



 本文深入探讨了YOLOv4的架构与优化策略,包括超快物体检测的实现,以及如何利用免费礼包(BoF)和特价礼包(BoS)提升检测精度。详细介绍了数据增强、边界框回归损失、感受野扩大、注意力机制等关键技术。
本文深入探讨了YOLOv4的架构与优化策略,包括超快物体检测的实现,以及如何利用免费礼包(BoF)和特价礼包(BoS)提升检测精度。详细介绍了数据增强、边界框回归损失、感受野扩大、注意力机制等关键技术。
论文: YOLOv4: Optimal Speed and Accuracy of Object Detection
下载地址:https://arxiv.org/pdf/2004.10934.pdf.
目录
1. 引言
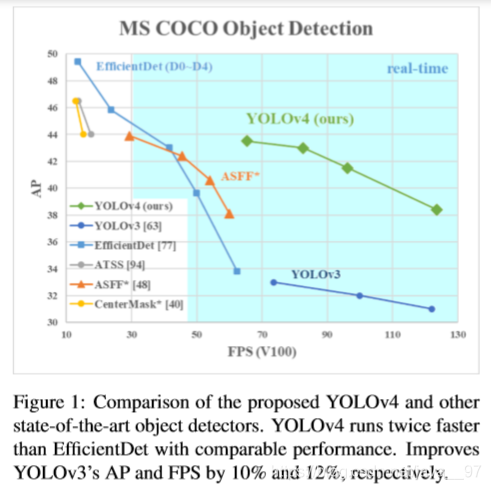
文章主要贡献:
- 可以使用1080Ti或者2080Ti GPU来训练超快速和准确的物体检测器。
- 在检测器训练过程中验证了当前目标检测的各种SOTA,分为bag of freebies(免费礼包)和 bag of specials(特价礼包)。
- 改进了SOTA,如CBN,PAN,SAM等,使它们更有效,更适合单GPU训练。
2. 相关工作
文章首先介绍了检测器的一般架构,然后将YOLOv4所综合的方法分为两部分介绍:bag of freebies 和 bag of specials。
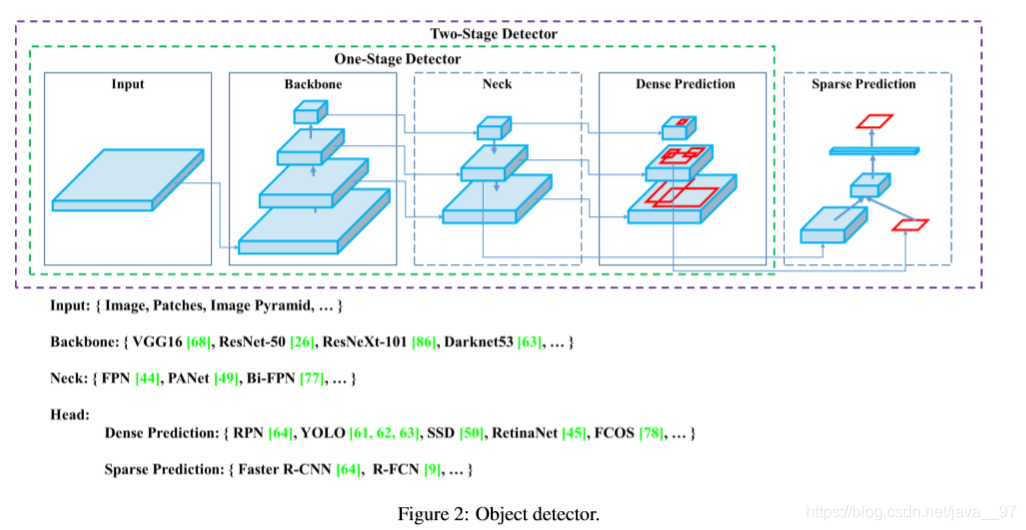
2.1 Object Detectors
一般可将检测器结构分为以下几个部分:
1. backbone:在ImageNet上进行预训练,一般GPU平台用VGG, ResNet,ResNeXt, DenseNet;CPU用SqueezeNet, MobileNet , ShuffleNet。
2. head :分为两阶段检测器(RCNN系列)和单阶段检测器(YOLO系列,SSD,RetinaNet);
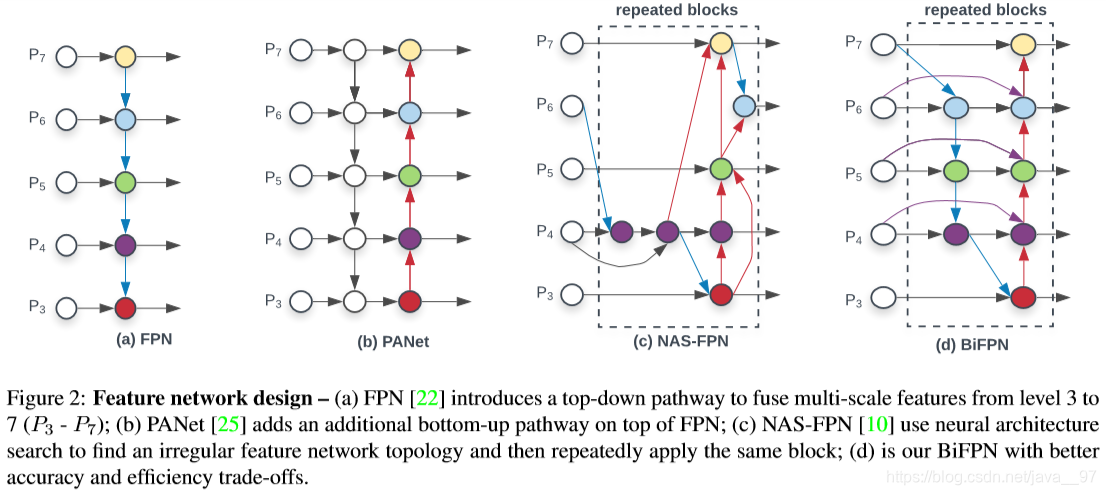
