






 本文详细解析了HashMap首次扩容的原理,包括容量计算、putVal函数执行、数组与链表的转换条件,以及添加元素的两种情况。适合理解Java HashMap底层实现的读者。
本文详细解析了HashMap首次扩容的原理,包括容量计算、putVal函数执行、数组与链表的转换条件,以及添加元素的两种情况。适合理解Java HashMap底层实现的读者。
先简单介绍一下结论:
- HashMap默认初始化容量大小为16,加载因子为0.75
- 当容量大于临界值(=容量*加载因子)时会扩容为原来的两倍
测试代码如下:
//扩容机制的探究
HashMap hashMap = new HashMap();
for (int i = 0; i < 12; i++) {
hashMap.put(i,i);
}
设置断点跟入,首先进入构造函数如下:

初始化后的hashMap如下:
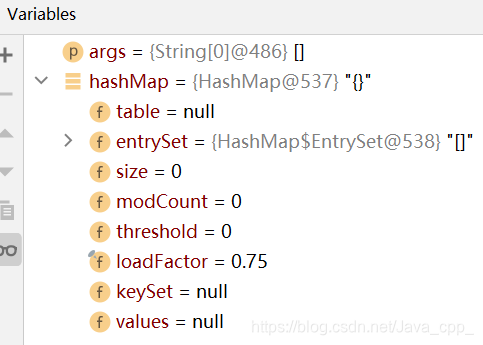
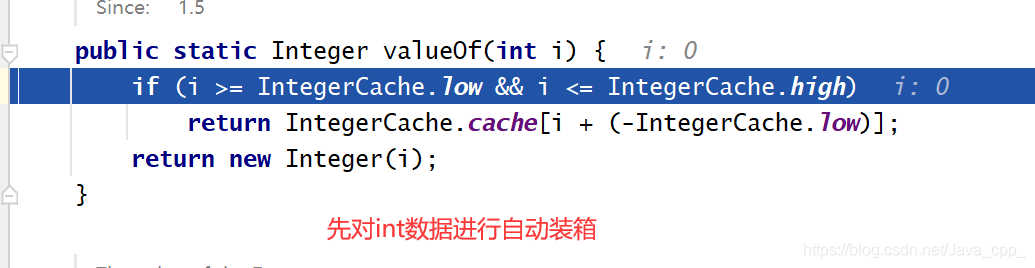
添加数据进行第一次扩容:

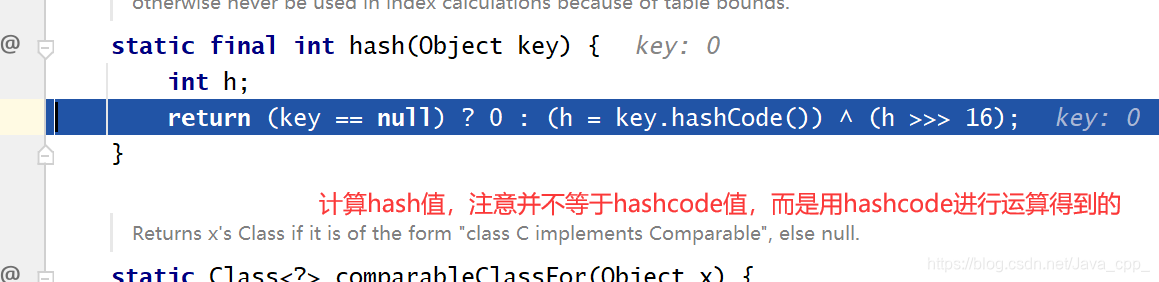
putVal()方法需要hash值,以下是根据key计算hash值的函数
下面来介绍putVal函数,给出源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
现在是首次添加数据,我们来分析如何执行以上代码
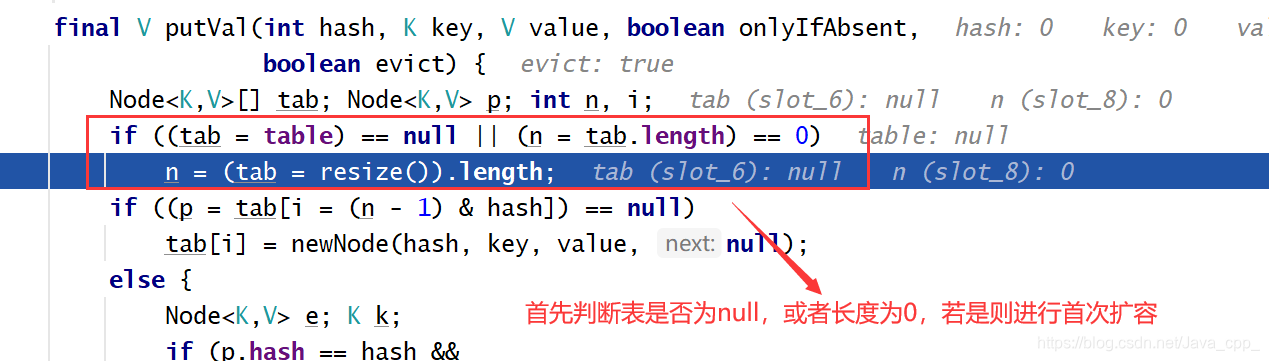
首次扩容将会调用resize()函数,跟入:

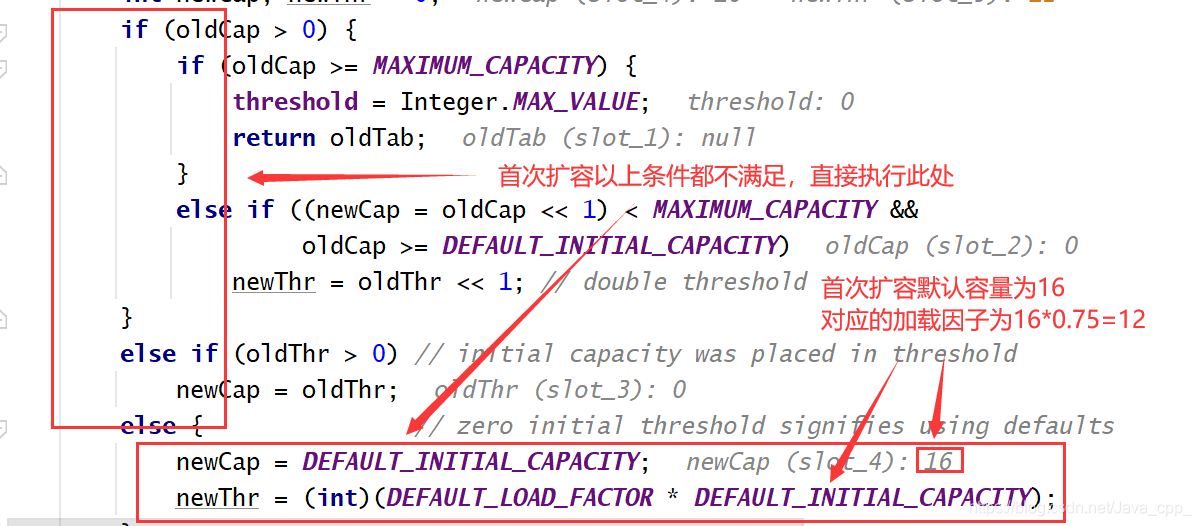
首次扩容就到此完成了,我们回到putVal函数继续跟入看如何进行添加元素
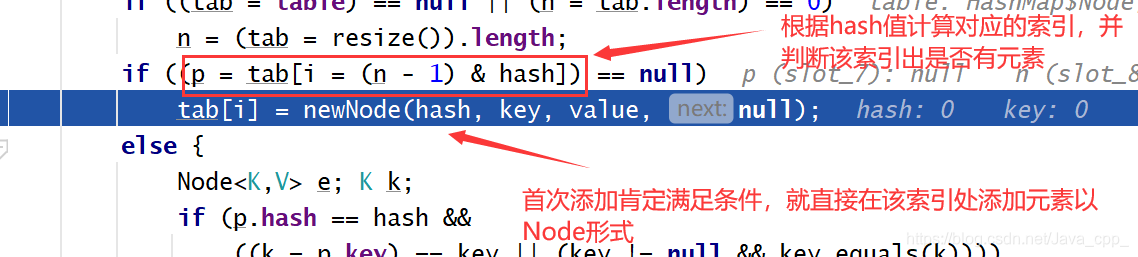

