



背景
本章分析分区两个分区变更操作:
1)分区新增;
2)分区重分配;
分区变更操作涉及两个重要的znode。
/brokers/topics/{topic}:存储了topic分区的分配情况,称为assignment。
{"version":2,"partitions":{"0":[111,222],"1":[222,333],"2":[333,111]},"adding_replicas":{},"removing_replicas":{}}
/brokers/topics/{topic}/partitions/{partitionId}/state:存储了分区的状态,包含当前分区的leader和isr列表,称为LeaderAndIsr。
{"controller_epoch":70,"leader":111,"version":1,"leader_epoch":3,"isr":[111,222]}
注:
1)基于Kafka2.6.3,使用zookeeper做元数据管理;
2)AutoMQ相较于Kafka的优势:如秒级分区重分配、秒级扩缩容、持续数据自平衡;(www.automq.com/docs/automq…)
一、新增分区
1-1、案例
创建一个2分区2副本的topic。
./kafka-topics.sh --create --topic topicA --bootstrap-server localhost:9092 --replication-factor 2 --partitions 2
Created topic topicA.
./kafka-topics.sh --describe --bootstrap-server localhost:9092
Topic: topicA PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: topicA Partition: 0 Leader: 111 Replicas: 111,333 Isr: 111,333
Topic: topicA Partition: 1 Leader: 333 Replicas: 333,222 Isr: 333,222
在Kafka4.0前,一个分区只能被消费组内的一个消费者实例消费。
4.0实现了share group,类比RocketMQ5的POP消费。
为了提升消费能力,这里扩容3个分区,但是可以看到leader分配不均匀。
./kafka-topics.sh --alter --topic topicA --bootstrap-server localhost:9092 --partitions 3
Topic: topicA PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: topicA Partition: 0 Leader: 111 Replicas: 111,333 Isr: 111,333
Topic: topicA Partition: 1 Leader: 333 Replicas: 333,222 Isr: 333,222
Topic: topicA Partition: 2 Leader: 333 Replicas: 333,111 Isr: 333,111
1-2、处理CreatePartitionsRequest
CreatePartitionsRequest:创建partition请求中的count是目标partition数量,比如这里是3。
public class CreatePartitionsRequest extends AbstractRequest {
private final CreatePartitionsRequestData data;
}
public class CreatePartitionsRequestData implements ApiMessage {
private List<CreatePartitionsTopic> topics;
private int timeoutMs;
private boolean validateOnly;
}
static public class CreatePartitionsTopic implements Message {
private String name;
private int count;
// 可以手动指定assignment,不让controller来分配
private List<CreatePartitionsAssignment> assignments;
}
AdminManager#createPartitions:broker处理CreatePartitionsRequest。
def createPartitions(timeout: Int,
newPartitions: Seq[CreatePartitionsTopic],
validateOnly: Boolean,
listenerName: ListenerName,
callback: Map[String, ApiError] => Unit): Unit = {
// 查询/brokers/ids及子节点 获取所有broker
val allBrokers = adminZkClient.getBrokerMetadatas()
val allBrokerIds = allBrokers.map(_.id)
val metadata = newPartitions.map { newPartition =>
val topic = newPartition.name
try {
// 查询/brokers/topic/{topic} 校验topic存在,获取assignment
val existingAssignment = zkClient.getFullReplicaAssignmentForTopics(immutable.Set(topic)).map {
case (topicPartition, assignment) =>
if (assignment.isBeingReassigned) {
throw new ReassignmentInProgressException()
}
topicPartition.partition -> assignment
}
if (existingAssignment.isEmpty)
throw new UnknownTopicOrPartitionException()
// 校验新增分区数量 > 0
val oldNumPartitions = existingAssignment.size
val newNumPartitions = newPartition.count
val numPartitionsIncrement = newNumPartitions - oldNumPartitions
if (numPartitionsIncrement < 0) {
throw new InvalidPartitionsException()
} else if (numPartitionsIncrement == 0) {
throw new InvalidPartitionsException()
}
// 用户指定了新分区的assignment,校验broker存在
val newPartitionsAssignment = Option(newPartition.assignments)
.map { assignmentMap =>
val assignments = assignmentMap.asScala.map {
createPartitionAssignment => createPartitionAssignment.brokerIds.asScala.map(_.toInt)
}
val unknownBrokers = assignments.flatten.toSet -- allBrokerIds
if (unknownBrokers.nonEmpty)
throw new InvalidReplicaAssignmentException()
if (assignments.size != numPartitionsIncrement)
throw new InvalidReplicaAssignmentException()
assignments.zipWithIndex.map { case (replicas, index) =>
existingAssignment.size + index -> replicas
}.toMap
}
// 调用zk,更新/brokers/topic/{topic}
val updatedReplicaAssignment = adminZkClient.addPartitions(topic, existingAssignment, allBrokers,
newPartition.count, newPartitionsAssignment, validateOnly = validateOnly)
CreatePartitionsMetadata(topic, updatedReplicaAssignment.keySet, ApiError.NONE)
} catch {
case e: AdminOperationException =>
CreatePartitionsMetadata(topic, Set.empty, ApiError.fromThrowable(e))
case e: ApiException =>
CreatePartitionsMetadata(topic, Set.empty, ApiError.fromThrowable(e))
}
}
// ...
// 提交延迟任务,如果创建分区超时,响应客户端
val delayedCreate = new DelayedCreatePartitions(timeout, metadata, this, callback)
val delayedCreateKeys = newPartitions.map(createPartitionTopic => TopicKey(createPartitionTopic.name))
topicPurgatory.tryCompleteElseWatch(delayedCreate, delayedCreateKeys)
}
AdminZkClient#addPartitions:使用和创建topic一样的分配策略,为新增分区分配assignment,比如333,111,调用zk更新/brokers/topics/{topic}。
def addPartitions(topic: String,
existingAssignment: Map[Int, ReplicaAssignment],
allBrokers: Seq[BrokerMetadata],
numPartitions: Int = 1,
replicaAssignment: Option[Map[Int, Seq[Int]]] = None,
validateOnly: Boolean = false): Map[Int, Seq[Int]] = {
// p0的assignment
val existingAssignmentPartition0 = existingAssignment.getOrElse(0,
throw new AdminOperationException()).replicas
val partitionsToAdd = numPartitions - existingAssignment.size
// 为新分区生成assignment分配策略
val proposedAssignmentForNewPartitions = replicaAssignment.getOrElse {
val startIndex = math.max(0, allBrokers.indexWhere(_.id >= existingAssignmentPartition0.head))
AdminUtils.assignReplicasToBrokers(allBrokers, partitionsToAdd, existingAssignmentPartition0.size,
startIndex, existingAssignment.size)
}
val proposedAssignment = existingAssignment ++ proposedAssignmentForNewPartitions.map { case (tp, replicas) =>
tp -> ReplicaAssignment(replicas, List(), List())
}
if (!validateOnly) {
// 更新zk的assignment,触发/brokers/topics/{topic}监听逻辑
writeTopicPartitionAssignment(topic, proposedAssignment, isUpdate = true)
}
proposedAssignment.map { case (k, v) => k -> v.replicas }
}
1-3、处理/brokers/topics/{topic}变更
controller在两个入口会监听/brokers/topics/{topic}变更:
1)controller上线;2)监听/brokers/topics子节点新增topic
// kafka.controller.KafkaController#onControllerFailover
// kafka.controller.KafkaController#initializeControllerContext
// controller上线
private def initializeControllerContext(): Unit = {
// ...
// getChildren /brokers/topics,获取所有topic
controllerContext.setAllTopics(zkClient.getAllTopicsInCluster(true))
// 对所有/brokers/topics/{topic}注册监听
registerPartitionModificationsHandlers(controllerContext.allTopics.toSeq)
}
// kafka.controller.KafkaController#processTopicChange
// /brokers/topics子节点新增topic
private def processTopicChange(): Unit = {
// 注册/brokers/topics/{topic}监听
registerPartitionModificationsHandlers(newTopics.toSeq)
}
controller收到watch /brokers/topics/{topic}回调,将通知放入controller-event-thread单线程处理变更。
KafkaController#processPartitionModifications:controller处理/brokers/topics/{topic}变更。
查询/brokers/topics/{topic}发现assignment比内存多了p2分区,更新内存assignment。
private def processPartitionModifications(topic: String): Unit = {
// 自己不是controller 返回
if (!isActive) return
// 查询zk中的assignment
val partitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(immutable.Set(topic))
// zk数据-内存数据,得到新增的partition
// 发现新增p2,对应replicas=111,333
val partitionsToBeAdded = partitionReplicaAssignment.filter { case (topicPartition, _) =>
controllerContext.partitionReplicaAssignment(topicPartition).isEmpty
}
if (partitionsToBeAdded.nonEmpty) {
// 更新内存assignment
partitionsToBeAdded.foreach { case (topicPartition, assignedReplicas) =>
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, assignedReplicas)
}
// 同新增topic
onNewPartitionCreation(partitionsToBeAdded.keySet)
}
}
KafkaController#onNewPartitionCreation:同第一章创建topic,再复习一下。
1)初始化partition leader和isr列表,assignment中的在线broker进入isr列表,isr列表中第一个broker成为leader;
2)创建 /brokers/topics/{topic}/partitions/{partitionId}/state节点持久化partition状态LeaderAndIsr;
3)controllerContext缓存LeaderAndIsr;
4)发送LeaderAndIsrRequest给isr中的副本,发送UpdateMetadataRequest给所有存活brokers;
5)isr中的副本收到LeaderAndIsr,自己成为leader或follower,创建log和segment文件;
6)存活brokers收到UpdateMetadataRequest,更新MetadataCache,如果当前broker有挂起的topic相关请求,比如本次新增partition的请求,则响应客户端;
private def onNewPartitionCreation(newPartitions: Set[TopicPartition]): Unit = {
// partition状态NewPartition 更新内存 partition->NewPartition
partitionStateMachine.handleStateChanges(newPartitions.toSeq, NewPartition)
// replica状态NewReplica 更新内存replica->NewReplica
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, NewReplica)
// partition状态OnlinePartition
// 初始化isr列表、选leader、zk持久化/kafka/brokers/topics/{topic}/partitions及其子节点
// 发送LeaderAndIsrRequest和UpdateMetadataRequest
partitionStateMachine.handleStateChanges(
newPartitions.toSeq,
OnlinePartition,
Some(OfflinePartitionLeaderElectionStrategy(false))
)
// replica状态OnlineReplica
replicaStateMachine.handleStateChanges(controllerContext.replicasForPartition(newPartitions).toSeq, OnlineReplica)
}
二、重分配(reassign)
2-1、案例
在多种情况下会用到kafka的reassign分区重分配功能,这里假设需要对集群缩容,下掉333节点。
需要将333上的所有topic分区,迁移到其他broker上。假设333节点只有TopicA的p1和p2分区。
./kafka-topics.sh --describe --bootstrap-server localhost:9092
Topic: topicA PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: topicA Partition: 0 Leader: 111 Replicas: 111,333 Isr: 111,333
Topic: topicA Partition: 1 Leader: 333 Replicas: 333,222 Isr: 333,222
Topic: topicA Partition: 2 Leader: 333 Replicas: 333,111 Isr: 333,111
创建topics-to-move.json文件,包含333节点上所有topic,这里只有TopicA。
cat topics-to-move.json
{
"topics": [
{ "topic": "topicA" }
],
"version": 1
}
生成新的分配策略,指定分配在111和222节点上。
注:分配策略和创建topic的时候使用的是同一种算法,见AdminUtils#assignReplicasToBrokers。p0的replicas从111,333变为222,111,这个顺序并不会将leader从111变为222,后面reassign的时候会判断新assignment中老leader是否存在,如果存在则不会选新leader。
./kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \
--topics-to-move-json-file topics-to-move.json --broker-list "111,222" --generate
# 当前assignment
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topicA","partition":0,"replicas":[111,333],"log_dirs":["any","any"]},{"topic":"topicA","partition":1,"replicas":[333,222],"log_dirs":["any","any"]},{"topic":"topicA","partition":2,"replicas":[333,111],"log_dirs":["any","any"]}]}
# 建议assignment
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"topicA","partition":0,"replicas":[222,111],"log_dirs":["any","any"]},{"topic":"topicA","partition":1,"replicas":[111,222],"log_dirs":["any","any"]},{"topic":"topicA","partition":2,"replicas":[222,111],"log_dirs":["any","any"]}]}
将建议的assignment配置(也可以自行修改)保存到reassignment.json执行reassign:
./kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \
--reassignment-json-file reassignment.json --execute
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for topicA-0,topicA-1,topicA-2
校验reassign进度:
./kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \
--reassignment-json-file reassignment.json --verify
Status of partition reassignment:
Reassignment of partition topicA-0 is complete.
