




近日,余溺于先贤古哲之文无法自拔。虽未明其中真意,但总觉有理。遂抄录一篇以供诸君品鉴——公孙鞅曰:“臣闻之:‘疑行无名,疑事无功。’君亟定变法之虑,殆无顾天下之议之也。且夫有高人之行者,固见负于世;有独知之虑者,必见骜于民。语曰:‘愚者暗于成事,知者见于未萌。民不可与虑始,而可与乐成。’郭偃之法曰:‘论至德者,不和于俗;成大功者,不谋于众。’法者所以爱民也,礼者所以便事也。是以圣人苟可以强国,不法其故;苟可以利民,不循其礼。”
余觉“愚者暗于成事,知者见于未萌”极富道理。吾常昏聩于事成,虽欲梳之,却无人问津矣!故常不解周遭之所为,甚欲恶语向之。譬如本篇:何为自动装配?若美帝科幻巨制之机器人,勿需人工,程序自动为之也。每欲言之,人多避之。吾甚不解,窃语曰:“此虽小,却也值庆,如此为之,却是为何?”思虑再三,决意书之。
前篇(《SpringBoot自动装配(一)》)言至自动装配之入口及过程。虽小有所得,但终是狂妄自大,思虑不周,遗问颇多,譬如:千万自配者,何以滤之?说白了,就是我没有搞清楚SpringBoot启动时是如何对自动装配类进行过滤的。还有上篇文章想当然的认为DeferredImportSelector接口的实现类AutoConfigurationImportSelector中的selectImports()方法是在ConfigurationClassParser#processImports(ConfigurationClass configClass, SourceClass currentSourceClass, Collection<SourceClass> importCandidates, boolean checkForCircularImports)方法中调用的,不过经人提醒后发现其实并非如此。
1 Spring是如何决定加载哪些配置类的?
要回答这个问题,我们首先要知道Spring是何时何地开始加载自动配置类的。巧的是上篇文章对这个点进行了梳理,这个入口就在AutoConfigurationImportSelector类的selectImports(AnnotationMetadata annotationMetadata)方法中,这个方法执行了一堆逻辑(具体可参见《SpringBoot自动装配(一)》这篇文章的三小节),其中有一段代码是这样写的:
configurations = filter(configurations, autoConfigurationMetadata);与这个调用相关的方法位于AutoConfigurationImportSelector类中,与调用者selectImports()方法处于同一类中,其具体源码如下所示:
private List<String> filter(List<String> configurations,
AutoConfigurationMetadata autoConfigurationMetadata) {
long startTime = System.nanoTime();
String[] candidates = configurations.toArray(new String[configurations.size()]);
boolean[] skip = new boolean[candidates.length];
boolean skipped = false;
for (AutoConfigurationImportFilter filter : getAutoConfigurationImportFilters()) {
invokeAwareMethods(filter);
boolean[] match = filter.match(candidates, autoConfigurationMetadata);
for (int i = 0; i < match.length; i++) {
if (!match[i]) {
skip[i] = true;
skipped = true;
}
}
}
if (!skipped) {
return configurations;
}
List<String> result = new ArrayList<String>(candidates.length);
for (int i = 0; i < candidates.length; i++) {
if (!skip[i]) {
result.add(candidates[i]);
}
}
if (logger.isTraceEnabled()) {
int numberFiltered = configurations.size() - result.size();
logger.trace("Filtered " + numberFiltered + " auto configuration class in "
+ TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startTime)
+ " ms");
}
return new ArrayList<String>(result);
}
这个方法首先将configurations集合转变为String[]类型的数组(变量candidates,注意跟踪时这个对象的数量为127);然后创建boolean[]类型的变量skip(注意其大小与candidates的大小一致);接着调用本类中的getAutoConfigurationImportFilters()方法获取一个AutoConfigurationImportFilter集合(该集合中只有一个元素,即OnClassCondition,这个类位于org.springframework.boot.autoconfigure.condition包中),并遍历这个集合(首先通过反射调用对象AutoConfigurationImportFilter上的Aware方法,接着调用AutoConfigurationImportFilter对象上的match()方法,实际调用的是OnClassCondition中的match()方法)。这里看一下Filter的体系结构:

