



 本文介绍了在SpringBoot项目中,使用RedisTemplate进行大数据量写入Redis时,对比常规操作与pipelined操作的性能差异。实测显示,pipelined方式性能远超常规方式,主要原因是pipelined减少了连接获取次数并采用了异步非阻塞IO,从而大幅提升效率。
本文介绍了在SpringBoot项目中,使用RedisTemplate进行大数据量写入Redis时,对比常规操作与pipelined操作的性能差异。实测显示,pipelined方式性能远超常规方式,主要原因是pipelined减少了连接获取次数并采用了异步非阻塞IO,从而大幅提升效率。
最近项目上有写入大量数据到 redis 中的需求,使用的是 springboot 集成 redis 客户端,就少不了使用 RedisTemplate 来操作。由于数据量比较多,是需要考虑写入性能问题的,如何才能高效写入到 redis 中呢?通过度娘知道了使用 pipelined 方式性能非常好,但是却没有解释为什么?带着这个疑惑进行了这次的实测。
环境
- redis:使用本机 docker 启动的单节点服务
- springboot 框架集成 redis 客户端
实测
RedisTemplate 的操作 api 有两种:
- 常规操作 API
- pipelined 操作 API
对两种操作 API 进行了简单的测试用例来实测,代码如下:
@SpringBootTest
@RunWith(SpringRunner.class)
public class PerformanceTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void performanceTest() {
// 均执行 2 万次的写入
int batch = 20000;
// 常规API
System.out.println("************ 普通写法 ****************");
String keyPrefix = "pt/performance_";
long begin = System.currentTimeMillis();
for (int i = 0; i < batch; i++) {
redisTemplate.opsForValue().set(keyPrefix + i, keyPrefix + i);
}
System.out.println("普通执行结束,共耗时:" + (System.currentTimeMillis() - begin) + " ms");
// pipeline API
RedisSerializer keySerializer = redisTemplate.getKeySerializer();
RedisSerializer valueSerializer = redisTemplate.getValueSerializer();
begin = System.currentTimeMillis();
redisTemplate.executePipelined((RedisCallback<String>) connection -> {
for (int i = 0; i < batch; i++) {
connection.stringCommands().set(keySerializer.serialize(keyPrefix + i), valueSerializer.serialize(keyPrefix + i));
}
System.out.println("pipeline 结束");
return null;
});
System.out.println("pipeline 执行结束,共耗时:" + (System.currentTimeMillis() - begin) + " ms");
}
}
两种写法均写入 20000 条数据,且key和value均一致;实测结果耗时如下:
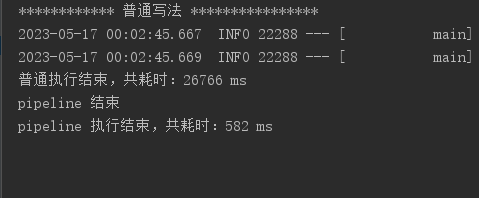
从控制台的输出日志可以看出:普通写法用时 26.76 秒,而 pipeline 只用了 0.58 秒。这性能差了好几个数量级。
why
经过查看源码,发现有两处性能关键点,关键点源代码如下:
1、获取连接的次数不一样。
// redisTemplate.opsForValue().set(...); 调用的 set 方法源码
@Override
public void set(K key, V value) {
byte[] rawValue = rawValue(value);
execute(new ValueDeserializingRedisCallback(key) {
@Override
protected byte[] inRedis(byte[] rawKey, RedisConnection connection) {
// 问题:这个方法的 connection 对象从何而来???
connection.set(rawKey, rawValue);
return null;
}
}, true);
}
// 上面方法的 RedisConnection 从何而来,源码如下:从连接池中获取
@Nullable
public <T> T execute(RedisCallback<T> action, boolean exposeConnection, boolean pipeline) {
Assert.isTrue(initialized, "template not initialized; call afterPropertiesSet() before using it");
Assert.notNull(action, "Callback object must not be null");
RedisConnectionFactory factory = getRequiredConnectionFactory();
RedisConnection conn = null;
try {
if (enableTransactionSupport) {
// only bind resources in case of potential transaction synchronization
conn = RedisConnectionUtils.bindConnection(factory, enableTransactionSupport);
} else {
conn = RedisConnectionUtils.getConnection(factory);
}
... 省略其他代码 ...
return postProcessResult(result, connToUse, existingConnection);
} finally {
RedisConnectionUtils.releaseConnection(conn, factory, enableTransactionSupport);
}
}
即每次调用 set 方法时,都会使用 RedisConnectionFactory 来获取一次连接,虽然是从连接池中获取,但是依然需要取 20000 次。
// redisTemplate.executePipelined(...); 调用的 executePipelined 的源码
@Override
public List<Object> executePipelined(RedisCallback<?> action, @Nullable RedisSerializer<?> resultSerializer) {
return execute((RedisCallback<List<Object>>) connection -> {
// 这个 RedisConnection 对象的获取途经与上面一致:从连接池中获取。
connection.openPipeline();
boolean pipelinedClosed = false;
try {
// 调用函数的回调方法,将 RedisConnection 对象传递进去实现业务操作
Object result = action.doInRedis(connection);
if (result != null) {
throw new InvalidDataAccessApiUsageException(
"Callback cannot return a non-null value as it gets overwritten by the pipeline");
}
List<Object> closePipeline = connection.closePipeline();
pipelinedClosed = true;
return deserializeMixedResults(closePipeline, resultSerializer, hashKeySerializer, hashValueSerializer);
} finally {
if (!pipelinedClosed) {
connection.closePipeline();
}
}
});
}
使用 pipelined 方式只需要获取一次连接对象,因为循环是写在回调函数里面的。这里就形成了一次性能差异。
2、执行的方式不一样
上面两种 API 无论是那种操作,最终调用的都是相同实现类的 set 方法,redis 客户端的实现类代码:
org.springframework.data.redis.connection.lettuce.LettuceStringCommands
@Override
public Boolean set(byte[] key, byte[] value) {
// 非空校验代码略...
try {
if (isPipelined()) {
// 如果开启了 pipelined 模式,获取的是 异步连接,进行异步操作
pipeline(
connection.newLettuceResult(getAsyncConnection().set(key, value), Converters.stringToBooleanConverter()));
return null;
}
if (isQueueing()) {
// 如果开启了 队列 模式,通用是异步操作
transaction(
connection.newLettuceResult(getAsyncConnection().set(key, value), Converters.stringToBooleanConverter()));
return null;
}
// 常规模式下,使用的是同步操作
return Converters.stringToBoolean(getConnection().set(key, value));
} catch (Exception ex) {
throw convertLettuceAccessException(ex);
}
}
这里是性能差异的关键点,普通模式使用的是单线程同步操作(阻塞IO),而 pipelined 模式是使用的单线程异步操作(非阻塞IO)。
原因结论:
- 普通模式获取连接的次数就是循环的次数,而 pipelined 只获取一次。
- 普通模式是同步阻塞IO写数据,而 pipelined 是异步非阻塞IO写数据。

















 2399
2399




 到【灌水乐园】发言
到【灌水乐园】发言