Reassignment of partition topicA-1 is complete.
Reassignment of partition topicA-2 is complete.
2-2、处理AlterPartitionReassignmentsRequest
client调用任一broker获取集群元数据,发现controller节点,发送AlterPartitionReassignmentsRequest。
AlterPartitionReassignmentsRequest:可以针对多个topic多个partition进行reassign。
public class AlterPartitionReassignmentsRequest extends AbstractRequest {
private final AlterPartitionReassignmentsRequestData data;
}
public class AlterPartitionReassignmentsRequestData implements ApiMessage {
private int timeoutMs;
private List<ReassignableTopic> topics;
}
static public class ReassignableTopic implements Message {
private String name;
private List<ReassignablePartition> partitions;
}
static public class ReassignablePartition implements Message {
private int partitionIndex;
private List<Integer> replicas;
}
KafkaApis#handleAlterPartitionReassignmentsRequest:controller收到请求,按照topic+partition分组,提交ApiPartitionReassignment到controller-event-thread单线程处理。
def handleAlterPartitionReassignmentsRequest(request: RequestChannel.Request): Unit = {
val alterPartitionReassignmentsRequest = request.body[AlterPartitionReassignmentsRequest]
def sendResponseCallback(result: Either[Map[TopicPartition, ApiError], ApiError]): Unit = {
// 响应客户端
}
// 按照topic-partition分组
val reassignments = alterPartitionReassignmentsRequest.data.topics.asScala.flatMap {
reassignableTopic => reassignableTopic.partitions.asScala.map {
reassignablePartition =>
val tp = new TopicPartition(reassignableTopic.name, reassignablePartition.partitionIndex)
tp -> Some(reassignablePartition.replicas.asScala.map(_.toInt))
}
}.toMap
controller.alterPartitionReassignments(reassignments, sendResponseCallback)
}
def alterPartitionReassignments(partitions: Map[TopicPartition,
Option[Seq[Int]]],
callback: AlterReassignmentsCallback): Unit =
{
// 放入controller-event-thread单线程处理
eventManager.put(ApiPartitionReassignment(partitions, callback))
}
2-3、再看ReplicaAssignment
partition的assignment,存储在/brokers/topics/{topic}的数据部分,包含3部分。
1)partitions:当前生效的partition和关联副本;
2)adding_replicas:正在新增副本的partition和关联副本,reassign期间才存在;
3)removing_replicas:正在减少副本的的partition和关联副本,reassign期间才存在;
{
"partitions":{"0":[111,333],"1":[333,222]},
"adding_replicas":{},
"removing_replicas":{}
}
ReplicaAssignment是在内存中的assignment,replicas对应zk中的partitions。
案例中topicA的p0分区reassign前为:replicas=111和333,addingReplicas和removingReplicas为空。
case class ReplicaAssignment private (replicas: Seq[Int],
addingReplicas: Seq[Int],
removingReplicas: Seq[Int]) {
lazy val originReplicas: Seq[Int] = replicas.diff(addingReplicas)
lazy val targetReplicas: Seq[Int] = replicas.diff(removingReplicas)
}
controller将集群元数据缓存在ControllerContext。
partitionAssignments缓存了每个partition的ReplicaAssignment。
partitionLeadershipInfo缓存了每个partition的leader和isr列表。
class ControllerContext {
val allTopics = mutable.Set.empty[String]
// topic -> partition -> ReplicaAssignment
val partitionAssignments = mutable.Map.empty[String, mutable.Map[Int, ReplicaAssignment]]
// partition ->
// {"controller_epoch":1,"leader":111,"leader_epoch":1,"isr":[111,333]}
val partitionLeadershipInfo = mutable.Map.empty[TopicPartition, LeaderIsrAndControllerEpoch]
}
ReplicaAssignment#reassignTo:reassign不是一步完成的,通过reassignTo构建一个新的中间态ReplicaAssignment
1)replicas:副本全集,目标副本222和111+当前副本111和333去重,即111、222、333;
2)addingReplicas:新增的副本,即222;
3)removingReplicas:删除的副本,即333;
case class ReplicaAssignment private (replicas: Seq[Int],
addingReplicas: Seq[Int],
removingReplicas: Seq[Int]) {
lazy val originReplicas: Seq[Int] = replicas.diff(addingReplicas)
lazy val targetReplicas: Seq[Int] = replicas.diff(removingReplicas)
// target = 222,111
def reassignTo(target: Seq[Int]): ReplicaAssignment = {
// target = 222,111 + originReplicas = 111,333 去重
val fullReplicaSet = (target ++ originReplicas).distinct
// 新的assignment
ReplicaAssignment(
fullReplicaSet, // [111,222,333]
fullReplicaSet.diff(originReplicas), // 新增222
fullReplicaSet.diff(target) // 删除333
)
}
}
KafkaController#processApiPartitionReassignment:
回到controller-event-thread线程,这里循环partition构造新的ReplicaAssignment,即上面的中间态ReplicaAssignment,onPartitionReassignment处理完所有partition后响应客户端。
private def processApiPartitionReassignment(
reassignments: Map[TopicPartition, Option[Seq[Int]]],
callback: AlterReassignmentsCallback): Unit = {
if (!isActive) { // 当前broker已经不是controller,返回
callback(Right(new ApiError(Errors.NOT_CONTROLLER)))
} else {
val reassignmentResults = mutable.Map.empty[TopicPartition, ApiError]
val partitionsToReassign = mutable.Map.empty[TopicPartition, ReplicaAssignment]
reassignments.foreach { case (tp, targetReplicas) =>
val maybeApiError = targetReplicas.flatMap(validateReplicas(tp, _))
maybeApiError match {
case None =>
// 构建新的assignment
maybeBuildReassignment(tp, targetReplicas) match {
// 将新的assignment放入partitionsToReassign,继续后续步骤
case Some(context) => partitionsToReassign.put(tp, context)
case None => reassignmentResults.put(tp, new ApiError(Errors.NO_REASSIGNMENT_IN_PROGRESS))
}
case Some(err) =>
reassignmentResults.put(tp, err)
}
}
// 后续处理
reassignmentResults ++= maybeTriggerPartitionReassignment(partitionsToReassign)
// 响应客户端
callback(Left(reassignmentResults))
}
}
private def maybeBuildReassignment(topicPartition: TopicPartition,
targetReplicasOpt: Option[Seq[Int]]): Option[ReplicaAssignment] = {
val replicaAssignment = controllerContext.partitionFullReplicaAssignment(topicPartition)
if (replicaAssignment.isBeingReassigned) {
// reassign正在进行,暂时不看
val targetReplicas = targetReplicasOpt.getOrElse(replicaAssignment.originReplicas)
Some(replicaAssignment.reassignTo(targetReplicas))
} else {
// 注意reassignTo,构建新的assignment
targetReplicasOpt.map { targetReplicas =>
replicaAssignment.reassignTo(targetReplicas)
}
}
}
private def maybeTriggerPartitionReassignment(reassignments: Map[TopicPartition, ReplicaAssignment]): Map[TopicPartition, ApiError] = {
reassignments.map { case (tp, reassignment) =>
// 循环处理每个topic-partition对应的新assign
val apiError = {
onPartitionReassignment(tp, reassignment)
ApiError.NONE
// ... 忽略异常处理
}
tp -> apiError
}
}
2-4、主流程
真正进入reassign主流程,入参ReplicaAssignment即为上面reassignTo返回的中间状态。
KafkaController#onPartitionReassignment:方法被调用的情况有5种
1)reassign请求触发,刚进入reassign流程;
2)通过创建/admin/reassign/partitions这个znode触发;(不同的reassign方式,忽略)
3)reassign即将完成,监听/brokers/topics/{topic}/partitions/{partition}/state变更触发;
4)controller发现reassign相关副本上线触发(监听/brokers/ids);
5)当前broker作为controller启动,或老controller下线当前broker成为新controller,发现某个partition存在adding或removing的replica副本,代表reassign进行到一半,需要继续reassign流程;
/**
* This callback is invoked:
* 1. By the AlterPartitionReassignments API
* 2. By the reassigned partitions listener which is triggered when the /admin/reassign/partitions znode is created
* 3. When an ongoing reassignment finishes - this is detected by a change in the partition's ISR znode
* 4. Whenever a new broker comes up which is part of an ongoing reassignment
* 5. On controller startup/failover
*/
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
}
这里暂时只考虑集群处于稳定状态(其他逻辑也较好理解,只要zk里有数据,controller的状态都能够恢复),onPartitionReassignment会先经过1再经过3,最终完成reassign。
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
// 先处理p0,假设原始p0=[111,333],要变更为[222,111]
// reassignment={replicas=[111,333,222], addingReplicas=[222], removingReplicas=[333]}
// 更新assignment
updateCurrentReassignment(topicPartition, reassignment)
val addingReplicas = reassignment.addingReplicas // 222
val removingReplicas = reassignment.removingReplicas // 333
// 判断reassign是否完成
if (!isReassignmentComplete(topicPartition, reassignment)) {
// 未完成,说明reassignment中还有副本未进入isr列表 场景1
// ...
