




 本文深入探讨PySpark的基础原理和程序运行机制。PySpark利用Py4j在Python与Java之间建立Socket通信,使Python调用Java方法。在Spark集群中,PySpark的Python代码通过JVM转化为SparkContext,.Executor通过Task执行用户定义的Python函数,数据处理结果通过Socket通信返回。PySpark的性能损耗源于Python与JVM间的数据通信,适合中小规模数据的离线任务,大规模任务推荐使用原生Scala/Java。
本文深入探讨PySpark的基础原理和程序运行机制。PySpark利用Py4j在Python与Java之间建立Socket通信,使Python调用Java方法。在Spark集群中,PySpark的Python代码通过JVM转化为SparkContext,.Executor通过Task执行用户定义的Python函数,数据处理结果通过Socket通信返回。PySpark的性能损耗源于Python与JVM间的数据通信,适合中小规模数据的离线任务,大规模任务推荐使用原生Scala/Java。
一、基础原理
我们知道 spark 是用 scala 开发的,而 scala 又是基于 Java 语言开发的,那么 spark 的底层架构就是 Java 语言开发的。如果要使用 python 来进行与 java 之间通信转换,那必然需要通过 JVM 来转换。我们先看原理构建图:
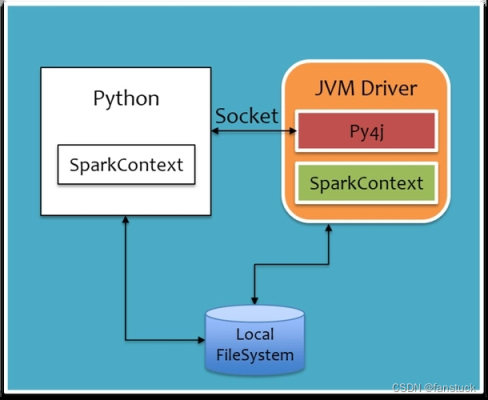
从图中我们发现在 python 环境中我们编写的程序将以 SparkContext 的形式存在,Pythpn 通过于 Py4j 建立 Socket 通信,通过 Py4j 实现在 Python 中调用 Java 的方法,将我们编写成 python 的 SpakrContext 对象通过 Py4j,最终在 JVM Driver 中实例化为 Scala 的 SparkContext。
那么我们再从 Spark 集群运行机制来看:
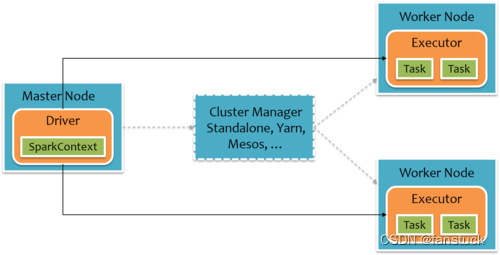
主节点运行 Spark 任务是通过 SparkContext 传递任务分发到各个从节点,标橙色的方框就为 JVM。通过 JVM 中间语言与其他从节点的 JVM 进行通信。之后 Executor 通信结束之后下发 Task 进行执行。
此时我们再把 python 在每个主从节点展示出来:
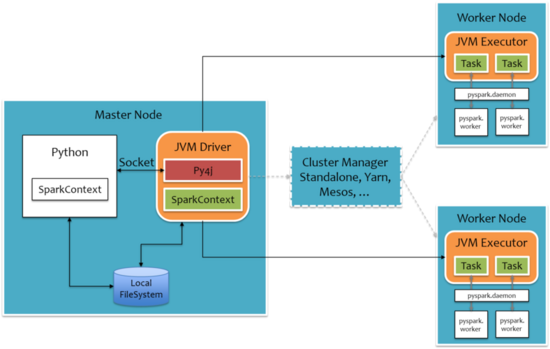
这样就一目了然了:主节点的 Python 通过 Py4j 通信传递 SparkContext,最后在 JVM Driver 上面生成 SparkCont
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