3. neck :位于backbone和head之间,综合不同阶段的特征图,通常由几个自下而上的paths和几个自上而下的paths组成。有 Feature Pyramid Network (FPN) , Path Aggregation Network (PAN) , BiFPN, NAS-FPN。

2.2 Bag of Freebies(BoF)
bag of freebies字面意思是免费礼包,指那些仅通过改变训练策略或者增加训练成本的方式提高检测精度,并不影响检测inference time的方法。
1. 数据增强:增加数据的多样性,提高检测器的鲁棒性和环境适应性。
(1)photometric distortions(光度扭曲):调整亮度、对比度、色相、饱和度和噪点。
(2)geometric distortions(几何扭曲):随机缩放,裁剪,翻转和旋转。
(3)模仿物体遮挡:
- 对于图像来说,随机擦除或CutOut:随机选择图像中的矩形区域并随机填充或互补值零。
- 图像掩膜的方法,hide-and-seek and grid mask:随机或平均选择多个图像中的矩形区域全部置零。
- 对于feature map来说,类似方法是DropOut, DropConnect, DropBlock 。
(4)使用多张图片进行数据增强:
- Mixup:将两张图片以不同系数比例相乘和叠加,然后用叠加比例调整标签。
- CutMix:用其他图像填补裁剪掉的矩形区域,根据混合区域大小调整标签。
(5)GAN的风格迁移也可用于数据增强,减少CNN学习的纹理偏差。
2. 解决数据集的语义分布偏差:
- 类别不平衡:对于两阶段检测器的解决办法是难负例挖掘或在线难例挖掘;对于单阶段检测器的解决办法是focal loss。
- 使用one-hot hard representation难以表达出不同类别之间的关联程度:解决办法是label smoothing,在训练时将hard label转换为soft label,使训练更鲁棒。还有人提出knowledge distillation(知识蒸馏)的概念来设计label refinement network。
