArrayList和HashMap的区别是什么?HashMap如何解决hash冲突?有几大类hash冲突的解决方式?hash函数?
红黑树的特点?TreeSet说一下?应用场景?
CocurrentHashMap了解嘛?详细说说底层和锁的机制?应用?和HashTable的区别?
StringBuilder和StringBuffer的区别?讲到底层和各自应用场景
Java的锁都有哪些?偏向锁、轻量级锁、重量级锁、Lock包等都说了说
synchronized和Lock的区别?ReentrantLock?
什么是线程?线程进程区别?实现线程有几种方式?
线程池这块了解嘛?创建线程池的方式?用哪个方式创建比较好?说一说线程池的工作原理?拒绝策略?
sleep()和wait()的区别?
IO模型了解嘛?BIO、NIO、AIO?
快排和堆排?时间复杂度?如果数据量非常大,要进行排序的话直接快排性能不好,怎么进行优化?
计算机网络OSI模型都有哪些?
TCP和UDP的区别?应用场景?
JVM的内存模型说一下?运行时数据区?
你了解的垃圾回收算法都有哪些?引用计数和可达性分析区别?
什么是索引?索引的作用?
InnoDB底层结构?和MyISAM的区别?
假设要对sql语句优化,一般从哪几个方面来进行?
事务隔离级别有哪几类?各自解决什么问题?当前读和快照读?MVCC机制?undolog?
数据库的乐观锁和悲观锁说一下?乐观锁的实现?next-key锁?
Spring了解嘛?说一下IoC?AOP?JDK动态代理和CGlib?项目应用?
Spring 创建的bean默认什么作用域?并发的情况下会不会存在问题?提到threadLocal,又讲到了自己项目的用threadLocal怎么用的。又问那threadLocal存在什么问题?一开始想了半天没想到,停顿了一段时间很尴尬,还好想起来了,内存泄露。在此我向大家推荐一个架构学习交流圈。交流学习指导伪鑫:1253431195(里面有大量的面试题及答案)里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
反问。如果希望进入贵司的话自己还有什么不足需要改进?
面试官很好,指出了有些基础不足,这块确实自己答得不太好,非常感谢一面面试官老师,引导着我回答问题,面试体验很好!
阿里二面
自我介绍
说一说项目,深挖
讲一下Spring IoC AOP,AOP的原理?在项目哪里用了?MyBatis?Dao 接口的工作原理?讲到了AOP
谈谈你认知中的Redis?RDB、AOF?在项目里怎么用的Redis,谈到自己实现了一个异步事件处理框架,感觉面试官基本都是全程深挖项目。
了解RabbitMQ吗?zookeeper?
反问
二面基本就是问一些偏框架和中间件的知识,以及深挖项目。面试官全程非常耐心和蔼地对话,感觉就是想挖掘出我的亮点,总之体验非常好!非常感谢二面面试官老师!
阿里三面
JVM的编译优化
对Java内存模型的理解,以及其在并发中的应用
指令重排序,内存栅栏等
OOM错误,stackoverflow错误,permgen space错误
JVM常用参数
tomcat结构,类加载器流程
volatile的语义,它修饰的变量一定线程安全吗
g1和cms区别,吞吐量优先和响应优先的垃圾收集器选择
说一说你对环境变量classpath的理解?如果一个类不在classpath下,为什么会抛出ClassNotFoundException异常,如果在不改变这个类路径的前提下,怎样才能正确加载这个类?
说一下强引用、软引用、弱引用、虚引用以及他们之间和gc的关系
zookeeper原理和适用场景
zookeeper watch机制
redis/zk节点宕机如何处理
分布式集群下如何做到唯一序列号
如何做一个分布式锁
用过哪些MQ,怎么用的,和其他mq比较有什么优缺点,MQ的连接是线程安全的吗
MQ系统的数据如何保证不丢失
列举出你能想到的数据库分库分表策略;分库分表后,如何解决全表查询的问题。
三面明显强度提升,主要涉及多线程、JVM和分布式架构,貌似很多程序员的短板都是分布式,我虽然也是,但还是在面试官的指引下答出来了,阿里面试官态度是真的好,非常感谢!!!
阿里四面
四面就比较吃力了,部门经理面试,就是围绕两大块,第一是根据我的项目来提出漏洞,让我解决;第二是他自己设定场景,让我给出解决方案。
第一个还相对简单,主要是倒在了第二方面,因为对电商项目不是很了解,没有足够的经验,当时就感觉可能要凉,果不其然,过来几天在邮件里看到回复信息:您的职业经历与该职位的要求略有差异······
面对这些问题,你又是否能答出来?
笔者就这位粉丝的阿里面试过程,给大家简单分析一下:
1. 社招面试,技术问的相对来说更加深入,所以对有些源码还是要了解点,比如多线程、高并发相关的原理,是经常被问到的。JVM就更不用说了,几乎是必问到的。
2. 所有的问题都是围绕具体场景,一般大厂都会结合具体场景来问你问题,所以你只会纯理论肯定不行的,你还要知道为什么要用这个技术,以及如何做到高可用等等。
3. 以后面试,基本上都会让你写代码的,招软件开发工程师,光会嘴说是不行的,这就要平时抽空多练习了,我指的是练练算法题,而不是那种业务代码。
有了阿里面试失败的经历,终于意识到系统学习,不留短板的重要性,又开始恶补清华扫地僧级别大佬的6+2学习路线,夯实自己基础,向京东进军,终获offer!!!