} else {
// 已完成,说明reassignment中的所有副本,都进入了isr列表 场景3
// ...
}
}
【1】KafkaController#updateCurrentReassignment:无论是哪个入口进入,都需要将入参ReplicaAssignment持久化到zk,然后更新到controllerContext内存,监听正在处理的partition的状态,通过controllerContext.partitionsBeingReassigned记录partition正在reassign。
private def updateCurrentReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
val currentAssignment = controllerContext.partitionFullReplicaAssignment(topicPartition)
if (currentAssignment != reassignment) {
// U1. Update assignment state in zookeeper
updateReplicaAssignmentForPartition(topicPartition, reassignment)
// U2. Update assignment state in memory
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, reassignment)
}
// 监听/brokers/topics/{topic}/partitions/{partitionId}/state
val reassignIsrChangeHandler = new PartitionReassignmentIsrChangeHandler(eventManager, topicPartition)
zkClient.registerZNodeChangeHandler(reassignIsrChangeHandler)
// controllerContext记录partition正在被reassign
controllerContext.partitionsBeingReassigned.add(topicPartition)
}
至此zk中/brokers/topics/topicA的数据如下,因为是循环partition处理,这里只考虑p0的数据,其他分区同理。
{
"partitions":{"0":[111,222,333],"1":[333,222],"2":[333,111]},
"adding_replicas":{"0":[222]},
"removing_replicas":{"0":[333]}
}
【2】KafkaController#isReassignmentComplete:判断reassign是否完成。
reassign完成的标志是,目标副本集都在isr列表中,当前案例中,p0分区要求111和222都在isr中,reassign开始当然只有原始副本111和333在isr中。
private def isReassignmentComplete(partition: TopicPartition, assignment: ReplicaAssignment): Boolean = {
if (!assignment.isBeingReassigned) {
// 如果adding和removing本身就是空,则reassign已经完成
true
} else {
// 查询/brokers/topics/topicA/partitions/0/state
zkClient.getTopicPartitionStates(Seq(partition)).get(partition).exists { leaderIsrAndControllerEpoch =>
val isr = leaderIsrAndControllerEpoch.leaderAndIsr.isr.toSet
val targetReplicas = assignment.targetReplicas.toSet
// true-目标replicas都在isr中
targetReplicas.subsetOf(isr)
}
}
}
【3】KafkaController#onPartitionReassignment:根据目标replicas是否都在isr中,分为两阶段。
一阶段,reassign未完成,新replica未进入isr列表(p0分区的222),这时候需要controller通知新replica,让其与leader副本同步;
二阶段,reassign完成,因为监听了partition状态得知新replica进入isr,controller可以将assignment更新为用户期望的目标结果(p0分区=111和222);
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
// 标记topic正在reassign,不能删除
topicDeletionManager.markTopicIneligibleForDeletion(Set(topicPartition.topic))
// 1. 更新assignment,并监听/brokers/topics/topicA/partitions/0/state
updateCurrentReassignment(topicPartition, reassignment)
val addingReplicas = reassignment.addingReplicas // 222
val removingReplicas = reassignment.removingReplicas // 333
// 2. 判断reassign是否完成
if (!isReassignmentComplete(topicPartition, reassignment)) {
// case1 reassign未完成,新增副本222还未进入isr
// 2-1. 发送LeaderAndIsr,新增副本222会做出反应,与leader同步数据
updateLeaderEpochAndSendRequest(topicPartition, reassignment)
// 2-2. 新增的replica状态为NewReplica
startNewReplicasForReassignedPartition(topicPartition, addingReplicas)
} else {
// case2 reassign完成,新增副本222已进入isr
// 2-1. 发送LeaderAndIsr给所有副本111、222、333
replicaStateMachine.handleStateChanges(addingReplicas.map(PartitionAndReplica(topicPartition, _)), OnlineReplica)
// 2-2. 更新内存,为最终状态 = [222,111]
val completedReassignment = ReplicaAssignment(reassignment.targetReplicas)
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, completedReassignment)
// 2-3. 如果新的分配方案导致老leader下线,则重新选举leader
moveReassignedPartitionLeaderIfRequired(topicPartition, completedReassignment)
// 2-4. 处理移除副本333 replica -> OfflineReplica
stopRemovedReplicasOfReassignedPartition(topicPartition, removingReplicas)
// 2-5. 更新ZK,老分区不变,这个正在处理的新分区的assignment = [222,111]
updateReplicaAssignmentForPartition(topicPartition, completedReassignment)
// 2-6. 取消监听/brokers/topics/{topic}/partitions/{partition}/state
removePartitionFromReassigningPartitions(topicPartition, completedReassignment)
// 2-7. 发送UpdateMetadataRequest通知所有broker更新元数据
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
// 2-8. 标记topic reassign完成,允许delete
topicDeletionManager.resumeDeletionForTopics(Set(topicPartition.topic))
}
}
下面分两个阶段来分析reassign。
2-5、reassign未完成
znode=/brokers/topics/topicA的状态如下,仍然存在adding和removing的副本。
{
"partitions":{"0":[111,222,333],"1":[333,222],"2":[333,111]},
"adding_replicas":{"0":[222]},
"removing_replicas":{"0":[333]}
}
znode=/brokers/topics/topicA/partitions/0/state的状态如下。
{"controller_epoch":64,"leader":111,"version":1,"leader_epoch":6,"isr":[111,333]}
KafkaController#onPartitionReassignment:controller判断目标副本中222还未进入isr。
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
// 先处理p0,假设原始p0=[111,333],要变更为[222,111]
// reassignment={replicas=[111,333,222], addingReplicas=[222], removingReplicas=[333]}
updateCurrentReassignment(topicPartition, reassignment)
val addingReplicas = reassignment.addingReplicas // 222
val removingReplicas = reassignment.removingReplicas // 333
if (!isReassignmentComplete(topicPartition, reassignment)) {
// case1 reassign未完成,新增副本222还未进入isr
// 发送LeaderAndIsrRequest给所有partition的副本,包含adding和removingReplicas,
// 新增的replica成为follower,与leader同步,但还未进入isr
updateLeaderEpochAndSendRequest(topicPartition, reassignment)
// 新增的replica->NewReplica 内存
startNewReplicasForReassignedPartition(topicPartition, addingReplicas)
} else {
// case2 说明目标副本都进入了isr列表
// ...
}
}
KafkaController#updateLeaderEpochAndSendRequest:controller
1)在确保controller自身任期合法的情况下,更新/brokers/topics/topicA/partitions/0/state的leader任期+1并缓存到controllerContext;
2)向分区中所有副本(111、222、333)发送LeaderAndIsrRequest;
private def updateLeaderEpochAndSendRequest(topicPartition: TopicPartition,
assignment: ReplicaAssignment): Unit = {
val stateChangeLog = stateChangeLogger.withControllerEpoch(controllerContext.epoch)
// 更新一下partition的leader epoch,这样LeaderAndIsrRequest才能被其他broker接受
updateLeaderEpoch(topicPartition) match {
case Some(updatedLeaderIsrAndControllerEpoch) =>
try {
brokerRequestBatch.newBatch()
// 发送LeaderAndIsrRequest给partition的所有副本,包含adding/removing
// 新增的replica需要做成为follower的准备
brokerRequestBatch.addLeaderAndIsrRequestForBrokers(assignment.replicas, topicPartition,
updatedLeaderIsrAndControllerEpoch, assignment, isNew = false)
brokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
} catch {
case e: IllegalStateException =>
handleIllegalState(e)
}
}
}
AbstractControllerBrokerRequestBatch#addLeaderAndIsrRequestForBrokers:
LeaderAndIsrRequest包含assignment和leaderAndIsr信息。
def addLeaderAndIsrRequestForBrokers(brokerIds: Seq[Int],
topicPartition: TopicPartition,
leaderIsrAndControllerEpoch: LeaderIsrAndControllerEpoch,
replicaAssignment: ReplicaAssignment,
isNew: Boolean): Unit = {
// 循环ReplicaAssignment中全量副本111、222、333都发送LeaderAndIsr
brokerIds.filter(_ >= 0).foreach { brokerId =>
val result = leaderAndIsrRequestMap.getOrElseUpdate(brokerId, mutable.Map.empty)
val alreadyNew = result.get(topicPartition).exists(_.isNew)
val leaderAndIsr = leaderIsrAndControllerEpoch.leaderAndIsr
result.put(topicPartition, new LeaderAndIsrPartitionState()
.setTopicName(topicPartition.topic)
.setPartitionIndex(topicPartition.partition)
.setControllerEpoch(leaderIsrAndControllerEpoch.controllerEpoch)
// leaderAndIsr信息
.setLeader(leaderAndIsr.leader) // 111
.setLeaderEpoch(leaderAndIsr.leaderEpoch)
.setIsr(leaderAndIsr.isr.map(Integer.valueOf).asJava) // 111、333
.setZkVersion(leaderAndIsr.zkVersion)
// assignment信息
// 111、222、333
.setReplicas(replicaAssignment.replicas.map(Integer.valueOf).asJava)
// 222
.setAddingReplicas(replicaAssignment.addingReplicas.map(Integer.valueOf).asJava)
// 333
.setRemovingReplicas(replicaAssignment.removingReplicas.map(Integer.valueOf).asJava)
.setIsNew(isNew || alreadyNew))
}
addUpdateMetadataRequestForBrokers(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
}
ReplicaManager#makeFollowers:
3个broker收到LeaderAndIsrRequest,只有新增的222副本会有变化。
222发现自己成为follower,开始发送FetchRequest与leader111进行数据同步。
如果leader不在线,leaderAndIsr中的leader=-1,isr为最后一个下线的副本,如{"controller_epoch":64,"leader":-1,"version":1,"leader_epoch":6,"isr":[111]}。111上线后会触发相关分区的leader选举(KafkaController#onBrokerStartup),进入KafkaController#onPartitionReassignment的第四种触发场景,继续reassign,再次触发LeaderAndIsrRequest投递,此时follower发现111再开始数据同步。
private def makeFollowers(controllerId: Int,
controllerEpoch: Int,
partitionStates: Map[Partition, LeaderAndIsrPartitionState],
correlationId: Int,
responseMap: mutable.Map[TopicPartition, Errors],
highWatermarkCheckpoints: OffsetCheckpoints) : Set[Partition] = {
val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()
partitionStates.foreach { case (partition, partitionState) =>
val newLeaderBrokerId = partitionState.leader
metadataCache.getAliveBrokers.find(_.id == newLeaderBrokerId) match {
// leader存活,才允许执行后续动作
case Some(_) =>
// 更新内存状态
if (partition.makeFollower(partitionState, highWatermarkCheckpoints))
partitionsToMakeFollower += partition
else
// leader下线,follower不做动作
case None =>
partition.createLogIfNotExists(isNew = partitionState.isNew, isFutureReplica = false,
highWatermarkCheckpoints)
}
val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map { partition =>
val leader = metadataCache.getAliveBrokers.find(_.id == partition.leaderReplicaIdOpt.get).get
.brokerEndPoint(config.interBrokerListenerName)
val fetchOffset = partition.localLogOrException.highWatermark
partition.topicPartition -> InitialFetchState(leader, partition.getLeaderEpoch, fetchOffset)
}.toMap
// 开始发送FetchRequest从leader同步数据
replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)
}
partitionsToMakeFollower
}
ReplicaManager#fetchMessages:partition的leader接收FetchRequest,follower像消费者一样从leader同步数据。
数据复制流程,后续章节再分析。
def fetchMessages(timeout: Long,
replicaId: Int,
fetchMinBytes: Int,
fetchMaxBytes: Int,
hardMaxBytesLimit: Boolean,
fetchInfos: Seq[(TopicPartition, PartitionData)],
quota: ReplicaQuota,
responseCallback: Seq[(TopicPartition, FetchPartitionData)] => Unit,
isolationLevel: IsolationLevel,
clientMetadata: Option[ClientMetadata]): Unit = {
val isFromFollower = Request.isValidBrokerId(replicaId)
def readFromLog(): Seq[(TopicPartition, LogReadResult)] = {
val result = readFromLocalLog(
replicaId = replicaId,
fetchOnlyFromLeader = fetchOnlyFromLeader,
fetchIsolation = fetchIsolation,
fetchMaxBytes = fetchMaxBytes,
hardMaxBytesLimit = hardMaxBytesLimit,
readPartitionInfo = fetchInfos,
quota = quota,
clientMetadata = clientMetadata)
// 如果拉消息的人是follower,而不是普通消费者,可能触发ISR扩张逻辑
if (isFromFollower) updateFollowerFetchState(replicaId, result)
else result
}
// ...