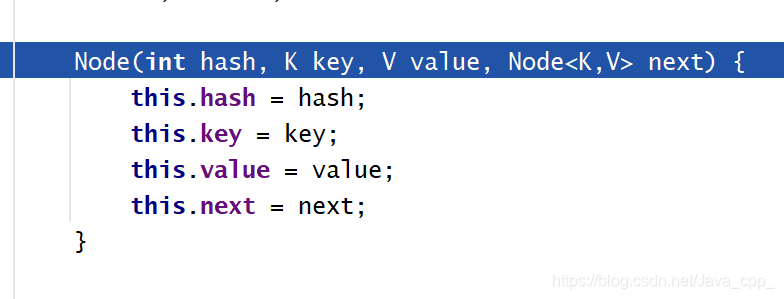
顺便说一下如果要添加元素,计算得到的索引处有元素了,则如何添加:就是以链表的形式添加,具体如下:
第一种情况:

第二种情况:

ps:HashMap底层数据结构从数组+链表转化为数组+红黑树的条件为:
1.链表长度到达8
2.数组长度到达64
同时满足以上两个条件才会树化为数组+红黑树
第三种情况:
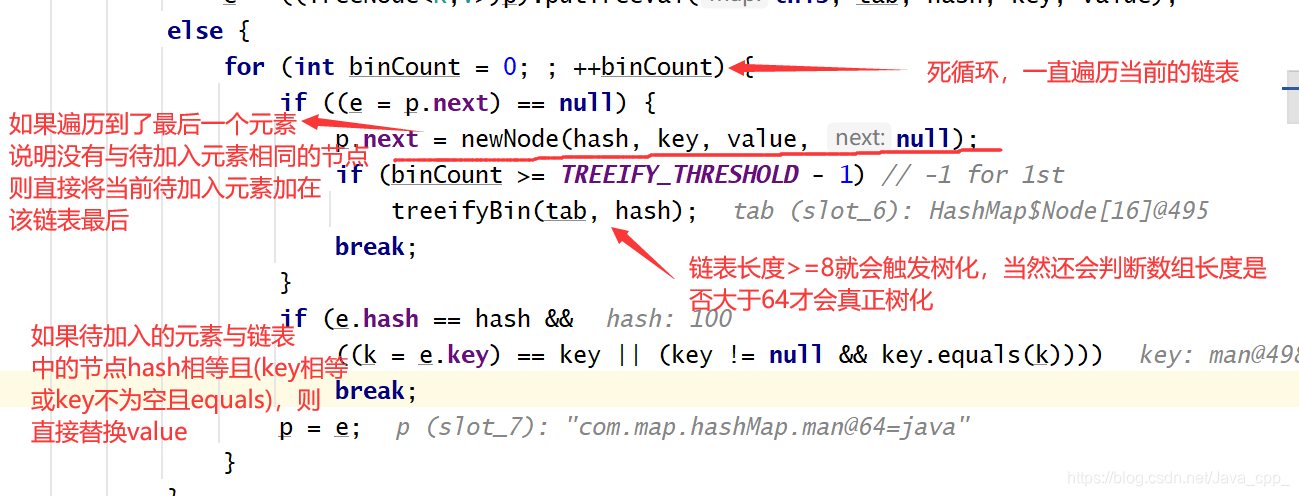
第一和第三两种情况替换value的代码:
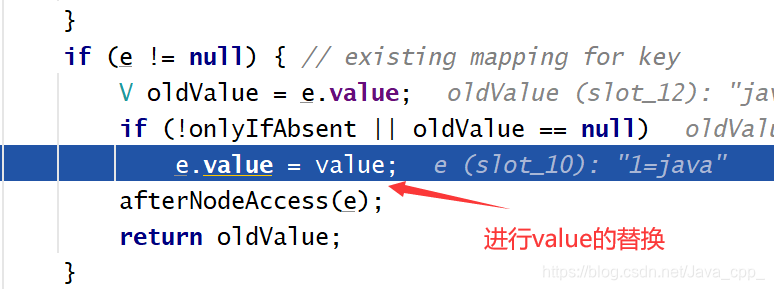
最后进行一次判断添加新元素后的容量是否大于临界值:
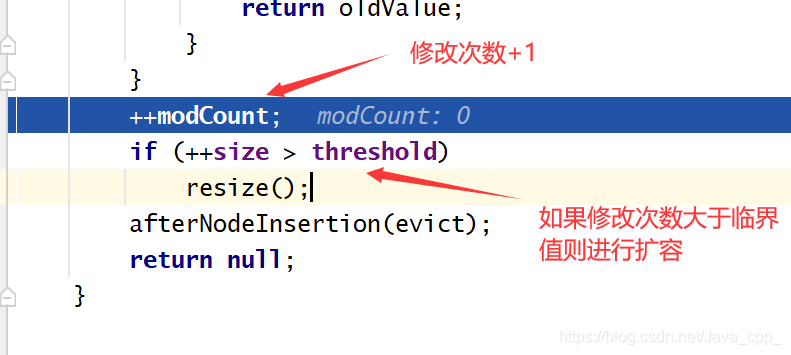
以上就是首次添加元素HashMap进行扩容的底层源码实现,由上面探究可知当HashMap的容量到达12时就会触发新一轮的扩容,接下来我们继续来底层源码探究如何实现:
测试代码:
//扩容机制的探究
HashMap hashMap = new HashMap();
for (int i = 0; i < 12; i++) {
hashMap.put(i,i);
}
hashMap.put(12,12);


