







 本文讲述了在遇到服务响应慢、Mysql连接获取延迟的问题时,经过现场排查发现是由JVM的G1垃圾收集器的Young GC导致。深入分析后,发现是由于XStream频繁创建CompositeClassLoader造成YGC根扫描时间过长。通过优化XStream的使用,减少CompositeClassLoader的创建,成功减少了YGC时间,解决了服务卡顿问题。
本文讲述了在遇到服务响应慢、Mysql连接获取延迟的问题时,经过现场排查发现是由JVM的G1垃圾收集器的Young GC导致。深入分析后,发现是由于XStream频繁创建CompositeClassLoader造成YGC根扫描时间过长。通过优化XStream的使用,减少CompositeClassLoader的创建,成功减少了YGC时间,解决了服务卡顿问题。
1.现象
在某个阳光明媚的中午(也有一说是下午),王童鞋急冲冲的跑过来,反馈了一个问题,就是每次点下页面的某个查询按钮,总是固定的等待很久的时间服务器没相应,而且其他功能还伴随间歇性的有卡顿现象。他反馈说,有可能是Mysql的问题导致的。并且还把监控的截图发给笔者看了下:
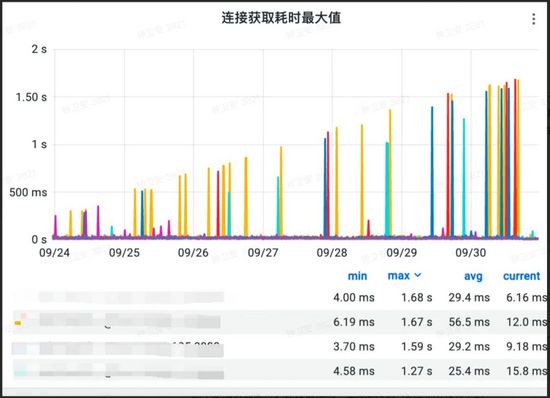
当然,这里显示的是Mysql的获取连接的时间,一直在递增,到了30号,基本上一次需要快2秒钟了。
OK,于是第一时间去阿里云RDS上面查看了数据库使用情况。
-
服务器支持的连接数情况:使用率才用10%不到
-
这个是数据库的机器指标,基本指标都很平稳,值都不是很高
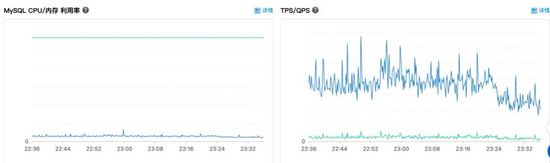
全部指标翻了一遍,没发现什么问题,并且看起来数据库都没啥压力。看来这个有可能不是数据库问题, 这个Mysql获取连接慢,也许是现象,而不是原因。
2.现场排查
2.1 寻找线索
话说回来,每次排查线上问题的时候,都像破案一样,一方面需要保留现场痕迹,另一方面也需要寻找其他的各种蛛丝马迹。所以这里一边让王童鞋把JVM的堆栈等信息给dump出来(当然,为了不影响线上环境使用,数据dump出来之后,王童鞋也重启了机器),笔者一边继续翻日志&监控。
当查看了JVM信息之后,元凶的尾巴被揪出来了一些:
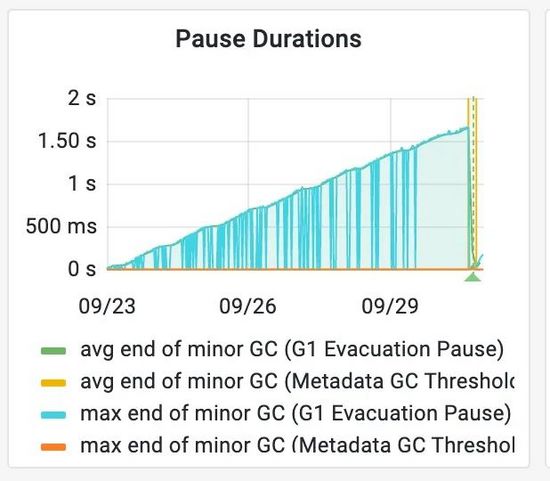
Pause Durations表示的是暂停时间,也就是JVM里面的STW(Stop The World)时间。图表里面avg/max end of minor GC (G1 Evacuation Pause)这个代表的是G1里面的young-gc。此刻, 我们知道G1里面的YGC有问题,但是还不够,因为我们需要知道具体问题点在哪呢?又什么原因导致的呢?