}
Partition#maybeExpandIsr:根据案例,leader111判断topicA的p0分区的222副本追上自己,触发ISR扩张。
如何判断ISR扩张,后续章节再分析。
private def maybeExpandIsr(followerReplica: Replica, followerFetchTimeMs: Long): Unit = {
val needsIsrUpdate = inReadLock(leaderIsrUpdateLock) {
needsExpandIsr(followerReplica)
}
if (needsIsrUpdate) {
inWriteLock(leaderIsrUpdateLock) {
// check if this replica needs to be added to the ISR
if (needsExpandIsr(followerReplica)) {
val newInSyncReplicaIds = inSyncReplicaIds + followerReplica.brokerId
// update ISR in ZK and cache
expandIsr(newInSyncReplicaIds)
}
}
}
}
/brokers/topics/topicA/partitions/0/state如下,进入下一阶段。
{"controller_epoch":64,"leader":111,"version":1,"leader_epoch":6,"isr":[111,333,222]
2-6、reassign已完成
controller在reassign开始监听了/brokers/topics/topicA/partitions/0/state。
KafkaController#process:controller-event-thread单线程处理PartitionReassignmentIsrChange事件。
override def process(event: ControllerEvent): Unit = {
event match {
// ...
case PartitionReassignmentIsrChange(partition) =>
processPartitionReassignmentIsrChange(partition)
// ...
}
}
KafkaController#processPartitionReassignmentIsrChange:controller查询state节点数据,判断目标replicas都在isr列表里(案例中p0分区的222副本进入isr),二次进入reassign流程。
private def processPartitionReassignmentIsrChange(topicPartition: TopicPartition): Unit = {
// 确认自己是controller
if (!isActive) return
// partition正在执行reassign
if (controllerContext.partitionsBeingReassigned.contains(topicPartition)) {
// 获取当前内存中的assignment,为
// { "partitions":{"0":[111,222,333],"1":[333,222],"2":[333,111]},
// "adding_replicas":{"0":[222]},"removing_replicas":{"0":[333]}}
val reassignment = controllerContext.partitionFullReplicaAssignment(topicPartition)
// 查询state节点
// 如果目标replicas都在isr列表里,再次触发reassign流程
if (isReassignmentComplete(topicPartition, reassignment)) {
info(s"Target replicas ${reassignment.targetReplicas} have all caught up with the leader for " +
s"reassigning partition $topicPartition")
onPartitionReassignment(topicPartition, reassignment)
}
}
}
KafkaController#onPartitionReassignment:再次回到reassign主流程,此时走到else逻辑。
内存状态变更:【1】新增副本OnlineReplica;【2】assignment变更为终态,即案例中p0=222,111。
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
// ...
val addingReplicas = reassignment.addingReplicas // 222
val removingReplicas = reassignment.removingReplicas // 333
if (!isReassignmentComplete(topicPartition, reassignment)) {
// ... 目标副本未全部进入isr
} else {
// 到这里,说明reassignment中的目标副本集合,都进入了isr列表
// 1. 新增副本状态变更OnlineReplica
replicaStateMachine.handleStateChanges(addingReplicas.map(PartitionAndReplica(topicPartition, _)), OnlineReplica)
// 2. 内存更新assignment为最终assignment[222,111]
val completedReassignment = ReplicaAssignment(reassignment.targetReplicas)
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, completedReassignment)
// 3-1 partition->OnlinePartition 如果新分配下移除了老leader,需要重新选举
// 选举结果存储到zk的state节点,更新内存controllerContext,发送LeaderAndIsr
// 3-2 否则继续使用老的leader,更新leader epoch,发送LeaderAndIsr
moveReassignedPartitionLeaderIfRequired(topicPartition, completedReassignment)
// 4. 被移除的副本333下线
// 1)将replica从isr中移除,发送LeaderAndIsr
// 2)发送StopReplicaRequest给replica
stopRemovedReplicasOfReassignedPartition(topicPartition, removingReplicas)
// 5. ZK更新,完成最终分区状态变更,老分区不变,这个正在处理的分区的replica更新 -> [222,111]
updateReplicaAssignmentForPartition(topicPartition, completedReassignment)
// 6. 取消监听/brokers/topics/{topic}/partitions/{partition}/state
removePartitionFromReassigningPartitions(topicPartition, completedReassignment)
// 7. 发送MetadataRequest给所有存活brokers
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
}
}
2-6-1、尝试重新选leader
【3】KafkaController#moveReassignedPartitionLeaderIfRequired:
如果leader不在最终assignment中,(案例中topicA的p1和p2分区原来leader都是333,但是333被移除了,replicas变为111和222)需要重新选主;
反之(案例中topicA的p0分区,原来leader是111),leader不会变化,发送LeaderAndIsr(包含最终assignment)给最终的副本brokers集合。
private def moveReassignedPartitionLeaderIfRequired(topicPartition: TopicPartition,
newAssignment: ReplicaAssignment): Unit = {
val reassignedReplicas = newAssignment.replicas
val currentLeader = controllerContext.partitionLeadershipInfo(topicPartition).leaderAndIsr.leader
if (!reassignedReplicas.contains(currentLeader)) {
// case1 如果partition leader不在最终分配里
// 重新选举partition leader,isr列表中选取存活副本,发送LeaderAndIsrRequest
partitionStateMachine.handleStateChanges(Seq(topicPartition), OnlinePartition, Some(ReassignPartitionLeaderElectionStrategy))
} else if (controllerContext.isReplicaOnline(currentLeader, topicPartition)) {
// case2 【这保证了assignment即使replica无序也不会重新触发选主】
// leader在新分配里且存活
// 更新leader epoch,发送LeaderAndIsrRequest给所有目标副本
// 这些副本更新内存partition信息
updateLeaderEpochAndSendRequest(topicPartition, newAssignment)
} else {
// case3 leader在新分配里但死亡,同1
partitionStateMachine.handleStateChanges(Seq(topicPartition), OnlinePartition, Some(ReassignPartitionLeaderElectionStrategy))
}
}
与上一章topic创建选主流程一致:
1)选主;
2)更新LeaderAndIsr到/brokers/topics/{topic}/partitions/{partitionId}/state节点;
3)缓存到controllerContext;
4)发送LeaderAndIsrRequest给partition内的副本;
Election#leaderForReassign:唯一不同的是选主策略。
topic创建时选择存活副本中第一个作为初始leader。
本次在reassign中,从isr+目标存活副本中过滤出一个副本作为leader。
private def leaderForReassign(partition: TopicPartition,
leaderAndIsr: LeaderAndIsr, // from zk
controllerContext: ControllerContext):
ElectionResult = {
// 目标副本111和222
val targetReplicas = controllerContext.partitionFullReplicaAssignment(partition).targetReplicas
// 目标存活副本111和222
val liveReplicas = targetReplicas.filter(replica => controllerContext.isReplicaOnline(replica, partition))
// zk里的p1分区的状态 leader=333,isr=111和222和333
val isr = leaderAndIsr.isr
// 从isr+目标存活副本中过滤出一个副本作为leader
val leaderOpt = PartitionLeaderElectionAlgorithms.reassignPartitionLeaderElection(targetReplicas, isr, liveReplicas.toSet)
val newLeaderAndIsrOpt = leaderOpt.map(leader => leaderAndIsr.newLeader(leader))
ElectionResult(partition, newLeaderAndIsrOpt, targetReplicas)
}
def reassignPartitionLeaderElection(reassignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
reassignment.find(id => liveReplicas.contains(id) && isr.contains(id))
}
2-6-2、移除副本下线
【4】KafkaController#stopRemovedReplicasOfReassignedPartition:controller对变更下线replica状态变更
OnlineReplica→OfflineReplica→ReplicaDeletionStarted→ReplicaDeletionSuccessful→NonExistentReplica。
private def stopRemovedReplicasOfReassignedPartition(topicPartition: TopicPartition,
removedReplicas: Seq[Int]): Unit = {
val replicasToBeDeleted = removedReplicas.map(PartitionAndReplica(topicPartition, _))
// 将下线replica从isr中移除(zk和内存),并发送StopReplicaRequest(deletePartition=false)
// 向partition内其他成员发送LeaderAndIsr,因为isr变更了
replicaStateMachine.handleStateChanges(replicasToBeDeleted, OfflineReplica)
// 发送StopReplicaRequest(deletePartition=true)给下线replica
replicaStateMachine.handleStateChanges(replicasToBeDeleted, ReplicaDeletionStarted)
replicaStateMachine.handleStateChanges(replicasToBeDeleted, ReplicaDeletionSuccessful)
// 内存移除下线replica状态
replicaStateMachine.handleStateChanges(replicasToBeDeleted, NonExistentReplica)
}
ZkReplicaStateMachine#doHandleStateChanges:OfflineReplica状态。
private def doHandleStateChanges(replicaId: Int, replicas: Seq[PartitionAndReplica], targetState: ReplicaState): Unit = {
targetState match {
case OfflineReplica =>
// 缓存StopReplicaRequest,deletePartition=false
validReplicas.foreach { replica =>
controllerBrokerRequestBatch.addStopReplicaRequestForBrokers(Seq(replicaId), replica.topicPartition, deletePartition = false)
}
// 有leader的分区,无leader的分区
val (replicasWithLeadershipInfo, replicasWithoutLeadershipInfo) = validReplicas.partition { replica =>
controllerContext.partitionLeadershipInfo.contains(replica.topicPartition)
}
// 对于有leader的partition,将副本从isr中移除
