




今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。
我是一名后端开发爱好者,工作日常接触到最多的就是Java语言啦,所以我都尽量抽业余时间把自己所学到所会的,通过文章的形式进行输出,希望以这种方式帮助到更多的初学者或者想入门的小伙伴们,同时也能对自己的技术进行沉淀,加以复盘,查缺补漏。
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦。三连即是对作者我写作道路上最好的鼓励与支持!
如下是Java集合体系架构图,近期几期内容都是围绕该体系进行知识讲解,以便于同学们学习Java集合篇知识能够系统化而不零散。
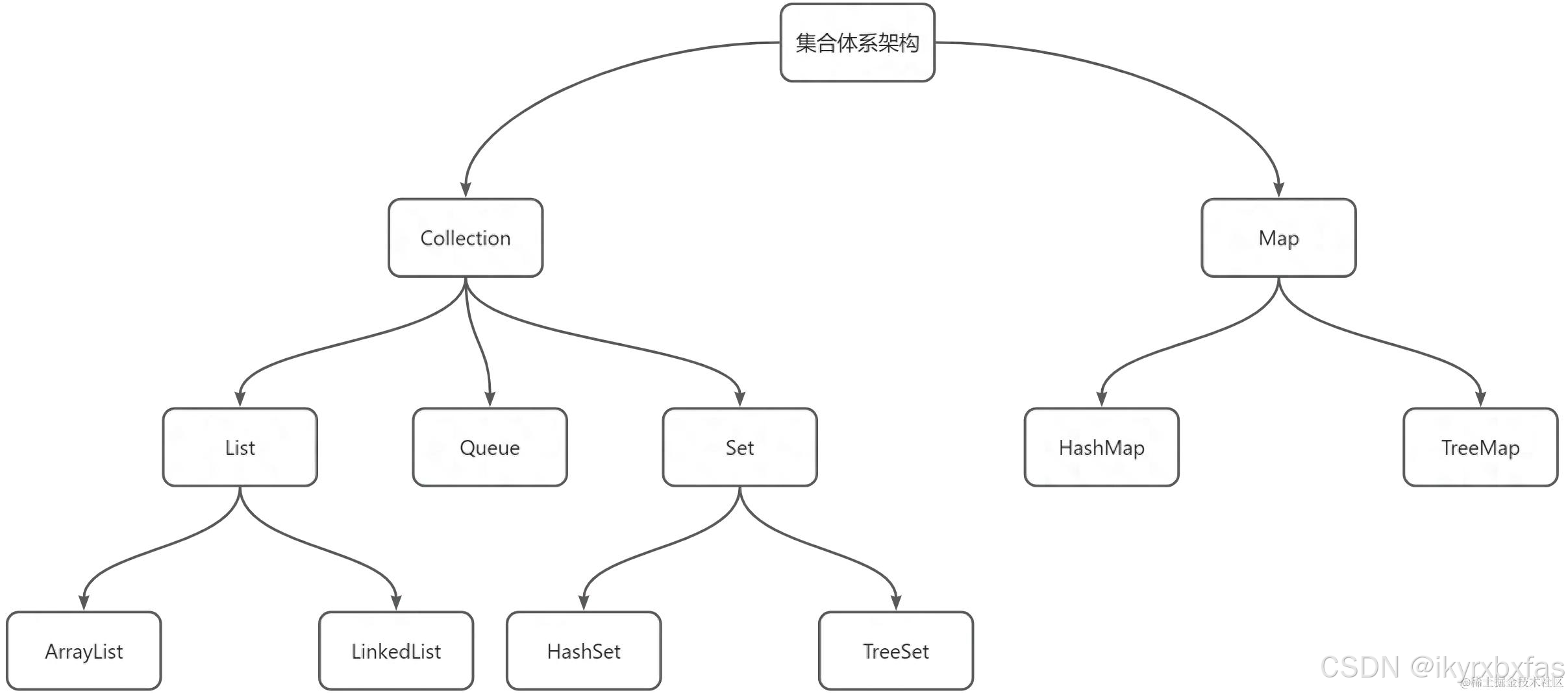
前言
在Java中,HashMap是一种重要的数据结构,也是我们经常使用的一种存储数据的容器。但是,你是否了解HashMap的具体实现?在使用HashMap时,你是否遇到过问题或者疑惑?在本文中,我们将通过源代码解析、应用场景案例、优缺点分析等方面,深入了解HashMap这个精妙的数据结构。
摘要
本文将从以下几个方面对Java中的HashMap进行分析:
- 源代码解析:对HashMap的源代码进行解析,了解HashMap的具体实现;
- 应用场景案例:通过具体场景案例,让读者了解在实际开发中如何灵活运用HashMap;
- 优缺点分析:对HashMap的优缺点进行分析,帮助读者更好地掌握HashMap的适用范围;
- 类代码方法介绍:对HashMap中各个方法的使用方法和注意事项进行详细介绍;
- 测试用例:提供相关测试用例,帮助读者更好地理解HashMap的应用。
HashMap
简介
HashMap是一种常见的键值对存储容器,其内部采用散列表实现,可以快速地查找键对应的值。具体来说,HashMap内部维护了一个Entry数组,每个Entry包含了一个键值对。HashMap使用哈希算法将键值对映射到数组中的位置,从而实现快速查找。
在Java中,HashMap继承自AbstractMap类,实现了Map接口,提供了一系列的方法用于操作键值对。
源代码解析
为了更好地理解HashMap的实现,我们将对其源代码进行解析。
数据结构
HashMap内部维护了一个Entry数组,每个Entry包含了一个键值对,定义如下:
java复制代码
static class Entry implements Map.Entry { final K key; V value; Entry next; final int hash; // ... }
其中,key表示键,value表示值,next表示下一个节点,hash表示键的哈希值。
插入操作
HashMap中插入一个键值对的操作可以通过以下代码实现:
java复制代码
public V put(K key, V value) { if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
其中,inflateTable用于初始化Entry数组,如果Entry数组未被初始化,则调用inflateTable方法进行初始化。putForNullKey用于处理键为null的情况。hash方法用于计算键的哈希值。indexFor方法用于将哈希值映射到Entry数组的位置。for循环用于查找键是否已经存在于Entry数组中。如果键已经存在,则更新值;否则,添加新的Entry。
查找操作
HashMap中查找某个键的值的操作可以通过以下代码实现:
java复制代码
public V get(Object key) { if (key =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