2.2 G1的young-gc简介
2.2.1 简介
作为CMS替代品的G1,一直吸引着众多Java开发者的目光。G1的目标是在满足期望的停顿时间的同时保存高吞吐量,适用于多核、大内存的系统。
在分配内存的时候,如果剩余的空间不能满足要分配的对象的时候,就会优先触发新生代回收,即young-gc(YGC)。G1中的YGC触发时,会一次性回收全部的新生代内存以及空的大对象区(前提是分区没有RSet引用)。目前比较新的垃圾收集器例如ZGC、Shenandoah都被称之为低延迟垃圾收集器,其目标是在任意内存下,保证停顿时间都保持在十毫秒以内。可见低延迟在垃圾收集器中的重要性。但是在G1中的YGC,它全部过程都是处于STW的,也就是说YGC的过程中,服务器是处于停顿状态中的。这也就解释了为什么Mysql获取连接超时他其实是现象而不是原因,因为不单单是Mysql获取连接, 在YGC的时候,除了 GC 线程之外整个服务器的所有Mutator线程( Java 应用线程)都停止了 ,服务卡顿便如此由来。
现在,通过监控知道了服务器慢,是因为YGC导致的,但是YGC的过程比较多,具体慢在哪,还是不得而知,问题如果想解决,还需要继续排查。
2.2.2 YGC过程图解
首先,在这里画一张图讲下G1的YGC的过程:
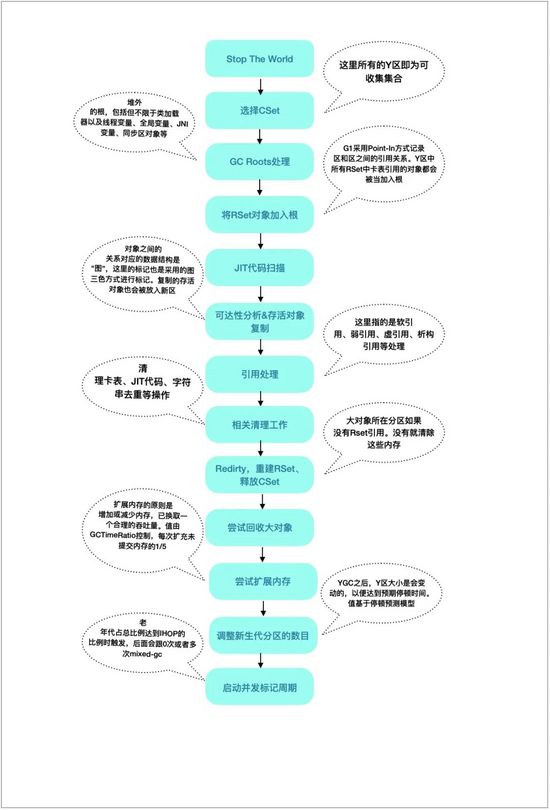
通过上面的图例也看到了,一次YGC过程还是有挺多操作的,那么YGC具体慢在哪些点呢?单凭监控还是不能找到元凶的,接下来还需要一些更有力的信息才能继续调查下去,这就是前面Dump出来的堆内存以及服务器中打印的GC日志。
2.3 重要线索
2.3.1 GC日志
接下来切到机器中,查看最近几次的日志。
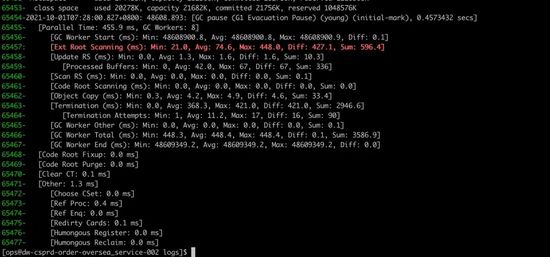
总共花了0.4573432秒,共8核并行执行。仔细,看这些数据,发现有一处很不合理,就是上面红色的那一行。 Ext Root Scanning堆外部根扫描,总共花了596ms,其中最高448ms ,要知道这次ygc也才花457ms,几乎把所有时间都花在这个Ext Root Scanning。
2.3.2 堆分析
下面是当时dump出来的堆里面发现的不正常对象:
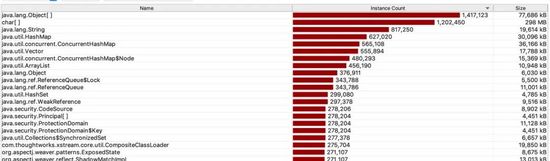

这里可看到堆里面这个CompositeClassLoader这个类的对象偏多。要知道类加载器在系统中负责对类进行加载,通过传入一个类的全限定名称返回一个唯一的确定的类实例。这实属不正常。通过其包名字得知是xstream下面的(xstream是用于处理XML文件的序列化以及反序列化等操作)。
于是查阅xstream的主要的类 com.thoughtworks.xstream.XStream#XStream源码:
public XStream(ReflectionProvider reflectionProvider, Mapper mapper, HierarchicalStreamDriver driver) {this(reflectionProvider, driver, new CompositeClassLoader(), mapper);}
这里是服务里面创建的代码:
public static XStream createNew() {XStream xStream = new XStream(new Xpp3Driver(new NoNameCoder())) {@Overrideprotected MapperWrapper wrapMapper(MapperWrapper next) {return new MapperWrapper(next) {....省去一些无用的代码}};}};...省去一些无用的代码return xStream;}
可以看到每次使用XStream都会创建一个XStream实例,而每个XStream实例都会创建一个CompositeClassLoader的类加载器。而CompositeClassLoader往往都是属于重量级的类,要知道系统自带的AppClassLoader以及ExtClassLoader还有BootstrapClassLoader统统都是单例的!所以这里明显会重复创建不必要的CompositeClassLoader。 到这里,基本已经确定元凶了 。
2.4 破案
接下来重新添加一个方法,把上面的多例改成按照每个类型创建一个单独的XStream对象,并在服务器中缓存,防止每次请求都创建一个单独的XStream实例:
/*** @Description 为每次调用复用XStream*/public static XStream getInstance(Class<?> clazz, String driverType) {return allXStream.computeIfAbsent(clazz, (k) -> {return createNew(driverType);});}