这里先不细究OnClassCondition#match()方法的处理逻辑,继续看filter()方法的处理逻辑。第一层for循环调用AutoConfigurationImportFilter类的match()方法后,会得到一个boolean[]类型的match数组,这个数组标识哪些类被匹配到,并在后续操作中导入到Spring容器中。(比如EurekaDiscoveryClientConfigServiceAutoConfiguration位于configurations数组中下标值为115的位置上,而boolean[]类型数组match中下标为115的位置上值为true)。接着第二层循环会遍历boolean[]类型的match数组,并对boolean[]类型的skip数组中的数据进行初始化。如果match数组中对应位置的值为false,则会将skip数组对应位置上的值变更为true,表示后续操作会跳过这个类。接下来会创建一个List<String>类型的集合result,然后遍历candidates集合【这个集合保存了所有通过SPL机制加载的自动化配置类】,同时根据skip数组中的数据判断,当前在处理的类是否要跳过,如果无需跳过,则将其添加到result集合中。最终会将这个集合【这个集合经过filter()操作后,大小会变为43。集合的具体大小需根据您编写的程序来确定】返回给上级调用者,即AutoConfigurationImportSelector#selectImports()方法。最终会将这个集合转为数组返回给更高级的调用者。
这里我有一个问题,filter()方法将过滤的操作委托给了AutoConfigurationImportFilter接口的实现类【这里指的是OnClassCondition类】的match()方法,那这个match()方法究竟做了什么呢?先看一下这个方法的代码:
public boolean[] match(String[] autoConfigurationClasses,
AutoConfigurationMetadata autoConfigurationMetadata) {
ConditionEvaluationReport report = getConditionEvaluationReport();
ConditionOutcome[] outcomes = getOutcomes(autoConfigurationClasses,
autoConfigurationMetadata);
boolean[] match = new boolean[outcomes.length];
for (int i = 0; i < outcomes.length; i++) {
match[i] = (outcomes[i] == null || outcomes[i].isMatch());
if (!match[i] && outcomes[i] != null) {
logOutcome(autoConfigurationClasses[i], outcomes[i]);
if (report != null) {
report.recordConditionEvaluation(autoConfigurationClasses[i], this,
outcomes[i]);
}
}
}
return match;
}
这个方法主要做了这样几件事情:
1) 创建一个ConditionEvaluationReport对象()
2) 创建一个ConditionOutcom[]数组,通过调用本类中的getOutcoms()方法完成此操作。这个方法首先计算程序启动时通过SPL机制加载的自动配置类集合的平均数;接着创建一个OutcomesResolver对象,通过调用本类上的createOutcomesResolver()方法完成;然后再通过new方法创建一个OutcomesResolver对象;再次调用前面创建的两个OutcomesResolver对象上的resolveOutcomes()方法;最后将前面两次的处理结果合并到统一的ConditionOutcome[]数组中。(这里有两点需要注意:1.OutcomesResolver接口的继承体系,具体参考下图。2.这里用到了System.arraycopy()操作,这个操作在我的日常工作中经常用到)。下面首先看依稀啊getOutcomes()方法的源码:
private ConditionOutcome[] getOutcomes(String[] autoConfigurationClasses,
AutoConfigurationMetadata autoConfigurationMetadata) {
// Split the work and perform half in a background thread. Using a single
// additional thread seems to offer the best performance. More threads make
// things worse
int split = autoConfigurationClasses.length / 2;
OutcomesResolver firstHalfResolver = createOutcomesResolver(
autoConfigurationClasses, 0, split, autoConfigurationMetadata);
OutcomesResolver secondHalfResolver = new StandardOutcomesResolver(