6个知识点:
多线程高并发+JVM调优+设计模式+ Redis + Zookeeper + MySql调优
两大项目:
网约车+亿级流量
实战Java高并发程序设计
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3XSZadpc-1655722465895)(https://upload-images.jianshu.io/upload_images/22534184-3a649e294e26b802)]
在单核CPU时代,单任务在一个时间点只能执行单一程序,随着多核CPU的发展,并行程序开发变得尤为重要。
本篇主要介绍基于Java的并行程序设计基础、思路、方法和实战。第一,立足于并发程序基础,详细介绍Java进行并行程序设计的基本方法。第二,进一步详细介绍了JDK对并行程序的强大支持,帮助读者快速、稳健地进行并行程序开发。第三,详细讨论了“锁”的优化和提高并行程序性能级别的方法和思路。第四,介绍了并行的基本设计模式,以及Java 8/9/10对并行程序的支持和改进。第五,介绍了高并发框架Akka的使用方法。第六,详细介绍了并行程序的调试方法。第七,分析Jetty代码并给出一些其在高并发优化方面的例子。
JVM高级特性和最佳实践

*目前商用的高性能Java虚拟机都提供了相当多的优化参数和调节手段,用于满足应用程序在实际生产环境中对性能和稳定性的要求。如果只是为了入门学习,让程序在自己的机器上正常工作,那么这些特性可以说是可有可无的;但是,如果用于生产开发,尤其是大规模的、企业级的生产开发,就迫切需要开发人员中至少有一部分人对虚拟机的特性及调节方法具有很清晰的认识。所以在Java开发体系中,对架构师、系统调优师、高级程序员等角色的需求一直都非常大。 学习虚拟机中各种自动运作特性的原理也成为Java程序员成长路上最终必然会接触到的一课。
Zookeeper分布式过程协同技术详解

构建分布式系统并不容易。然而,人们日常所使用的应用大多基于分布式系统,在短时间内依赖于分布式系统的现状并不会改变。Apache ZooKeeper旨在减轻构建健壮的分布式系统的任务。ZooKeeper基于分布式计算的核心概念而设计,主要目的是给开发人员提供一套容易理解和开发的接口,从而简化分布式系统构建的任务。
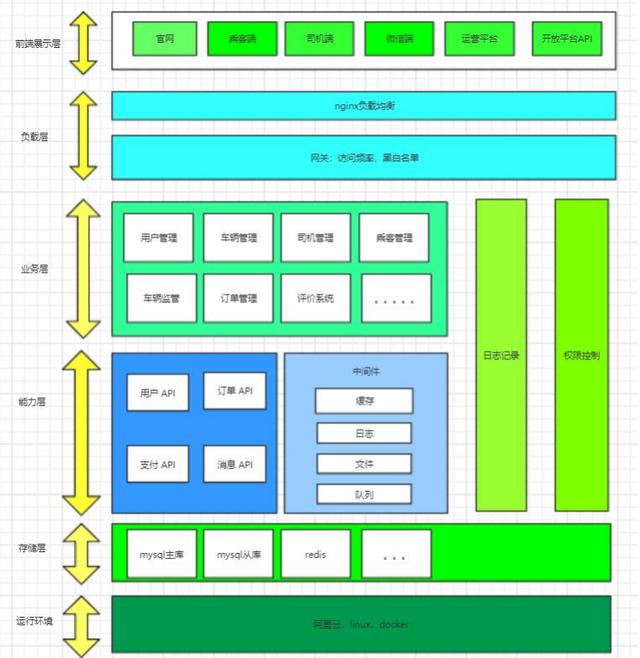
网约车项目
项目架构图
有多线程、高并发,到分布式架构、JVM调优,这些高频面试文档和网约车、亿级流量项目实战等学习资料,助你更加系统的提升进阶,不要留下明显短板,因为那就将是你的致命缺陷。
**笔者已经帮大家打包整理好了这些文档,有需要深度了解学习的朋友
当面试时突然卡住而答不上来后,有什么好的解决方法,再和朋友们分享一下,只是笔者个人的见解,有哪里觉得不合适的地方,请多多留言交流,笔者一定虚心接受,咱们共同交流学习进步~~~
一.保持冷静,搜集信息
二.杜绝沉默,适当表达
三.回避问题,展示自己
四.巩固自身,追求卓越
保持冷静使我们不自乱阵脚,再仔细分析面试官的题意,看是否是理解错误,即可实在不会,也不要冷场,适当表达出自己的缺陷,继而通过介绍类似问题展示自己,留给面试官好的印象。
最后,还是要提升自己的内功修为,追求极致的内核原理,理论结合实战,方能成就自己的一番梦想!!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