代码改完之后,再发布到产线之后观察结果:
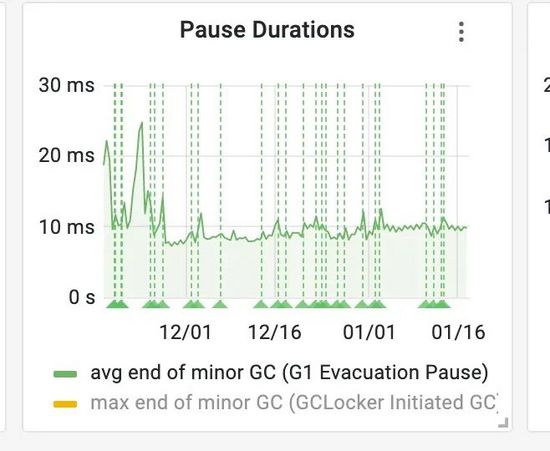
可以看到YGC的时间从1.5秒大幅度减少到平均10来毫秒左右,问题消失。
3.问题复现
因为目前看下来是XStream导致的YGC慢。但是如果想找到问题的源头,这里需要写几个Demo,抽丝剥茧,看看现场是否能复现出来,以便找出幕后的真正原因。
3.1 编写Demo
既然现在已经找到是XStream的问题了。那么接下来,开个新项目,写下如下代码,用于复现线上问题:
public static void main(String[] args) {while (true) {new XStream();}}
输入JVM参数,然后执行:
-XX:+UseG1GC-XX:+PrintGCDetails-XX:+UnlockExperimentalVMOptions-Xms2g-Xmx2g-XX:G1NewSizePercent=40
观察下日志:果然问题复现了。
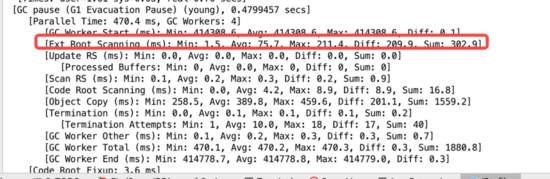
并且通过对比2次YGC留下的存活对象发现:下面这些对象一直在增加(红色部分是增加的)。也就是说虽然这些对象是无法直接使用的,但是因为被Root引用了,变成可达对象,无法在YGC回收。

3.2 更准确一点的Demo
如果看上面的日志,发现在Object Copy比较高。是因为前面的Demo写的比较暴力,就光new这些有问题的对象导致数据在Copy上花了大量的时间,所以这里Demo做少量修改,改成下面这个样子:
public static void main(String[] args) {prepare();System.out.println("准备完毕!可以观察YGC日志");ygc();}private static void prepare() {// 好一点的机器可以把这个1000 * 30调高一点来拖慢YGC时间for (int i = 0; i < 1000 * 30; i++) {new XStream();}}private static void ygc() {while (true) {byte[] ignored = new byte[1024 * 100];}}
多执行几次YGC,然后再观察日志:
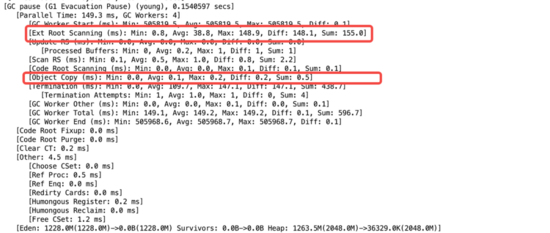
这样就更加符合线上的真实环境了。
3.3 再准确一点的Demo
从源码里面看到了,其实是XStream里面创建的CompositeClassLoader太多导致的问题,那么可以把prepare方法改成下面这个样子:
private static void prepare() {for (int i = 0; i < 1000 * 30 * 20; i++) {new CompositeClassLoader();}}
然后再执行, 可是发现这代码执行之后,问题并没有 复现 。 但是类加载器的作用不就是为了加载类么?于是把代码改成这个样子:
private static void prepare() {// 这里如果如果加载的类太少,这个问题复现不了。所以这里进行放大20倍处理// 其实这个20不准,其实值是40!// 也就是说额外创建一个XStream会触发40次多余的类加载动作for (int i = 0; i < 1000 * 30 * 20; i++) {CompositeClassLoader compositeClassLoader = new CompositeClassLoader();try {Class.forName("com.thoughtworks.xstream.mapper.EnumMapper", true, compositeClassLoader);} catch (ClassNotFoundException ignored) {}}}
再观察结果,问题复现!
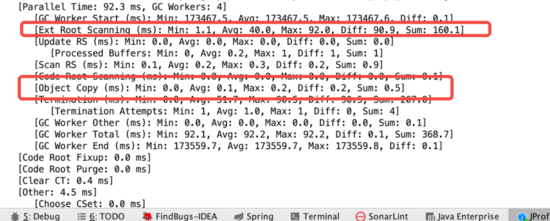
如果只是JDK层面的话,问题基本上已经解决了,也不需要再继续调查下去了。但是本着一个程序员的与生俱来的刨根问底的这么一个特性,这个话题其实还没有完呢。因为这里还有些问题没有调查清楚:
1:为啥类加载器加载的类偏多的情况下啊,YGC的根扫描时间会偏久?
2:说到底,这个创建的XStream和CompositeClassLoader只是一个局部变量而已,为什么会是不可达对象,导致在YGC不能正常回收呢?
目前为止,要想知道答案,仅仅只看JDK的源码是肯定解决不了问题的。想要知道的更多,需要从HotSpot源码入手,继续探索!
4.一追到底
4.1 入口 G1RootProcessor::evacuate_roots
搜索OpenJDK的源代码,找到G1目录hotspot/src/share/vm/gc_implementation/g1下面和根扫描有关的地方,找到G1RootProcessor.cpp文件下面的evacuate_roots方法(文章篇幅有限,所以只展示部分代码,有兴趣的可以自己去下载源码仔细看看):
