




 本文探讨了微服务中缓存一致性问题,包括先删缓存再更新数据库、先更新数据库再删除缓存两种策略及其潜在问题。提出重试机制和并发读写的解决方案,强调使用消息队列和特定的缓存操作来确保数据一致性。
本文探讨了微服务中缓存一致性问题,包括先删缓存再更新数据库、先更新数据库再删除缓存两种策略及其潜在问题。提出重试机制和并发读写的解决方案,强调使用消息队列和特定的缓存操作来确保数据一致性。
只要我们使用缓存,就必然会面对缓存和数据库间的一致性问题。如果缓存中的数据和数据库的数据不一致,那么业务应用从缓存中读取的数据就不是最新的数据,对业务的影响可想而知。比如我们把商品的库存数据存在缓存中,如果缓存中的库存数据不对,那么可能就会影响下单操作,这是业务上很难接受的。本篇文章我们来一起聊一聊缓存的一致性问题。
如何解决缓存不一致
先删缓存再更新数据库
假设线程A删除缓存后,还没来得及更新数据库,这时候线程B开始读数据,线程B发现缓存缺失就只能去读数据库,等到线程B从数据库中读取完数据回塞缓存后,线程A才开始更新数据库,此时,缓存中的数据是旧值,而数据库中是最新值,两者已经不一致了。
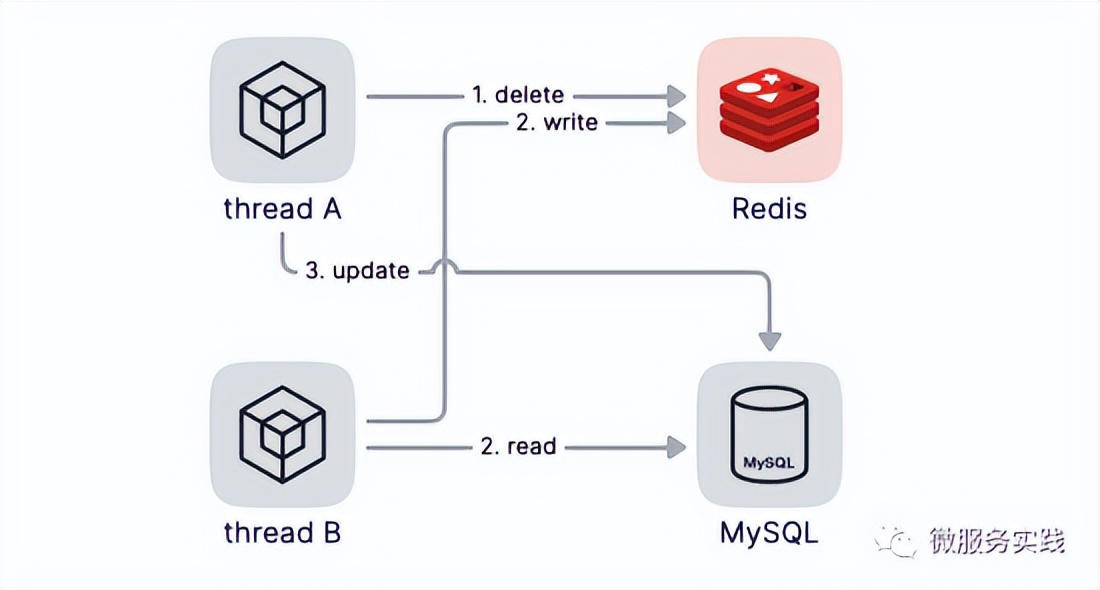
这种场景的解决方案是在线程A更新完数据库的值后,可以让它sleep一小段时间,再进行一次缓存删除操作,之所以要加上sleep的一段时间,就是为了让线程B能够先从数据库读取出数据然后再把缓存miss的数据回塞到缓存,然后线程A再进行删除。所以线程A的sleep时间就需要大于线程B读取数据再写入缓存的时间。这个时间是多少呢?这个是需要我们在业务中加入打点监控来统计的,根据这个统计值来估算该时间。这样一来,其他线程读取数据时,会发现缓存缺失,就会从数据库中读取最新的值。我们把这种模型叫做 "延时双删"。
先更新数据库再删除缓存
如果线程A更新了数据库中的值,但还没来得及删除缓存中的值,线程B这时候开始读取数据,此时,线程B查询缓存时,命中了缓存,就会直接使用缓存中的值,该值为旧值。不过在这种场景下,如果并发请求量不高的话,其实基本上不会有线程读到旧值,而且线程A更新完数据库后,删除缓存是非常快的操作,所以,这种情况总体对业务影响较小。一般在生产环境中,也推荐大家采用该模式。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