autoConfigurationClasses, split, autoConfigurationClasses.length,
autoConfigurationMetadata, this.beanClassLoader);
ConditionOutcome[] secondHalf = secondHalfResolver.resolveOutcomes();
ConditionOutcome[] firstHalf = firstHalfResolver.resolveOutcomes();
ConditionOutcome[] outcomes = new ConditionOutcome[autoConfigurationClasses.length];
System.arraycopy(firstHalf, 0, outcomes, 0, firstHalf.length);
System.arraycopy(secondHalf, 0, outcomes, split, secondHalf.length);
return outcomes;
}
接下来再看一下OutcomesResolver接口的继承体系(这个接口一共有两个实现类),具体如下图所示:
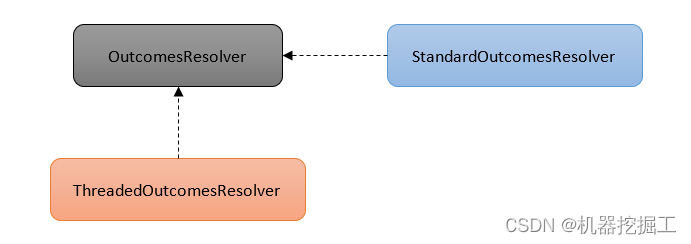
这幅图中的ThreadedOutcomesResolver类持有一个Thread对象和一个OutcomesResolver对象,这个类中的resolveOutcomes()方法的代码很简单,就是调用持有的Thread对象上的join()方法,具体如下所示:
@Override
public ConditionOutcome[] resolveOutcomes() {
try {
this.thread.join();
}
catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
return this.outcomes;
}
相信你对java多线程已经非常了解了,这行代码的主要作用就是主线程会在这里等待直到Thread线程执行完毕。ThreadedOutcomesResolver类的构造方法中会创建一个线程,然后在后台执行ThreadedOutcomesResolver类持有的OutcomesResolver对象上的resolveOutcomes()方法。
3) 创建boolean[]类型的match对象
4) 遍历第2步解析出来的outcomes数组,然后根据match数组相应位置上的数据做进一步处理。如果当前位置值为false且outcomes当前位置的值不为空,则进一步处理,否则直接跳过。
关于上面第2步,我依旧非常迷茫,它究竟做了什么?为什么要这么做呢?这个就要看OnClassCondition类中的getOutcomes()方法了,这个方法在遍历autoConfigurationClasses集合时,会首先拿到对应类(比如:GroovyTemplateAutoConfiguration类,这个类位于org.springframework.boot.autoconfigure.groovy.template包中,它上面配置了@ConditionOnClass注解,具体为:@ConditionalOnClass(MarkupTemplateEngine.class))上配置的@ConditionalOnClass注解中的数据;如果不为空,则执行if分支的逻辑,调用getOutcome()方法,注意这个方法接收了一个集合,这个集合就是前面解析出来的@ConditionalOnClass注解中的数据,譬如:groovy.text.markup.MarkupTemplateEngine,紧接着会调用getMatches()方法得到缺失的类,然后创建一个ConditionOutcome对象。这里判断依赖的类是否缺失用到了MatchType类,这是一个枚举类,其中有两个枚举值:PRESENT和MISSING,他们都依赖于枚举类上的isPresent()方法来确定指定的类是否存在,本质上就是看看能不能通过ClassLoader加载到这个类。加载的具体代码如下所示:
private static boolean isPresent(String className, ClassLoader classLoader) {
if (classLoader == null) {
classLoader = ClassUtils.getDefaultClassLoader();
}
try {
forName(className, classLoader);
return true;
}
catch (Throwable ex) {
return false;
}
}
private static Class<?> forName(String className, ClassLoader classLoader)
throws ClassNotFoundException {
if (classLoader != null) {
return classLoader.loadClass(className);
}
return Class.forName(className);
}
因此第2步的作用是这样的:加载指定字符串所代表的类,如果无法从环境中加载到这个类,那么依赖于这个类的自动配置类就会被忽略。这句话就回答了本段开头提出的那两个问题。关于本小节使用到的知识点的总结:
- 多线程(Thread.join())
- 枚举(定义一个抽象方法,由枚举变量完成实现逻辑的编写)
- 二分操作(使用一个方法遍历集合,不如将他们分成两部分分别遍历)
- 类加载(Class.forName(className)或classLoader.loadClass(className))