void G1RootProcessor::evacuate_roots(OopClosure* scan_non_heap_roots,OopClosure* scan_non_heap_weak_roots,CLDClosure* scan_strong_clds,CLDClosure* scan_weak_clds,bool trace_metadata,uint worker_i) {// 开始时间double ext_roots_start = os::elapsedTime();G1GCPhaseTimes* phase_times = _g1h->g1_policy()->phase_times();// 省去一些代码// 处理java根process_java_roots(strong_roots,trace_metadata ? scan_strong_clds : NULL,scan_strong_clds,trace_metadata ? NULL : scan_weak_clds,&root_code_blobs,phase_times,worker_i);if (trace_metadata) {worker_has_discovered_all_strong_classes();}// 处理VM根和stringTable下面的根process_vm_roots(strong_roots, weak_roots, phase_times, worker_i);process_string_table_roots(weak_roots, phase_times, worker_i);{G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::CMRefRoots, worker_i);if (!_process_strong_tasks.is_task_claimed(G1RP_PS_refProcessor_oops_do)) {_g1h->ref_processor_cm()->weak_oops_do(&buf_scan_non_heap_roots);}}// 省去一些代码// 等待执行结束_process_strong_tasks.all_tasks_completed();}
其实这里面主要处理的就2种类型的根:
-
Java根:主要指类加载器和线程栈(见方法:process_java_roots)。
-
类加载器根(CLDGRoots)主要遍历它所引用的存活的Klass(对应java的class对象)并复制到其他区
-
线程栈根(ThreadRoots)包含java栈和本地栈涉及的局部变量等
-
-
JVM根:通常是一些全局的static修饰的C、C++变量(见方法:process_vm_roots)
-
hotspot虚拟机需要保存的一些全局的变量。其中包括:JNIHandles,ObjectSynchronizer,SystemDictionary,StringTables,Jvmti等
-
2.GC需要处理的步骤清单 G1GCPhaseTimes::G1GCPhaseTimes
再继续查找代码发现:G1GCPhaseTimes.cpp文件下的G1GCPhaseTimes方法里面都是需要处理的步骤,其中包括扫描的根的类型集合,下面这些也会在日志中打印执行时间:
G1GCPhaseTimes::G1GCPhaseTimes(uint max_gc_threads) :_max_gc_threads(max_gc_threads){_gc_par_phases[GCWorkerStart] = new WorkerDataArray<double>(max_gc_threads, "GC Worker Start (ms)", false, G1Log::LevelFiner, 2);_gc_par_phases[ExtRootScan] = new WorkerDataArray<double>(max_gc_threads, "Ext Root Scanning (ms)", true, G1Log::LevelFiner, 2);_gc_par_phases[ThreadRoots] = new WorkerDataArray<double>(max_gc_threads, "Thread Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[StringTableRoots] = new WorkerDataArray<double>(max_gc_threads, "StringTable Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[UniverseRoots] = new