val updatedLeaderIsrAndControllerEpochs = removeReplicasFromIsr(replicaId, replicasWithLeadershipInfo.map(_.topicPartition))
updatedLeaderIsrAndControllerEpochs.foreach { case (partition, leaderIsrAndControllerEpoch) =>
if (!controllerContext.isTopicQueuedUpForDeletion(partition.topic)) {
// 发送LeaderAndIsr给partition内其余副本
val recipients = controllerContext.partitionReplicaAssignment(partition).filterNot(_ == replicaId)
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipients,
partition,
leaderIsrAndControllerEpoch,
controllerContext.partitionFullReplicaAssignment(partition), isNew = false)
}
val replica = PartitionAndReplica(partition, replicaId)
val currentState = controllerContext.replicaState(replica)
// replica状态OfflineReplica
controllerContext.putReplicaState(replica, OfflineReplica)
}
}
}
ZkReplicaStateMachine#doRemoveReplicasFromIsr:
目前partition内的副本都处于运行状态(无论是刚新增的还是需要移除的),随时都有可能发生ISR扩张或收缩。如果要将replica从isr中移除,需要根据zk版本号做乐观更新。
private def doRemoveReplicasFromIsr(
replicaId: Int,
partitions: Seq[TopicPartition]
): (Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]], Seq[TopicPartition]) = {
// 从/brokers/topics/topicA/partitions/0/state查一下当前leaderAndIsr
val (leaderAndIsrs, partitionsWithNoLeaderAndIsrInZk) = getTopicPartitionStatesFromZk(partitions)
val (leaderAndIsrsWithReplica, leaderAndIsrsWithoutReplica) = leaderAndIsrs.partition { case (_, result) =>
result.map { leaderAndIsr =>
leaderAndIsr.isr.contains(replicaId)
}.getOrElse(false)
}
// 如果replica还在partition的isr内,调整leader和isr
val adjustedLeaderAndIsrs: Map[TopicPartition, LeaderAndIsr] = leaderAndIsrsWithReplica.flatMap {
case (partition, result) =>
result.toOption.map { leaderAndIsr =>
// 如果被移除的replica是leader,更新新leader为-1,否则不变
val newLeader = if (replicaId == leaderAndIsr.leader) LeaderAndIsr.NoLeader else leaderAndIsr.leader
// 如果isr大小为1,不变;否则,将replica从isr中移除
val adjustedIsr = if (leaderAndIsr.isr.size == 1) leaderAndIsr.isr else leaderAndIsr.isr.filter(_ != replicaId)
partition -> leaderAndIsr.newLeaderAndIsr(newLeader, adjustedIsr)
}
}
// 通过zk的版本号,乐观更新znode,/brokers/topics/topicA/partitions/0/state,如果乐观更新失败会重试
val UpdateLeaderAndIsrResult(finishedPartitions, updatesToRetry) = zkClient.updateLeaderAndIsr(
adjustedLeaderAndIsrs, controllerContext.epoch, controllerContext.epochZkVersion)
// ...
val leaderIsrAndControllerEpochs: Map[TopicPartition, Either[Exception, LeaderIsrAndControllerEpoch]] =
(leaderAndIsrsWithoutReplica ++ finishedPartitions).map { case (partition, result) =>
(partition, result.map { leaderAndIsr =>
// 更新内存leaderAndIsr
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
controllerContext.partitionLeadershipInfo.put(partition, leaderIsrAndControllerEpoch)
leaderIsrAndControllerEpoch
})
}
}
至此/brokers/topics/topicA/partitions/0/state如下,333从isr中被移除。
{"controller_epoch":64,"leader":111,"isr":[111,222],...}
ReplicaManager#stopReplicas:被下线副本对应broker先后收到两次StopReplicaRequest。
第一次,deletePartition=false,停止向leader发送FetchRequest同步数据。
def stopReplicas(correlationId: Int,
controllerId: Int,
controllerEpoch: Int,
brokerEpoch: Long,
partitionStates: Map[TopicPartition, StopReplicaPartitionState]
): (mutable.Map[TopicPartition, Errors], Errors) = {
replicaStateChangeLock synchronized {
// ... 校验controller指令合法性,controller任期和自身broker epoch
// 停止的partition
val partitions = stoppedPartitions.keySet
// 第一次,停止fetcher从leader拉数据
replicaFetcherManager.removeFetcherForPartitions(partitions)
replicaAlterLogDirsManager.removeFetcherForPartitions(partitions)
stoppedPartitions.foreach { case (topicPartition, partitionState) =>
val deletePartition = partitionState.deletePartition
// 第二次deletePartition=true,移除partition(内存和磁盘)
stopReplica(topicPartition, deletePartition)
}
// ...
}
}
ReplicaManager#stopReplica:第二次deletePartition=true,内存和磁盘删除partition。
def stopReplica(topicPartition: TopicPartition, deletePartition: Boolean): Unit = {
if (deletePartition) {
getPartition(topicPartition) match {
case hostedPartition @ HostedPartition.Online(removedPartition) =>
// 内存移除partition
if (allPartitions.remove(topicPartition, hostedPartition)) {
maybeRemoveTopicMetrics(topicPartition.topic)
removedPartition.delete()
}
case _ =>
}
// 磁盘删除partition
if (logManager.getLog(topicPartition).isDefined)
logManager.asyncDelete(topicPartition)
if (logManager.getLog(topicPartition, isFuture = true).isDefined)
logManager.asyncDelete(topicPartition, isFuture = true)
}
// ...
}
2-6-3、持久化最终Assignment
KafkaController#onPartitionReassignment:
【5】最终assignment更新为终态;
【6】取消监听partition状态;
【7】发送MetadataRequest给所有存活brokers,brokers更新本地缓存MetadataCache;
private def onPartitionReassignment(topicPartition: TopicPartition, reassignment: ReplicaAssignment): Unit = {
// ...
val addingReplicas = reassignment.addingReplicas // 222
val removingReplicas = reassignment.removingReplicas // 333
if (!isReassignmentComplete(topicPartition, reassignment)) {
// ... 目标副本未全部进入isr
} else {
// 到这里,说明reassignment中的目标副本集合,都进入了isr列表
// ...
// 5. ZK更新,完成最终分区状态变更,老分区不变,这个正在处理的分区的replica更新 -> [222,111]
updateReplicaAssignmentForPartition(topicPartition, completedReassignment)
// 6. 取消监听/brokers/topics/{topic}/partitions/{partition}/state
// 将partition从controllerContext.partitionsBeingReassigned移除
removePartitionFromReassigningPartitions(topicPartition, completedReassignment)
// 7. 发送MetadataRequest给所有存活brokers
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
}
}
至此,znode=/brokers/topics/topicA的状态,可能现在p0分区已经完成了,其他分区还没完成,比如新增replica还在从leader同步数据。
{
"partitions":{"0":[111,222],"1":[???],"2":[???]},
"adding_replicas":{"1":[???],"2":[???]},
"removing_replicas":{"1":[???],"2":[???]}
}
znode=/brokers/topics/topicA/partitions/0/state的状态如下。
{"controller_epoch":64,"leader":111,"version":1,"leader_epoch":6,"isr":[111,222]}
2-7、验证reassign完成
verify指令是如何判断reassign是否完成的。
./kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \
--reassignment-json-file reassignment.json --verify
ReassignPartitionsCommand#verifyPartitionAssignments:客户端侧代码入口。
def verifyPartitionAssignments(adminClient: Admin,
targets: Seq[(TopicPartition, Seq[Int])])
: (Map[TopicPartition, PartitionReassignmentState], Boolean) = {
// 查询reassign情况,partStates=PartitionReassignmentState
val (partStates, partsOngoing) = findPartitionReassignmentStates(adminClient, targets)
// 打印输出
println(partitionReassignmentStatesToString(partStates))
(partStates, partsOngoing)
}
PartitionReassignmentState代表一个partition的reassign进度:
1)currentReplicas:broker侧实际的replicas;
2)targetReplicas:客户端期望的replicas;
3)done:reassign是否完成;
sealed case class PartitionReassignmentState(currentReplicas: Seq[Int],
targetReplicas: Seq[Int],
done: Boolean) {}
ReassignPartitionsCommand#partitionReassignmentStatesToString:
根据PartitionReassignmentState可输出3种不同的结果。
def partitionReassignmentStatesToString(states: Map[TopicPartition, PartitionReassignmentState])
: String = {
val bld = new mutable.ArrayBuffer[String]()
bld.append("Status of partition reassignment:")
states.keySet.toBuffer.sortWith(compareTopicPartitions).foreach {
topicPartition => {
val state = states(topicPartition)
if (state.done) {
// case1. controller的controllerContext.partitionsBeingReassigned不包含这个partition
if (state.currentReplicas.equals(state.targetReplicas)) {
// 某个broker的metadata里,且目标replicas与缓存replicas相等
bld.append("Reassignment of partition %s is complete.".
format(topicPartition.toString))
} else {
// 某个broker的metadata里,但目标replicas与缓存replicas不相等
bld.append(s"There is no active reassignment of partition ${topicPartition}, " +
s"but replica set is ${state.currentReplicas.mkString(",")} rather than " +
s"${state.targetReplicas.mkString(",")}.")
