




 本文详细介绍如何在已有的HadoopYarn环境中部署Spark,包括配置Yarn、运行spark-shell和spark-sql的方法,以及解决常见错误的策略。
本文详细介绍如何在已有的HadoopYarn环境中部署Spark,包括配置Yarn、运行spark-shell和spark-sql的方法,以及解决常见错误的策略。
如果你已经有一个正常运行的Hadoop Yarn环境,那么只需要下载相应版本的Spark,解压之后做为Spark客户端即可。
需要配置Yarn的配置文件目录,export HADOOP_CONF_DIR=/etc/hadoop/conf 这个可以配置在spark-env.sh中。
运行命令:
cd $SPARK_HOME/bin
./spark-shell \
--master yarn-client \
--executor-memory 1G \
--num-executors 10- 1
- 2
- 3
- 4
- 5
注意,这里的–master必须使用yarn-client模式,如果指定yarn-cluster,则会报错:
Error: Cluster deploy mode is not applicable to Spark shells.
因为spark-shell作为一个与用户交互的命令行,必须将Driver运行在本地,而不是yarn上。
其中的参数与提交Spark应用程序到yarn上用法一样。
启动之后,在命令行看上去和standalone模式下的无异: 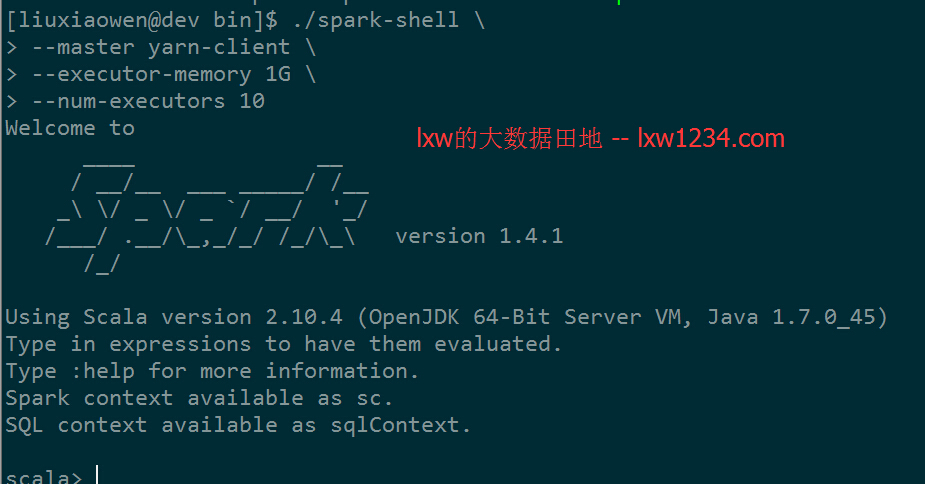
在ResourceManager的WEB页面上,看到了该应用程序(spark-shell是被当做一个长服务的应用程序运行在yarn上): 
点击ApplicationMaster的UI,进入到了Spark应用程序监控的WEB页面: 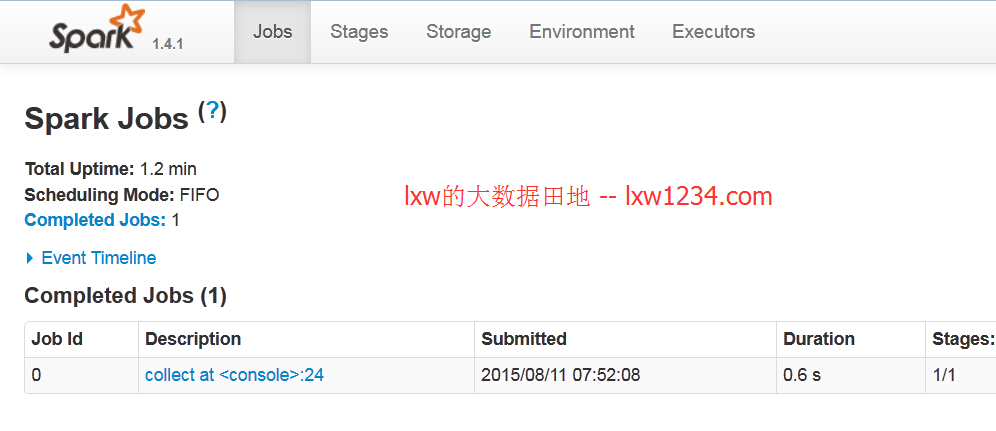
spark-sql On Yarn
spark-sql命令行运行在yarn上,原理和spark-shell on yarn一样。只不过需要将Hive使用的相关包都加到Spark环境变量。
- 将hive-site.xml拷贝到$SPARK_HOME/conf
2.export HIVE_HOME=/usr/local/apache-hive-0.13.1-bin 添加到spark-env.sh
3.将以下jar包添加到Spark环境变量:
datanucleus-api-jdo-3.2.6.jar、datanucleus-core-3.2.10.jar、datanucleus-rdbms-3.2.9.jar、mysql-connector-java-5.1.15-bin.jar
可以在spark-env.sh中直接添加到SPARK_CLASSPATH变量中。
运行命令:
cd $SPARK_HOME/bin
./spark-sql \
--master yarn-client \
--executor-memory 1G \
--num-executors 10- 1
- 2
- 3
- 4
- 5
即可在yarn上运行spark-sql命令行。 
在ResourceManager上的显示以及点击ApplicationMaster进去Spark的WEB UI,与spark-shell无异。 
这样,只要之前有使用Hadoop Yarn,那么就不需要搭建standalone的Spark集群,也能发挥Spark的强大威力了。


















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