WorkerDataArray<double>(max_gc_threads, "Universe Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[JNIRoots] = new WorkerDataArray<double>(max_gc_threads, "JNI Handles Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[ObjectSynchronizerRoots] = new WorkerDataArray<double>(max_gc_threads, "ObjectSynchronizer Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[FlatProfilerRoots] = new WorkerDataArray<double>(max_gc_threads, "FlatProfiler Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[ManagementRoots] = new WorkerDataArray<double>(max_gc_threads, "Management Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[SystemDictionaryRoots] = new WorkerDataArray<double>(max_gc_threads, "SystemDictionary Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[CLDGRoots] = new WorkerDataArray<double>(max_gc_threads, "CLDG Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[JVMTIRoots] = new WorkerDataArray<double>(max_gc_threads, "JVMTI Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[CodeCacheRoots] = new WorkerDataArray<double>(max_gc_threads, "CodeCache Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[CMRefRoots] = new WorkerDataArray<double>(max_gc_threads, "CM RefProcessor Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[WaitForStrongCLD] = new WorkerDataArray<double>(max_gc_threads, "Wait For Strong CLD (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[WeakCLDRoots] = new WorkerDataArray<double>(max_gc_threads, "Weak CLD Roots (ms)", true, G1Log::LevelFinest, 3);_gc_par_phases[SATBFiltering] = new WorkerDataArray<double>(max_gc_threads, "SATB Filtering (ms)", true, G1Log::LevelFinest, 3);// 其他功能的时间,如更新、扫描RSet,对象复制,重建Rset、大对象处理等_gc_par_phases[UpdateRS] = new WorkerDataArray<double>(max_gc_threads, "Update RS (ms)", true, G1Log::LevelFiner, 2);_gc_par_phases[ScanRS] = new WorkerDataArray<double>(max_gc_threads, "Scan RS (ms)", true, G1Log::LevelFiner, 2);_gc_par_phases[CodeRoots] = new WorkerDataArray<double>(max_gc_threads, "Code Root Scanning (ms)", true, G1Log::LevelFiner, 2);// ...省去一些其他代码}
上面显示的是需要扫描的根列表。而现场显示的Ext Root Scanning的时间久。而其总和即为下面第7行起后面涉及根扫描的总和。所以如果想知道具体Ext Root Scanning哪部花的时间久,需要把下面的详细日志给输出出来。观察后面的参数,发现大部分需要日志级别达到:G1Log::LevelFinest的时候,会输出对应的信息。也就是对于的G1日志级别为finest。