}
} else {
// case2. controller的controllerContext.partitionsBeingReassigned包含这个partition
bld.append("Reassignment of partition %s is still in progress.".format(topicPartition))
}
}
}
bld.mkString(System.lineSeparator())
}
ReassignPartitionsCommand#findPartitionReassignmentStates:PartitionReassignmentState构造逻辑如下。
Step1,向controller发送ListPartitionReassignmentsRequest,查询正在reassign的分区,这些分区被标记done=false;
Step2,未从controller查询到的分区,向任一Broker发送MetadataRequest,获取broker内存MetadataCache中的分区信息,这些分区被标记done=true;
def findPartitionReassignmentStates(adminClient: Admin,
targetReassignments: Seq[(TopicPartition, Seq[Int])])
: (Map[TopicPartition, PartitionReassignmentState], Boolean) = {
// Step1. 调用controller,查询当前正在reassign的分区的assignment
val currentReassignments = adminClient.
listPartitionReassignments.reassignments.get().asScala
val (foundReassignments, notFoundReassignments) = targetReassignments.partition {
case (part, _) => currentReassignments.contains(part)
}
// controller返回正在reassign的partition的情况,这些partition未完成reassign
val foundResults: Seq[(TopicPartition, PartitionReassignmentState)] = foundReassignments.map {
case (part, targetReplicas) => (part,
new PartitionReassignmentState(
currentReassignments.get(part).get.replicas.
asScala.map(i => i.asInstanceOf[Int]),
targetReplicas,
false))
}
// Step2. 对于controller未返回的partition,通过topic查询Metadata
val topicNamesToLookUp = new mutable.HashSet[String]()
notFoundReassignments.foreach {
case (part, _) =>
if (!currentReassignments.contains(part))
topicNamesToLookUp.add(part.topic)
}
val topicDescriptions = adminClient.
describeTopics(topicNamesToLookUp.asJava).values().asScala
val notFoundResults: Seq[(TopicPartition, PartitionReassignmentState)] = notFoundReassignments.map {
case (part, targetReplicas) =>
currentReassignments.get(part) match {
// Step3-1. controller返回该分区正在reassign
case Some(reassignment) => (part,
PartitionReassignmentState(
reassignment.replicas.asScala.map(_.asInstanceOf[Int]),
targetReplicas,
false)) // done=false
// Step3-2. controller未返回该分区,根据Metadata中的topic-partition的replicas返回
case None =>
(part, topicDescriptionFutureToState(part.partition,
topicDescriptions(part.topic), targetReplicas))
}
}
val allResults = foundResults ++ notFoundResults
(allResults.toMap, currentReassignments.nonEmpty)
}
private def topicDescriptionFutureToState(partition: Int,
future: KafkaFuture[TopicDescription],
targetReplicas: Seq[Int])
: PartitionReassignmentState = {
val topicDescription = future.get()
PartitionReassignmentState(
// Metadata中的replicas
topicDescription.partitions.get(partition).replicas.asScala.map(_.id),
targetReplicas,
// done=true
true)
}
问题点在于controller如何处理ListPartitionReassignmentsRequest。
KafkaApis#handleListPartitionReassignmentsRequest:controller将ListPartitionReassignmentsRequest读请求也放入controller-event-thread单线程处理,所以一定能读到controllerContext里的变更。
def handleListPartitionReassignmentsRequest(request: RequestChannel.Request): Unit = {
val listPartitionReassignmentsRequest = request.body[ListPartitionReassignmentsRequest]