2 DeferredImportSelector#selectImports()是如何被调用的?
在同事问我这个问题时,我非常自信,觉得可以立马回答出来,但当跟踪时,我有点糊涂了。原本坚定的立场突然开始松动,原本肯定的答案突然之间变得飘忽不定。因此想在这里再梳理一下,以便加深对这个问题的印象。要回答这个问题,我觉得首先要回顾一下前一节梳理的@Import注解的解析过程,具体过程是这样的:
- ConfigurationClassPostProcessor#processConfigBeanDefinitions(BeanDefinitionRegistry registry)【该方法会调用下面的方法,执行过程一直持续到第6步,接着会调用第7步】
- ConfigurationClassParser#parse(Set<BeanDefinitionHolder> configCandidates)【该方法会调用下面的方法】
- ConfigurationClassParser#parse(AnnotationMetadata metadata, String beanName)【该方法会调用下面的方法】
- ConfigurationClassParser#processConfigurationClass(ConfigurationClass configClass)【该方法会调用下面的方法】
- ConfigurationClassParser#doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)【该方法会调用下面的方法】
- ConfigurationClassParser#processImports(ConfigurationClass configClass, SourceClass currentSourceClass, Collection<SourceClass> importCandidates, boolean checkForCircularImports)【这个方法会首先解析配置类,然后1)判断其是否是ImportSelector实现类,如果是会调用它上面的Aware方法,接着判断这个类是否是DefferredImportSelector的实现类,如果是则创建DeferredImportSelectorHolder对象并将其添加到ConfigurationClassParser类的deferredImportSelectors集合中,如果不是则直接调用该对象上的selectImports()方法得到一个集合,并继续调用本类的processImports()方法解析这个集合;2)如果既不是ImportSelector的实现类,也不是DefferredImportSelector的实现类,但是是ImportBeanDefinitionRegistrar的实现类,则直接实例化,并调用其中的Aware方法,然后调用processImports()方法接收的ConfigurationClass对象上的addImpo9rtBeanDefinitionRegistrar()方法,将这个对象添加到某个元素上;3)如果不是上面两种情况中的任何一种,则直接调用本类的processConfiguration()方法,将这个类当作候选配置类继续解析。注意:这个方法是解析@Import标签的】
- ConfigurationClassParser#processDeferredImportSelectors()【第1步作为入口,调用过第2、3、4、5、6步后会直接调用第7步遍历处理DeferredImportSelectorHolder集合中的元素,这些元素都包装了实际的DeferredImportSelector实现类,注意这里会调用DeferredImportSelector类的selectImports()方法,调完这个方法后会继续调用ConfigurationClassParse类中的processImports()方法解析】
根据这个解析流程,这个问题的答案就一目了然了:DeferredImportSelectorHolder接口实现类的调用是在ConfigurationClassParser类的processDeferredImportSelectors()方法中完成的。在梳理时发现ConfigurationClassParser类中存在几个很关键的内部类,他们分别为:
- CircularImportProblem:
- DeferredImportSelectorHolder:该类在ConfigurationClassParser类的processImports()方法中出现过。后面其又在ConfigurationClassParser类的processDeferredImportSelectors()方法中出现过。这两个方法的具体调用过程可参见上面梳理的处理过程。这个类非常简单,其中只有两个属性,他们的类型分别为ConfigurationClass和DeferredImportSelector。个人理解这个类就是后者的包装类。
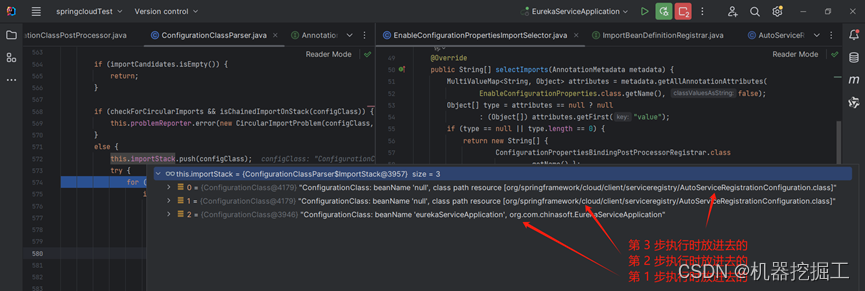
- ImportStack:这是一个堆栈之类的容器,具有先进后出的特性,会在执行解析时保存当前的ConfigurationClass,当解析完成后,会从堆栈中将当前配置类移除掉。这个看后面的截图,截图中importStack中有三个元素。