3. 目标边界框回归的损失函数:
- 传统的MSE损失将 x , y , w , h x, y, w, h x,y,w,h这些点视为独立变量,未考虑目标自身的完整性。
- IoU考虑了predicted BBox和ground truth BBox的覆盖范围,而且具有尺度不变性,克服了MSE对尺度变化敏感的问题。
- GIoU除了考虑覆盖范围,还考虑了形状和方向。
- DIoU还考虑了物体的中心距离。
- CIoU同时考虑了重叠面积,中心点距离和长宽比。能得到更好的收敛速度和检测精度。
此处贴一下上述损失函数的论文原文以及相关解读的博客文章:
IoU和GIoU:
论文:https://arxiv.org/pdf/1902.09630.pdf
博客:论文笔记:GIoU
DIoU和CIoU:
论文:https://arxiv.org/pdf/1911.08287.pdf
博客:DIoU YOLOv3 | AAAI 2020:更加稳定有效的目标框回归损失
2.3 Bag of Specials(BoS)
bag of specials字面意思是特价礼包,指那些通过增加一点点inference time但带来显著精度提升的方法。
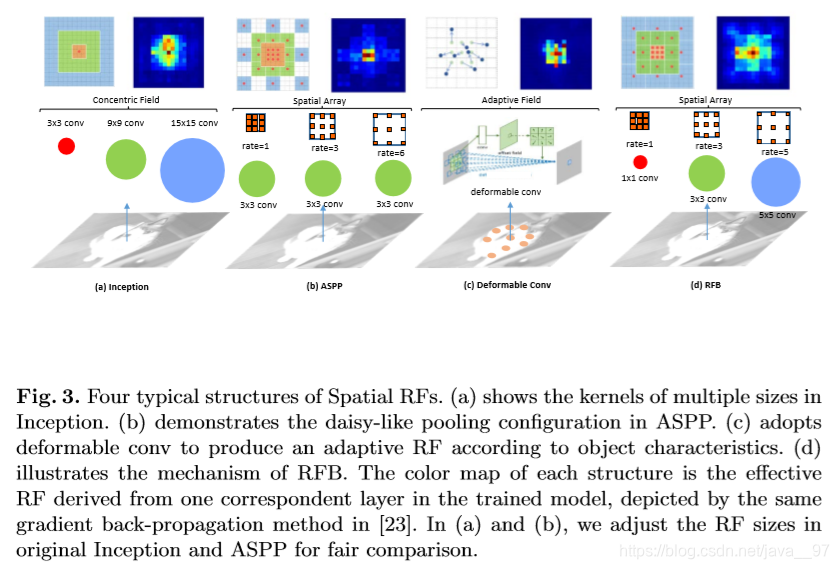
1. 增大感受野
-
SPP:通过max pooling实现,YOLOv3将SPP模块改进为 k × k k×k k×k最大池化输出的级联,YOLOv3-608在MS COCO数据集上AP50提高2.7%,计算量才增加0.5%。
-
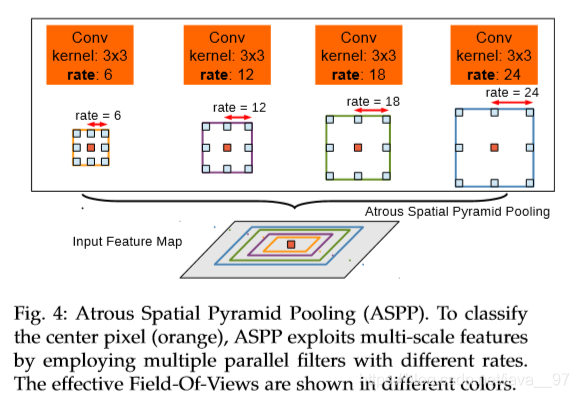
ASPP(Atrous Spatial Pyramid Pooling):与改进SPP模块不同之处在于使用多个3×3的最大池化,膨胀比为 k k k,步长为1的膨胀卷积。
论文下载地址:https://arxiv.org/pdf/1606.00915.pdf
-