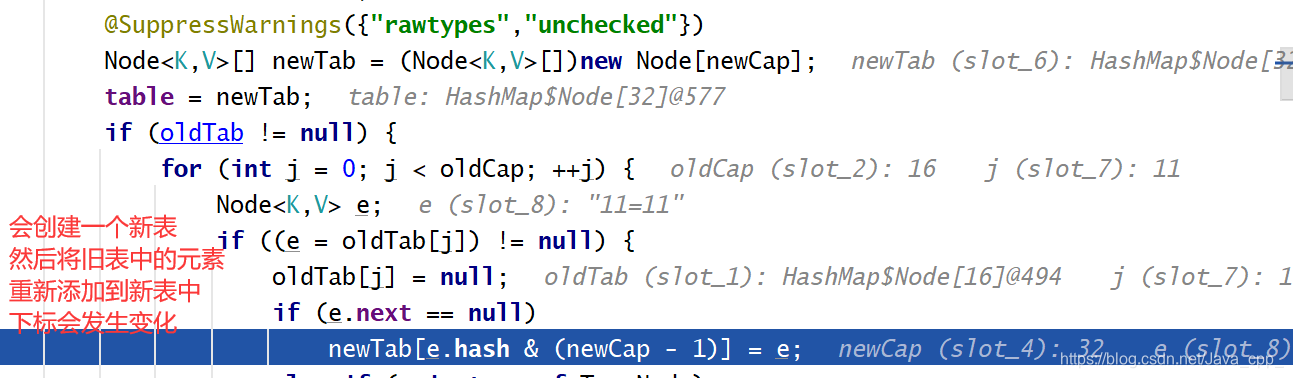
介绍到此结束,希望能帮助到您对于集合源码的学习,强烈建议自己动手debug几遍,只有把每个过程为什么这么走搞懂了,才算真正的学会了,谢谢

















 2105
2105




 到【灌水乐园】发言
到【灌水乐园】发言