于是这里调整jvm参数,加上下面这个:
-XX:G1LogLevel=finest
再次观察日志:
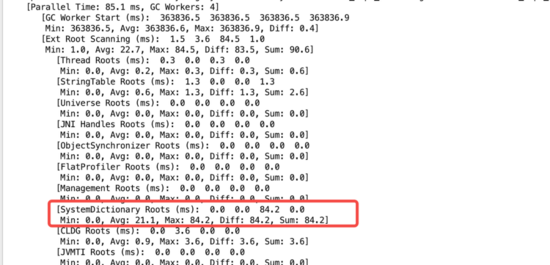
搜索并查找和SystemDictionaryRoots相关的代码:
void SystemDictionary::roots_oops_do(OopClosure* strong, OopClosure* weak) {strong->do_oop(&_java_system_loader);strong->do_oop(&_system_loader_lock_obj);Ticks start = Ticks::now();CDS_ONLY(SystemDictionaryShared::roots_oops_do(strong);)// 调整字典dictionary()->roots_oops_do(strong, weak);// 访问额外的方法invoke_method_table()->oops_do(strong);}
由于不确定是哪行代码导致的请求慢,于是修改源代码,通过使用Ticks::now()获取当前时间,并打印出来。发现耗时最久的其实是dictionary()->roots_oops_do(strong, weak) 这行代码,此方法几乎占用整个方法的99%以上的时间。再仔细翻阅源码,发现此方法内部会遍历SystemDictionary::dictionary()字典下面所有添加过的项,并根据情况进行标记。这里简单介绍下SystemDictionary::dictionary():
SystemDictionary::dictionary()维护的是一个全局的static字典。这里虚拟机里面的Dictionary其实就等价于java里面的HashMap。
-
字典维护的key是Symbol *class_name和ClassLoaderData *loader_data
-
class_name即是类的标识符,即类的全限定名称(包名+类名)
-
loader_data对应的是java里面的ClassLoader对象。
-
-
字典维护的value是DictionaryEntry *对象,这个类有三个字段
-
包括KlassHandle obj,即对应java语言中的class对象,也就是类加载器加载之后返回的类
-
一个hash值,值由key决定,也就是由类全限定名+类加载器计算的int类型值
-
类加载器loader_data
-
4.3 类加载之 SystemDictionary::dictionary()
想要知道的更多,需要翻阅Dictionary类的源码。找到对应SystemDictionary::dictionary()添加记录的源码如下:
// class_name对应java里面的类全限定名,包名+类名// loader_data对应java里面的ClassLoader,类加载器// obj 对应java里面的类对象,即Class对象void Dictionary::add_klass(Symbol *class_name, ClassLoaderData *loader_data,KlassHandle obj) {assert_locked_or_safepoint(SystemDictionary_lock);assert(obj() != NULL, "adding NULL obj");assert(obj()->name() == class_name, "sanity check on name");assert(loader_data != NULL, "Must be non-NULL");unsigned int hash = compute_hash(class_name, loader_data);int index = hash_to_index(hash);DictionaryEntry *entry = new_entry(hash, obj(), loader_data);add_entry(index, entry);}
4.4 基本的加载动作 SystemDictionary::resolve_instance_class_or_null