RFB(Receptive Field Block):使用多个 k × k k×k k×k的最大池化,膨胀比为 k k k,步长为1的膨胀卷积,比ASPP获得更全面的空间覆盖率。在SSD上增加7%的inference time, AP50提高5.7%。
论文下载地址:https://arxiv.org/pdf/1711.07767.pdf
代码:https://github.com/ruinmessi/RFBNet
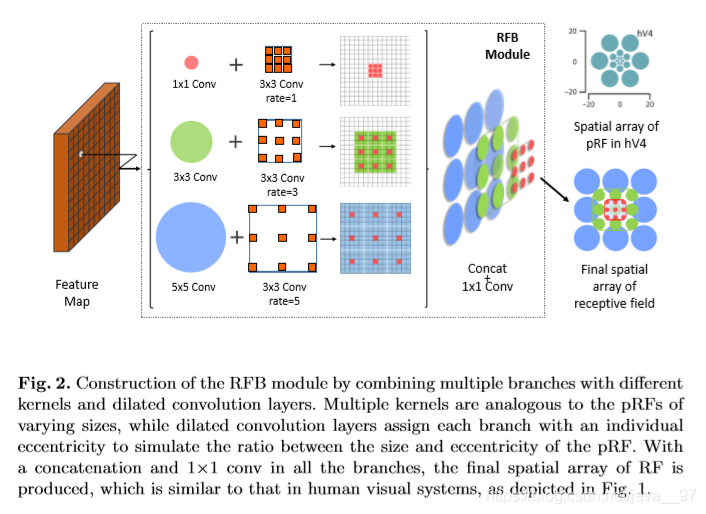
RFB论文给出的CNN中关于感受野的相关研究比较:
2. 增加注意力机制
- channel-wise attention:Squeeze-and-Excitation (SE) ,应用于ResNet-50,可将ImageNet top-1准确率提高1%,计算量只增加2%。但是在GPU上inference time增加10%,更适合移动设备。
- point-wise attention:Spatial Attention Module (SAM),应用于ResNet50-SE,可将ImageNet top-1准确率提高0.5%,计算量只增加0.1%。基本不影响GPU上的inference time。
3. 增强特征融合能力
(1)skip connection
(2)hyper-column
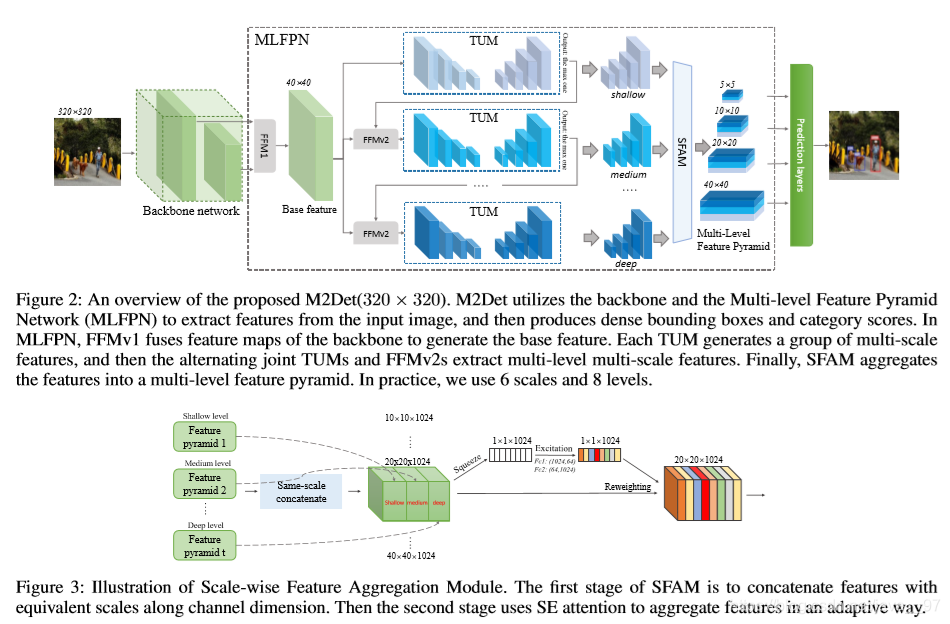
(3)multi-scale prediction:如FPN,还有以下几种方法:
- SFAM(Scale-wise Feature Aggregation Module):使用SE模块对多尺度连接特征图进行channel-wise level的re-weighting。
论文下载地址:https://arxiv.org/pdf/1811.04533.pdf
代码:https://github.com/qijiezhao/M2Det
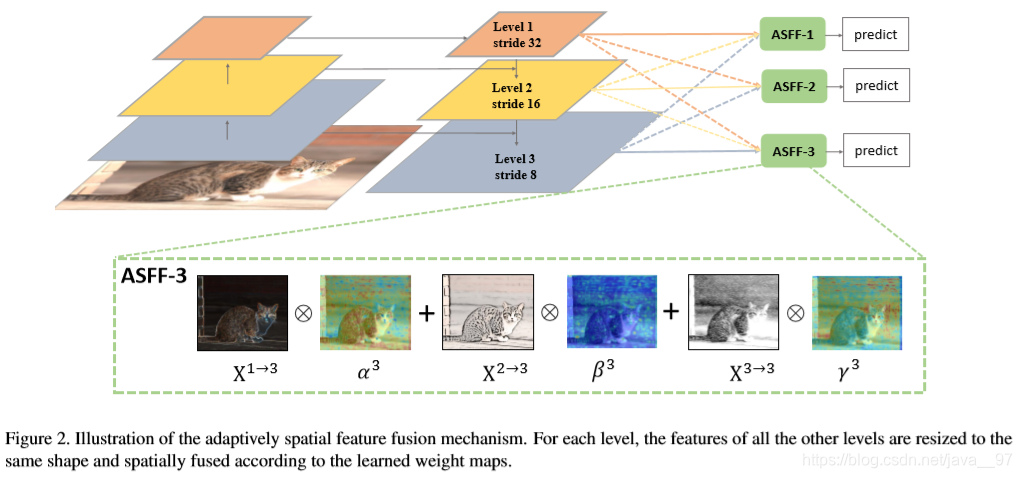