// 响应客户端
def sendResponseCallback(result: Either[Map[TopicPartition, ReplicaAssignment], ApiError]): Unit = {
// ...
}
// 由于客户端没指定partition,这里partitionsOpt是个None
val partitionsOpt = listPartitionReassignmentsRequest.data.topics match {
case topics: Any =>
Some(topics.iterator().asScala.flatMap { topic =>
topic.partitionIndexes.iterator().asScala
.map { tp => new TopicPartition(topic.name(), tp) }
}.toSet)
case _ => None
}
// 单线程
controller.listPartitionReassignments(partitionsOpt, sendResponseCallback)
}
// KafkaController#listPartitionReassignments
def listPartitionReassignments(partitions: Option[Set[TopicPartition]],
callback: ListReassignmentsCallback): Unit = {
eventManager.put(ListPartitionReassignments(partitions, callback))
}
KafkaController#processListPartitionReassignments:
1)从controllerContext.partitionsBeingReassigned中获取正在reassign的所有partition;
2)根据partition再查controllerContext.partitionAssignments中对应的assignment;
3)仅返回正在reassign(包含adding和removingReplicas)的partition和其assignment;
private def processListPartitionReassignments(partitionsOpt: Option[Set[TopicPartition]], callback: ListReassignmentsCallback): Unit = {
if (!isActive) { // 判断自己仍然是controller
callback(Right(new ApiError(Errors.NOT_CONTROLLER)))
} else {
val results: mutable.Map[TopicPartition, ReplicaAssignment] = mutable.Map.empty
val partitionsToList = partitionsOpt match {
case Some(partitions) => partitions
// 走这里,没传入partition,查询正在reassign的所有partition
case None => controllerContext.partitionsBeingReassigned
}
partitionsToList.foreach { tp =>
val assignment = controllerContext.partitionFullReplicaAssignment(tp)
if (assignment.isBeingReassigned) {
// 仅返回存在addingReplicas和removingReplicas的partition
results += tp -> assignment
}
}
callback(Left(results))
}
}
综上:
1)partition标记done=false,是因为ListPartitionReassignmentsRequest返回的partition仍然还有adding和removing的replicas,即处于2-5状态,有目标replica尚未进入isr;
2)partition标记done=true,从任一broker的metadata缓存中获取partition的replicas有两种情况:
2-1)处于2-6状态,目标replicas完全进入isr,但还未更新zk的assignment为目标replicas(可能还没选leader,还没移除removing的副本,只完成了2-6的1和2),此时各broker的MetadataCache还没更新,目标replicas ≠ 当前replicas;
2-2)处于最终状态,zk中的assignment变为目标replicas,brokers都已经通过MetadataRequest更新了自身MetadataCache,目标replicas=当前replicas,此时能输出Reassignment of partition topicA is complete;
总结
分区变更操作涉及两个重要的znode。
/brokers/topics/{topic}:存储了topic分区的分配情况,称为assignment。
其中partitions存储了每个分区的副本replicas,每个replica表现为brokerId。
{"version":2,"partitions":{"0":[111,222],"1":[222,333],"2":[333,111]},"adding_replicas":{},"removing_replicas":{}}
/brokers/topics/{topic}/partitions/{partitionId}/state:存储了分区的状态,包含当前分区的leader和isr列表,称为LeaderAndIsr。
{"controller_epoch":70,"leader":111,"version":1,"leader_epoch":3,"isr":[111,222]}
分区新增
Step1:client通过MetadataRequest发现controller节点
Step2:
1)client,发送CreatePartitionRequest给controller,其中count为期望partition数量
2)controller,查询/brokers/topics/{topic},发现分区数量小于client期望数量,为新增分区分配replicas,更新/brokers/topics/{topic},提交延迟任务用于处理超时响应client
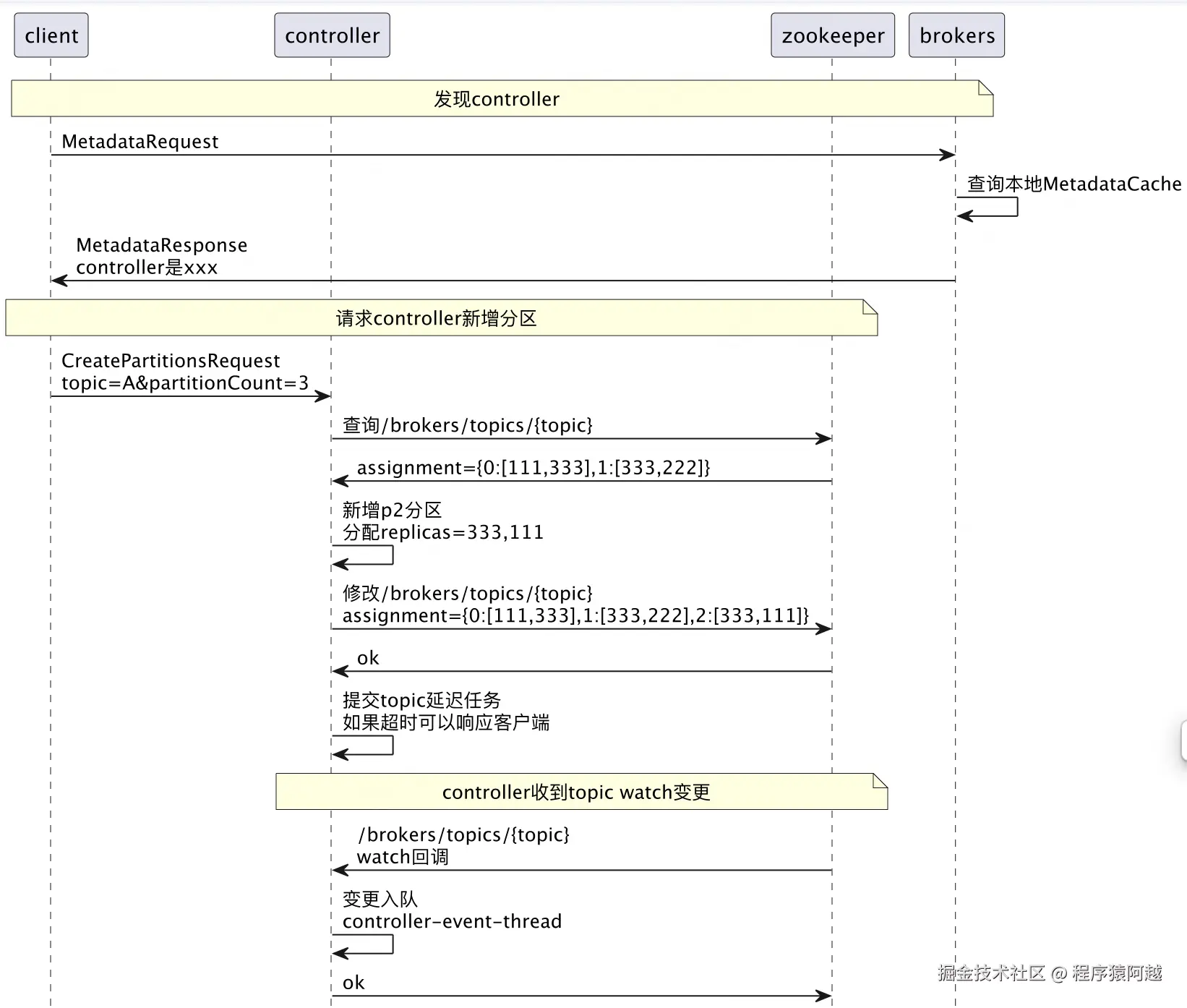