Klass* SystemDictionary::resolve_instance_class_or_null(Symbol* name,Handle class_loader,Handle protection_domain,TRAPS) {...省去一些代码EventClassLoad class_load_start_event;class_loader = Handle(THREAD, java_lang_ClassLoader::non_reflection_class_loader(class_loader()));ClassLoaderData *loader_data = register_loader(class_loader, CHECK_NULL);// 类符号名name+类加载器loader_data当作key// 并且访问者是否有访问权限时候// 从dictionary获取缓存的Klass// 如果没有获取成功,后面会触发类加载操作,并将加载完成的类放到dictionary中unsigned int d_hash = dictionary()->compute_hash(name, loader_data);int d_index = dictionary()->hash_to_index(d_hash);Klass* probe = dictionary()->find(d_index, d_hash, name, loader_data,protection_domain, THREAD);if (probe != NULL) return probe;...省去一些代码}
在java里面唯一确认一个类的方式就是 类加载器+类全限定名称,并且在类加载里面存在缓存机制,同一个类加载器+类限定名加载的类仅会加载一次,从上面的代码可以看到,这个记录它就记录在SystemDictionary::dictionary()里面!大致加载流程如下:
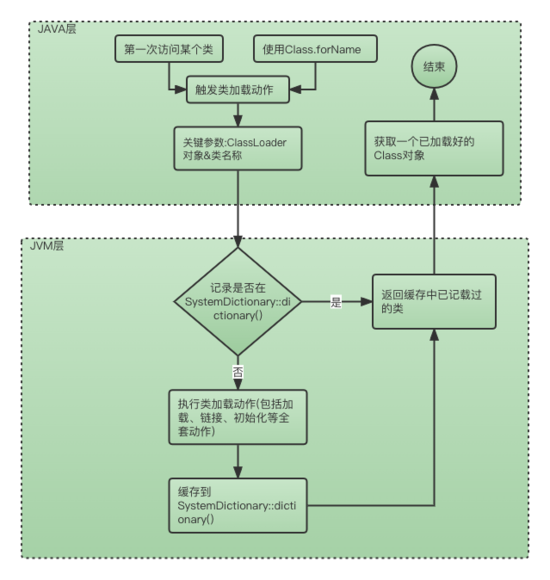
4.5 拨开迷雾
所以,本文所描述的问题的根本原因找到了:
a. 因为每次new的都是一个不同的CompositeClassLoader,所以每次这个类加载器加载类的时候,都会调用Dictionary::add_klass方法往SystemDictionary::dictionary()插入一些记录,而SystemDictionary::dictionary() 所引用的字段是一个用static修饰的全局变量。
b. SystemDictionary::dictionary()对象在YGC的时候并不释放,虽然本场景下其大部分对象都是不可达的,(SystemDictionary::dictionary()中不可达的对象只会在mix-gc或者full-gc的时候才会回收和卸载)。
c. YGC的时候,会遍历SystemDictionary::dictionary(),并且将符合条件的对象当作root进行根扫描。
d. 由于程序以错误的方式不停的执行类加载操作(无法使用缓存),导致不停的往SystemDictionary::dictionary() 插入记录,以至于SystemDictionary::dictionary()一度膨胀到有上千万条记录(50万+的CompositeClassLoader,每个CompositeClassLoader会加载40次类,共2000万+条记录)。虽然是内存遍历,但是这么庞大的数据量,再强劲的CPU也需要花很多时间。可想而知:YGC漫长的原因由此而来!
5.知识小结
5.1 类加载
-
类和接口的名称,都是通过全限定形式(fully qualified form)表示。如java.lang.Thread表示为java/lang/Thread
-
类加载器
-
如果一个类加载器L直接创建了一个类C,那么称之为L是C的定义加载器(defininng loader)
-
如果一个类加载器L负责加载某个类C,但是实际将加载动作委托给了其他类加载器,那么L称为C的初始类加载器(initiating loader)
-
如果一个类L加载了一个类或者接口C,那么会往SystemDictionary::dictionary()插入两条条记录,分别是定义类加载器+C、初始类加载器+C。同时将这个类也起到了一个缓存作用,类加载器加载相同的类的时候,避免重复加载
-
根据的实际业务场景,避免重复创建相同功能的类加载器
-
5.2 YGC&G1
-
在JDK8中,G1可以说是最热门,同时也是最成熟的垃圾收集器
-
G1将内存分为很多个区,为了满足期望的停顿时间,并不会回收全部的区
-
G1的YGC会一次性回收所有的新生代对象,并且伴有STW
-
G1在YGC中的根扫描包含Java根和Jvm根。Java根包括线程栈和类加载器,Jvm根通常是一些全局的变量
-
可以开启如下参数,以便获取更详细一点的GC日志信息:
-XX:+UnlockExperimentalVMOptions
-XX:G1LogLevel=finest
5.3 XStream
-
翻阅XStream的源码,可以看到如下注释:
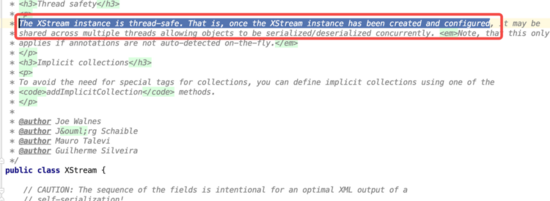
官方已经说了,XStream类本身就是线程安全的,建议使用单例模式使用!
-
所以说:使用第三类和工具的时候,有必要花些时间去了解下这个类,避免踩坑!

















 1707
1707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