- ASFF(Adaptively Spatial Feature Fusion):使用softmax进行point-wise level的re-weighting,然后将不同尺度特征图叠加。
论文下载地址:https://arxiv.org/pdf/1911.09516.pdf
代码:https://github.com/ruinmessi/ASFF

- BiFPN(Bi-directional Feature Pyramid Network):提出multi-input weighted residual connections,执行scale-wise level的re-weighting,然后将不同尺度特征图叠加。
论文下载地址:https://arxiv.org/pdf/1911.09070.pdf
代码:https://github.com/google/automl/tree/master/efficientdet
4. 激活函数
好的激活函数能使梯度有效传播,同时不增加太多额外的计算量。
- ReLU
- LReLU
- PReLU
- ReLU6
- Scaled Exponential Linear Unit (SELU)
- Swish
- hard-Swish
- Mish
LReLU 和 PReLU 是解决当输出小于零时,ReLU的梯度为零。
ReLU6 和 hard-Swish 是专为quantization networks设计的。
SELU 用于 self-normalizing a neural network。
Swish 和 Mish 具有连续微分的激活功能。
贴一篇介绍激活函数很全面的博客:
深度学习—激活函数详解(Sigmoid、tanh、ReLU、ReLU6及变体P-R-Leaky、ELU、SELU、Swish、Mish、Maxout、hard-sigmoid、hard-swish)
5. 后处理筛选模型的预测结果
- greedy NMS:原始的NMS方法没有考虑context information,R-CNN中采用分类置信度得分作为参考,从高到低排序执行greedy NMS。