- SourceClass:该类在ChonfigurationClassParser类的processConfigurationClass()方法中出现过,即上述处理过程的第4步。在第4步中会调用asSourceClass(ConfigurationClass)方法,这个方法会递归处理配置类及其父类。【这里以启动类EurekaServiceApplication为案例进行梳理:asSourceClass(ConfigurationClass)方法接受了一个ConfigurationClass类型的对象,这个对象包装了EurekaServiceApplication对象,并且这个对象上的metadata属性值的实际类型为StandardAnnotationMetadata,所以如果asSourceClass(ConfigurationClass)方法的参数是启动类,则会执行该方法的if分支调用asSourceClass(Class<?>)方法——这个方法首先会执行classType.getAnnotations()方法,相当于解析启动类上的注解,不过这里并不是真的解析,而是测试是否可以解析启动类上的注解,接着会将启动类包装为SourceClass对象返回,具体源码可以看下面的源码展示】
下面展示一下ConfigurationClassParser类中asSourceClass()方法及其重载方法的源码,具体如下所示:
private SourceClass asSourceClass(ConfigurationClass configurationClass) throws IOException {
AnnotationMetadata metadata = configurationClass.getMetadata();
if (metadata instanceof StandardAnnotationMetadata) {
return asSourceClass(((StandardAnnotationMetadata) metadata).getIntrospectedClass());
}
return asSourceClass(metadata.getClassName());
}
SourceClass asSourceClass(Class<?> classType) throws IOException {
try {
// Sanity test that we can read annotations, if not fall back to ASM
classType.getAnnotations();
return new SourceClass(classType);
}
catch (Throwable ex) {
// Enforce ASM via class name resolution
return asSourceClass(classType.getName());
}
}
下面再详细看一下程序解析启动类及其上面@Import注解的案例。注意:下面梳理从程序解析出启动类上面的DeferredImportSelector实现类(这个案例中的启动类上引入了两个注解:@SpringBootApplication、@EnableDiscoveryClient),也就是从ConfigurationClassParser类的processDeferredImportSelectors()方法开始的:
- 调用org.springframework.cloud.client.discovery.EnableDiscoveryClientImportSelector类上的selectImports()方法,这个方法会导入下面几个类,然后调用ConfigurationClassParser类的processImports()方法【调用者为ConfigurationClassParser类的processDeferredImportSelectors()方法】
- org.springframework.cloud.client.serviceregistry.AutoServiceRegistrationConfiguration该类既不是ImportSelector实现类,也不是DeferredImportSelectorHolder实现类,所以在processImports()方法处理过程中,会走最后的else分支,最终会重新调用ConfigurationClassParser类上的processConfigurationClass()方法,这个方法又会继续调用doProcessConfigurationClass()方法,接着这个方法又继续调用doProcessConfigurationClass()方法,最后又继续调用processImports()方法【注意在调用这个方法时,会调用getImports()方法获取这个类及其上面的注解或者父类及其上面的注解上的@Import注解,因此这里会导入一个名为EnableConfigurationPropertiesImportSelector类】。程序在processImports()方法执行过程中会首先调用这个类上的selectImports()方法,然后导入下面整个类。
- org.springframework.boot.context.properties.EnableConfigurationPropertiesImportSelector中ConfigurationPropertiesBeanRegistrar类及org.springframework.boot.context.properties包中的ConfigurationPropertiesBindingPostProcessorRegistrar类。接着程序会继续调用ConfigurationClassParser类中的processImports()方法。后续即按正常流程执行了。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











