



Redis持久化机制
RDB:是Redis默认的持久化方式。按照配置周期性的把内存的数据以快照的形式保存到硬盘的二进制文件中。直接拿文件内容重建。
AOF:Redis会将每一个收到的写命令都以日志的形式记录下来。当Redis重启时会通过按顺序执行文件中保存的写命令来在内存中重建整个数据库的内容。
说明:当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
优劣:
- 性能:RDB > AOF
- 数据一致性:RDB < AOF
Redis为什么这么快
- 纯内存操作
- 单线程操作,避免了频繁的上下文切换
- 采用了非阻塞I/O多路复用机制(最大限度地利用内核资源)
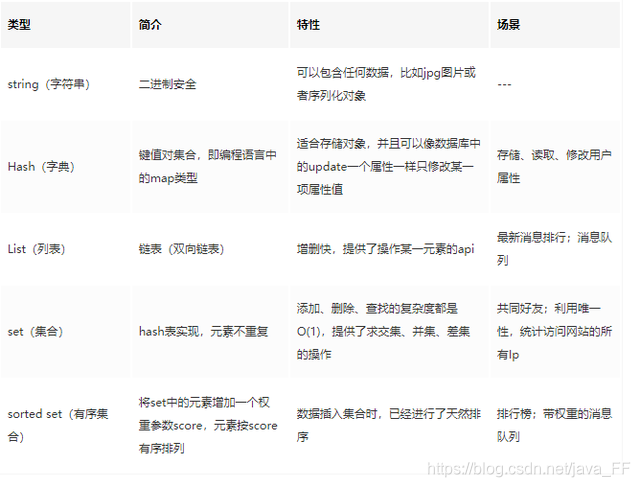
Redis的数据类型
什么样的数据该设置缓存
热点数据,缓存才有价值。
热点数据:读取频率很高的数据。如导航的定位信息,缓存后可以读取数百万次;如抖音的点赞数,收藏数,读取频率很高,同时更新频率也很高,这样的数据也时热点数据,此时就需要将数据同步保存到Redis缓存,减少数据库压力。
缓存雪崩,缓存击穿,缓存穿透
缓存雪崩:同一时间缓存大面积过期,所有原本应该访问缓存的请求都去查询数据库了,数据库压力增大。
解决方法:1.锁(最常见的方式,单服务可使用线程锁,分布式微服务使用分布式锁)2.将缓存失效时间分散开来(避免大面积过期)。
缓存击穿:某个热点缓存过期,同一时刻大量请求直接去查询数据库,数据库压力增大。
解决方法:1.互斥锁(最常见的方式,单服务可使用线程锁,分布式微服务使用分布式锁)2.永不过期(把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期)。
缓存穿透:查询一条数据库不存在的数据(如id=-1),这样请求每次就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。高并发的情况下数据库压力会很大。
解决方法:1.过滤器,进行参数过滤校验 2.即使数据库不存在,我们也将这个空结果存入到缓存中,可以设置一个比较短的过期时间,这样第二次请求缓存就可以命中了。
总结:缓存雪崩:大面积过期。缓存击穿:热点缓存过期。缓存穿透:缓存未命中。针对缓存过期可以使用互斥锁和重构过期策略来改善,缓存未命中的问题可以通过过滤参数来拦截请求。
缓存预热,缓存更新,缓存降级
缓存预热:就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。
解决思路:
- 直接写个缓存刷新页面,上线时手工操作下;
- 数据量不大,可以在项目启动的时候自动进行加载;
- 定时刷新缓存;
缓存更新: 除了缓存服务器自带的缓存失效策略之外,我们还可以根据具体的业务需求进行自定义的缓存淘汰。
解决思路:
- 定时去清理过期的缓存;
- 当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
缓存降级: 服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据库查询,而是直接返回默认值给用户。

















 5555
5555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