- soft NMS:考虑了物体遮挡会引起greedy NMS中带有IoU评分的置信度得分下降。
- DIoU NMS:在soft NMS的基础上将中心点距离的信息添加到BBox筛选过程中。
由于上述后处理方法都不直接涉及捕获的图像特征,在后来发展出的anchor-free方法中不再需要后处理。
3. 方法
基本目标是在生产系统中使用神经网络以更快的速度运行,并优化并行计算,而不是使用低计算量理论指标(BFLOP)。文章提出了两种实时神经网络选择:
- GPU: CSPResNeXt50 / CSPDarknet53
- VPU(Vision Processing Unit):使用分组卷积,避免使用SE(Squeeze-and-Excitement)模块。EfficientNet-lite / MixNet / GhostNet / MobileNetV3
3.1 网络结构的选择
- backbone的选择,作者研究表明:
在ILSVRC2012上 CSPResNeXt50 好于 CSPDarknet53
在MS COCO上 CSPDarknet53 好于 CSPResNeXt50

- additional blocks的选择,为的是从不同 level 的 backbone 中为不同 level 的检测器选择最佳的增加感受野和参数整合的方法,如FPN, PAN, ASFF, BiFPN。与分类器相比,检测器需要:
- 更高的输入分辨率——用于检测多个小型物体
- 更多层——更高的感受野,为能覆盖增加的网络输入尺寸
- 更多的参数——模型能有更强的检测多尺度多目标的能力
文章还提到感受野大小的影响:

作者选择在 CSPDarknet53 加入 SPP 模块增大感受野,并使用 PANet 为不同 level 的检测器进行不同 level 的 backbone 的参数整合。
简单说,YOLOv4 = CSPDarknet53 backbone + SPP + PANet neck +YOLOv3 head
3.2 BoF和BoS的选择
为了提高目标检测器的训练效果,一般采用如下策略:

3.3 其他的改进
作者主要想设计更适合单GPU训练的检测器,做出的额外设计和改进如下:
- Mosaic数据增强:一种新的数据增强方法,该方法混合了4张训练图像,因此混合了4个不同的上下文信息,而CutMix仅混合了2张输入图像。该方法可以检测正常上下文以外的物体。 此外,批量归一化在每层上的从4张不同图像计算激活统计信息,减少了对大mini-batch size的需要。

- Self-Adversarial Training (SAT) :也是一种新的数据增强技术。
在第一阶段,神经网络会更改原始图像而不是网络权重。 这样,神经网络会执行自对抗性攻击,改变原始图像来制造图像上没有目标物体的假象。
在第二阶段,以正常的方式训练神经网络在修改后的图像上检测目标。 - 使用遗传算法选择最佳超参数
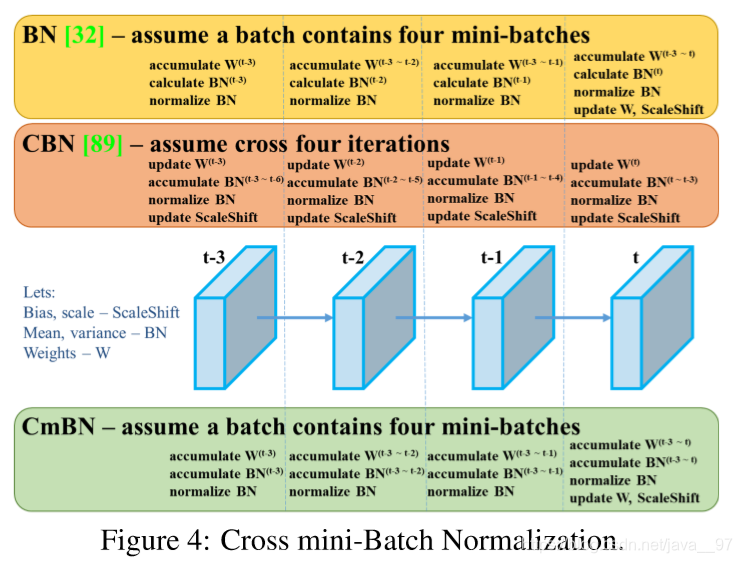
- 改进SAM,PAN 和 Cross mini-Batch Normalization (CmBN)
(1)CmBN
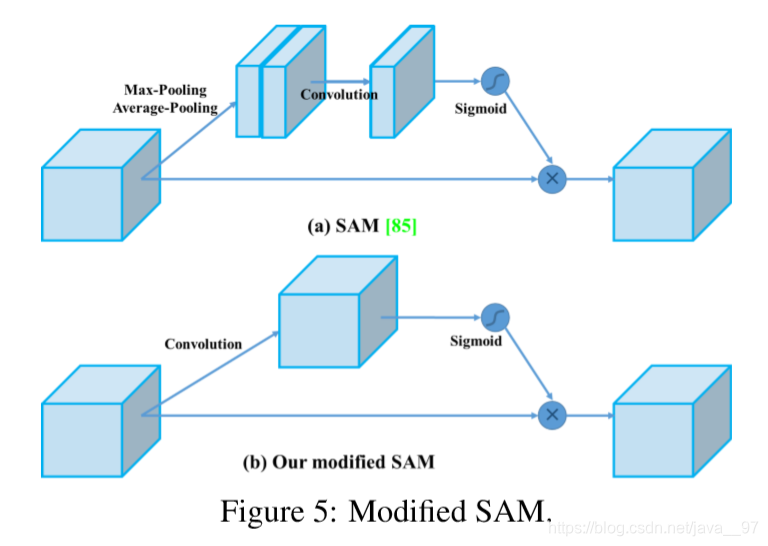
(2)SAM的改进
将空间注意力机制改为点注意力机制。modified SAM中没有使用pooling, 而是直接用一个卷积得到的特征图直接使用Sigmoid进行激活, 然后对应点相乘。
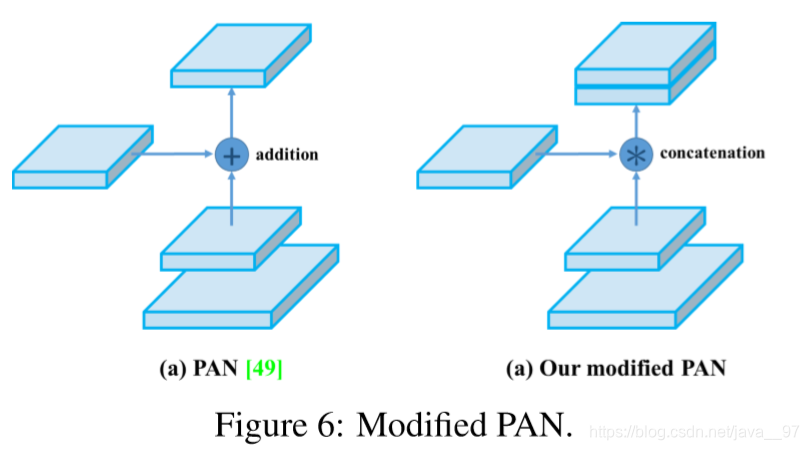
(3)PAN( Path Aggregation Network)的改进
将跳跃连接改为级联。文章未作详细分析。
PANet论文下载地址:https://arxiv.org/pdf/1803.01534.pdf
代码:https://github.com/ShuLiu1993/PANet
在看YOLOv4论文过程中,发现在Path-aggregation这方面,基于FPN进行改进的文章还挺多的,如 SFAM,ASFF,BiFPN,NAS-FPN,PANet。前三篇大致看了看方法,前面贴出了几张图,觉得还是挺有新意的,准备接下来重点研读一下这几篇文章,重新开一篇博客总结归纳一下。