Step3,controller收到topic watch回调,处理topic变更
1)查询/brokers/topics/{topic},发现新增分区,更新到controllerContext;
2)为新增分区初始化LeaderAndIsr,更新到/brokers/topics/{topic}/partitions/{id}/state和controllerContext;
3)发送LeaderAndIsrRequest给isr中的replica,这些replica成为leader或follower,开始运行;
4)对于变更分区,发送UpdateMetadataRequest给所有存活brokers,brokers更新MetadataCache;
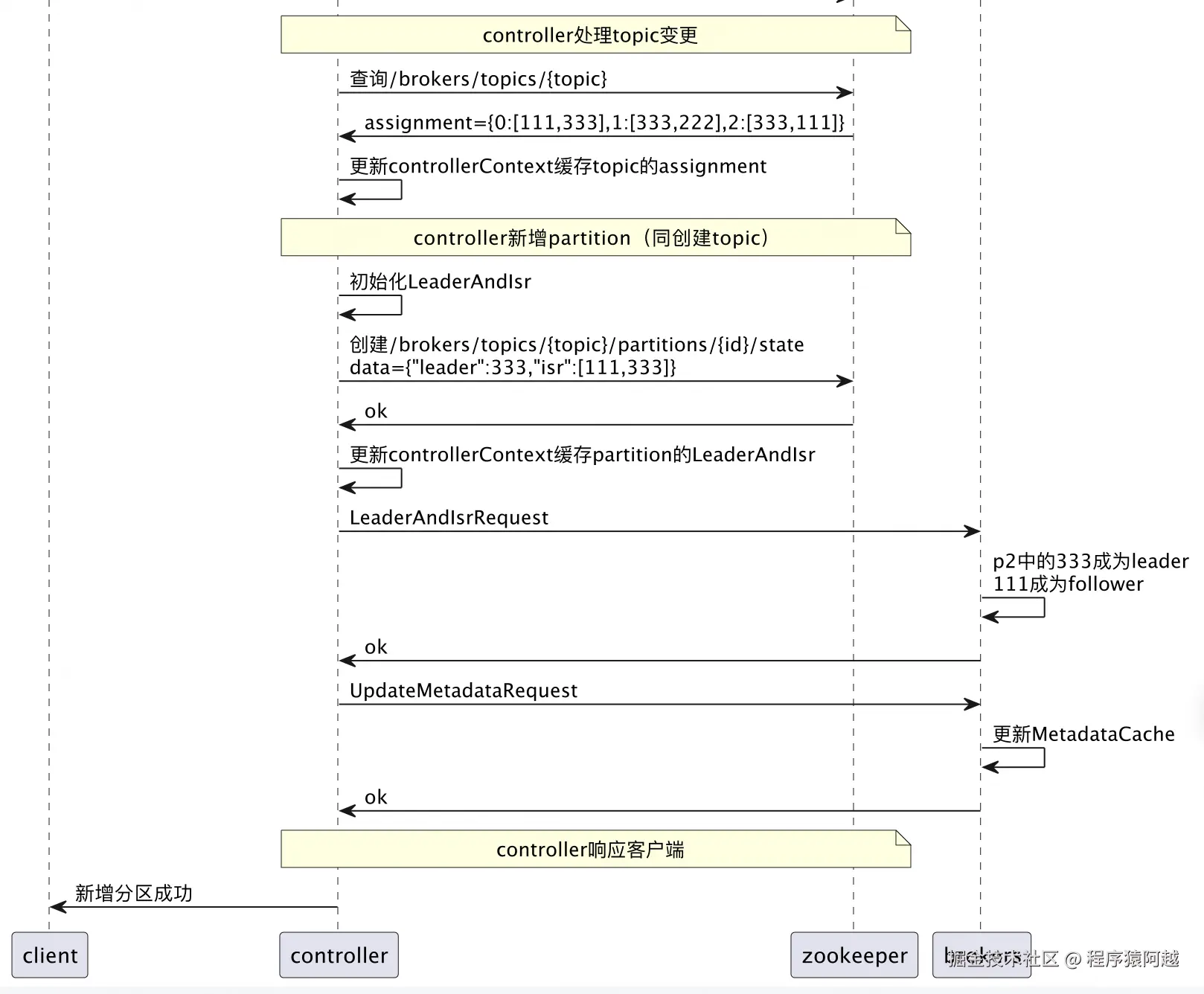
Step4,controller同样会收到UpdateMetadataRequest,除了更新MetadataCache以外,发现UpdateMetadataRequest中的topic分区存在挂起的新增分区请求,响应客户端新增分区成功。
分区重分配
和案例保持一致,对于topicA的p0分区:
reassign前,replicas=b1(id=111)和b3(id=333),leader=b1,isr=b1和b3;
reassign后,replicas=b1(id=111)和b2(id=222),leader=b1,isr=b1和b2。
阶段一:assignment变为中间态
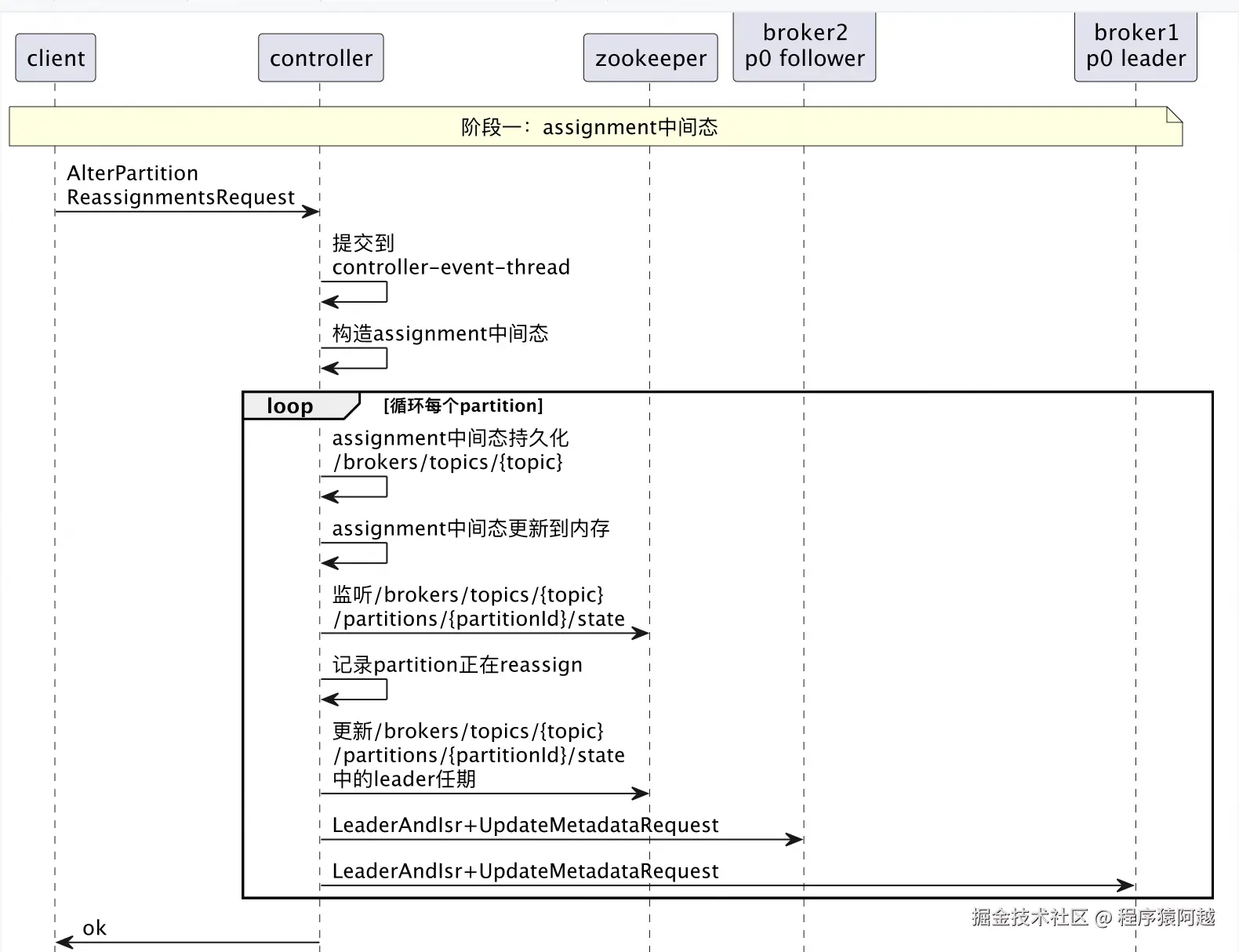
assignment正常情况下只有partitions。
{"partitions":{"0":[111,333],"1":[333,222],"2":[333,111]},"adding_replicas":{},"removing_replicas":{}}
在reassign过程中,assignment存在中间态。
比如p0分区,partitions=(当前副本+目标副本)去重=111,222,333,adding_replicas=新增副本=222,removing_replicas=移除副本=333;
{"partitions":{"0":[111,333,222],"1":[333,222],"2":[333,111]},"adding_replicas":{"0":[222]},"removing_replicas":{"0":[333]}}
1)客户端,提交AlterPartitionReassignmentsRequest给controller,包含多个分区的assignment,比如案例中topicA的p0分区的replicas改为111和222;
2)controller,将请求放入controller-event-thread单线程循环每个partition处理;
3)controller,从controllerContext拿到内存中的assignment,与请求的assignment做对比,构造assignment中间态。
4)controller,持久化assignment中间态,因为是循环partition处理,所以这里可能只改了一个p0;
5)controller,watch /brokers/topics/{topic}/partitions/{id}/state;
6)controller,controllerContext记录partition正在reassign,client来通过verify回查reassign状态时能给予回复;
7)controller,更新LeaderAndIsr的leader任期,向分区中所有副本发送LeaderAndIsr(包含分区assignment和leaderAndIsr),向所有存活brokers发送UpdateMetadataRequest;
8)controller,响应客户端ok,但是此时reassign并未完成,需要客户端自行通过verify请求验证reassign进度;
阶段二:新上线副本与leader同步数据
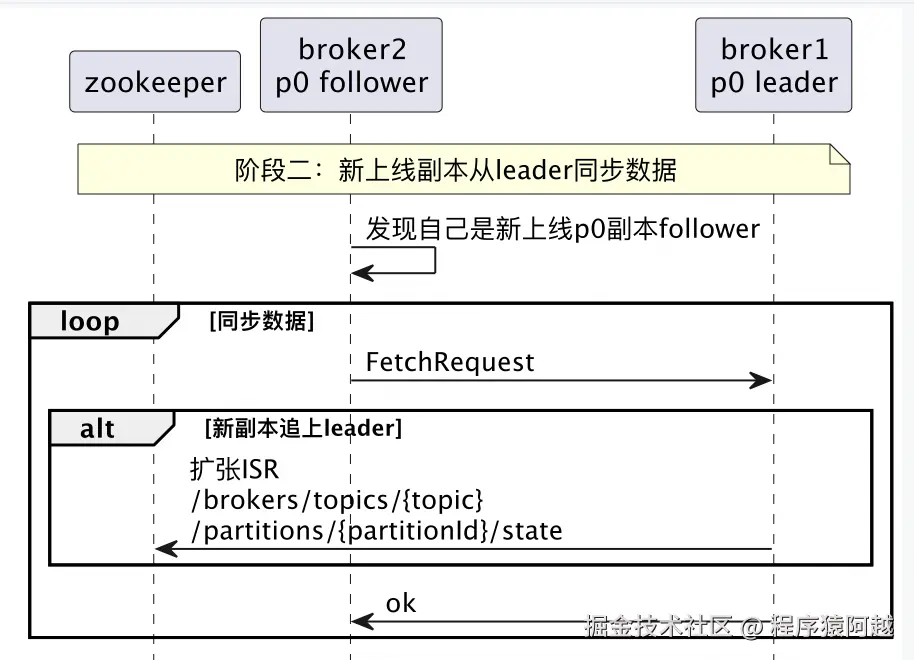
Step1,案例中broker222通过controller下发的LeaderAndIsrRequest,得知自己是topicA的p0分区的新增follower,开始从leader(broker111)同步数据;
Step2,在follower拉数据的过程中,leader判断follower追上自己的日志进度,扩张ISR,更新/brokers/topics/{topic}/partitions/{id}/state;
{"leader":111,"isr":[111,222,333]}
阶段三:assignment变为终态
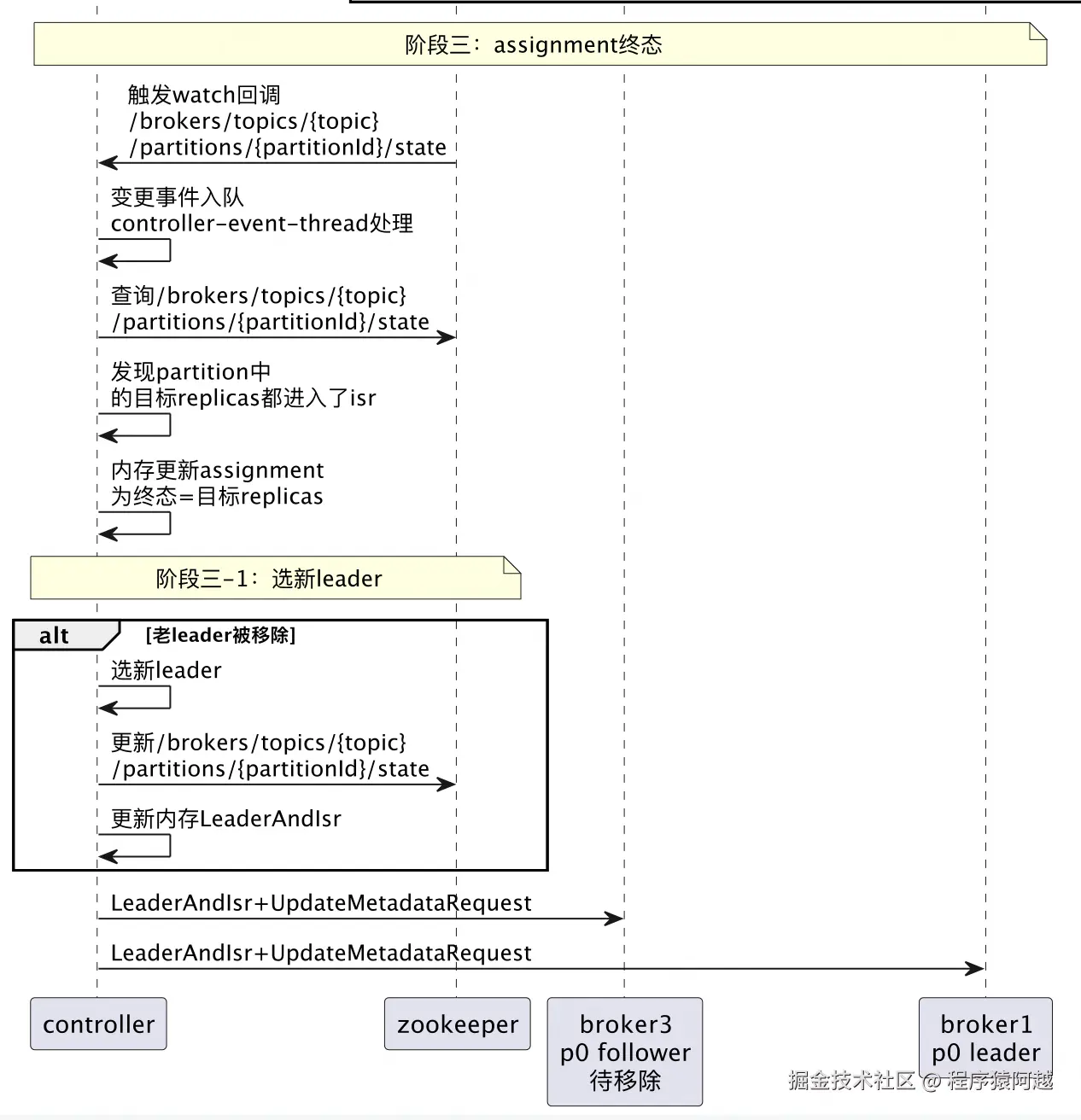
由于阶段一controller watch了/brokers/topics/{topic}/partitions/{id}/state,所以感知到分区ISR变更;又判断出这个partition正在执行reassign且目标副本都已经进入ISR,可以进行reassign终态变更逻辑。
对于该分区,如果老leader不在最终的目标副本集合中,需要选举新leader。选举方式是从isr中选择一个存活的broker,将选举后的LeaderAndIsr更新到/brokers/topics/{topic}/partitions/{id}/state和内存。(如果选不出来,即isr中没有存活broker,等broker上线再次触发现在的流程)
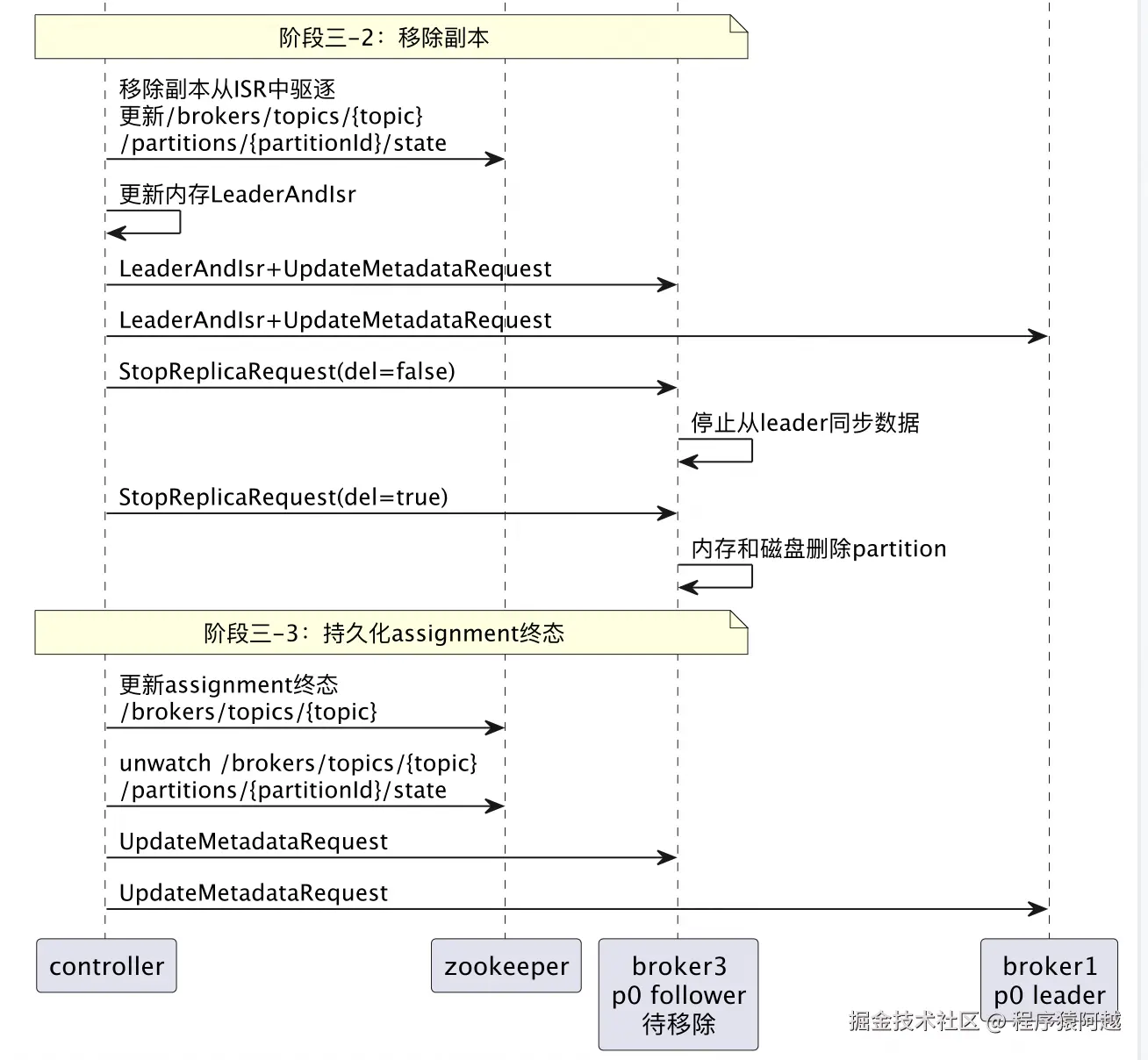
在新副本上线且leader选举完成的情况下,可以将期望移除的副本下线了,案例中是333。
controller将期望移除的副本从isr列表中删除,发送StopReplicaRequest给移除的副本,该副本停止与leader同步数据,并从内存和磁盘上删除分区。
/brokers/topics/{topic}/partitions/{id}/state:
{"leader":111,"isr":[111,222]}
最终controller更新assignment为终态,发送UpdateMetadataRequest给所有存活brokers。
/brokers/topics/{topic},p0分区完成reassign,从111和333变为111和222:
{"partitions":{"0":[111,222],"1":[?,?],"2":[?,?]},"adding_replicas":{"1":[???],"2":[???]},"removing_replicas":{"1":[???],"2":[???]}}

















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