贴一篇PANet解读的博客:
PANet算法笔记
3.4 YOLOv4
前面已经说过了YOLOv4的组成:

具体细节如下:

4. 实验结果
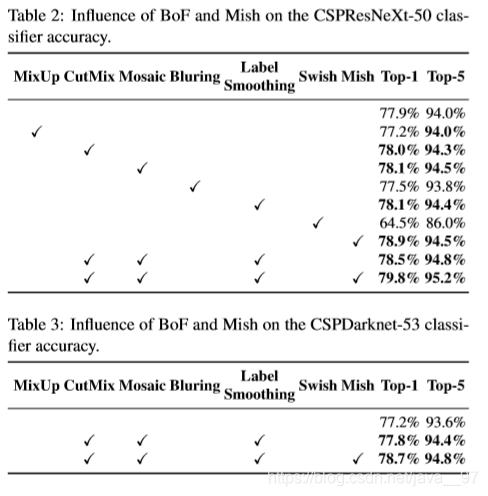
1. 不同BoF对分类器精度的影响。
CutMix 和 Mosaic两种数据增强方式、 Class label smoothing 和 Mish 激活函数在训练过程中能提高分类器的精度。

2. (1)不同BoF对检测器精度的影响
标绿色的tricks在U版YOLOv3中已经被采用。


精度提升效果还是挺可观的。最佳组合到4%、5%了,实属不易。
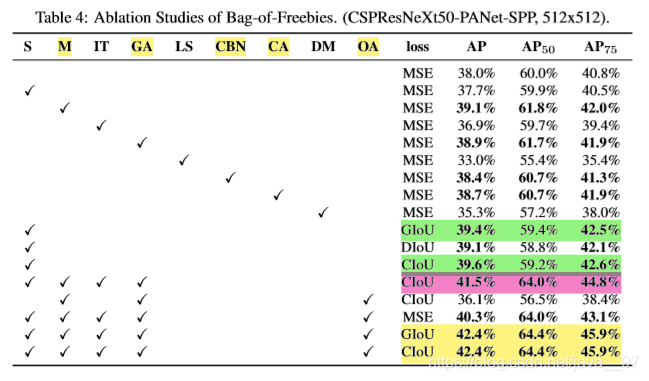
(2)不同BoS对检测器精度的影响
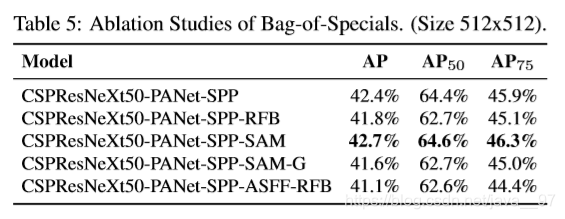
测试了PAN, RFB, SAM, GaussianYOLO(G), and ASFF。最佳组合是PAN-SPP-SAM。
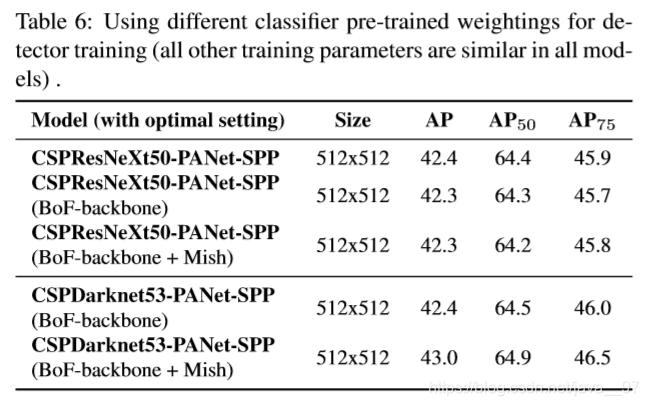
(3)不同backbone和预训练权重的影响
① CSPResNeXt50分类器准确率更高,CSPDarknet53检测器准确率更高。
② BoF+Mish+CSPDarknet53使用预训练分类器权重,能同时提高分类器和检测器的准确率。
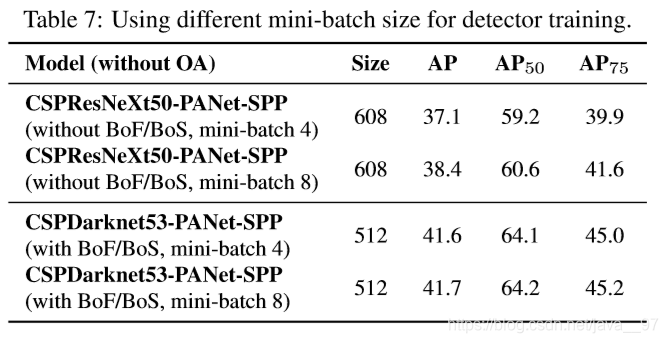
(4)训练检测器过程中不同mini-batch size的影响
增加了BoF和BoS后,mini-batch size对检测器性能几乎没有影响,因此无需使用更昂贵的GPU就可以训练出色的检测模型。
文章最后给出了不同GPU架构上(Maxwell、Pascal、Volta)各算法的性能对比,具体参见论文原文,这里只贴一下YOLOv4




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









