




1 Kafka安装
1.1 压缩包安装
1.1.1 JDK环境安装
Kafka是依赖JDK环境的,所以需要事先安装好JDK
- 下载JDK安装包: Oracle JDK8下载
- SSH上传到想要安装的目录,比如 /opt.然后使用
tar -zxvf jdk-8u351-linux-x64.tar.gz命令解压

- 添加环境变量
vi /etc/profile,输入如下内容保存后,记得source /etc/profile刷新一下#java environment export JAVA_HOME=/opt/jdk1.8.0_351 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH - 输入
java -version命令,显示版本号即安装成功
1.1.2 Kafka安装
- 下载安装包,并解压到所需目录: kafka下载地址
- 根据如下文档操作即可: kafka中文文档–快速开始
1.2 Docker compose安装
- 事先安装docker,docker-compose服务
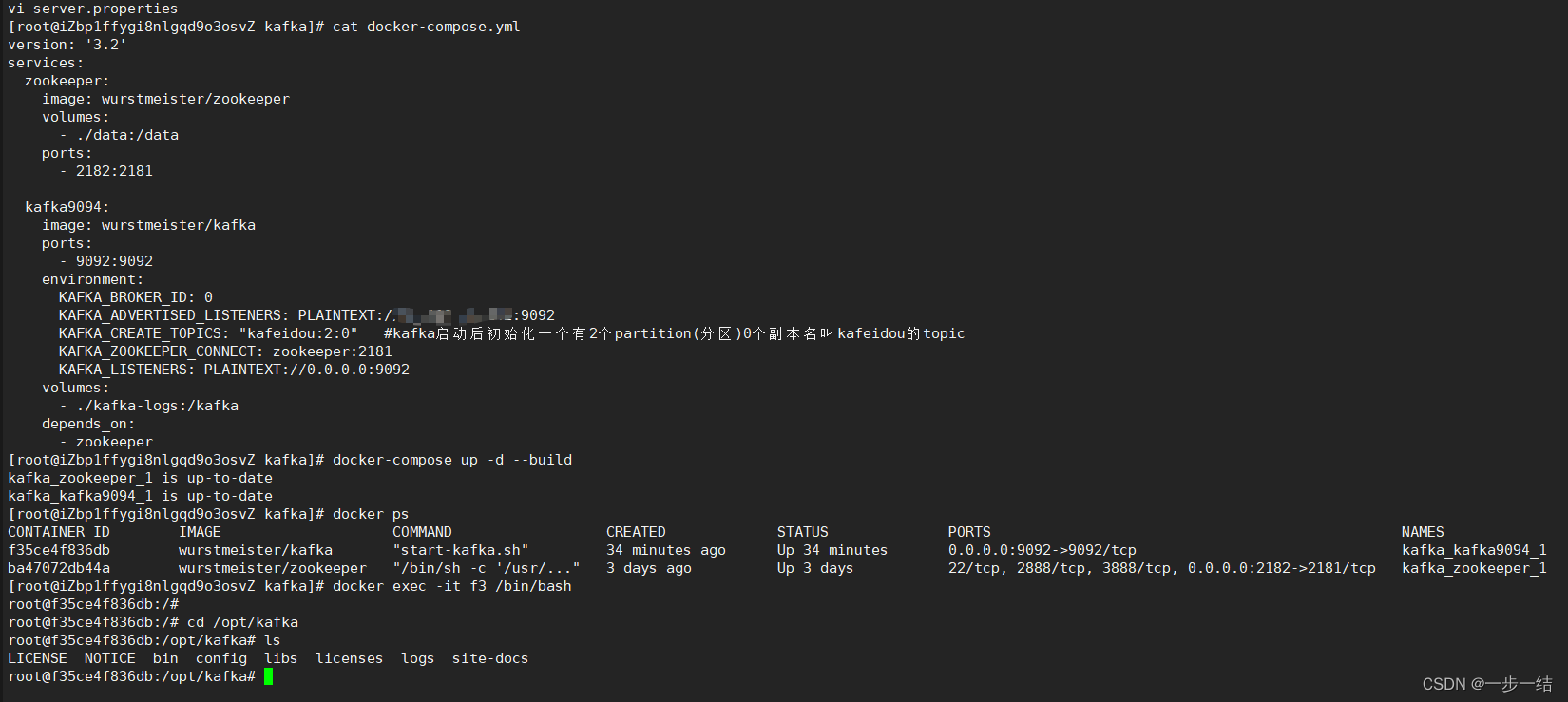
- 编辑docker-componse.yml配置文件
version: '3.2'
services:
zookeeper:
image: wurstmeister/zookeeper
volumes:
- ./data:/data
ports:
- 2182:2181
kafka9094:
image: wurstmeister/kafka
ports:
- 9092:9092
environment:
KAFKA_BROKER_ID: 0
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://47.118.83.142:9092
KAFKA_CREATE_TOPICS: "kafeidou:2:0" #kafka启动后初始化一个有2个partition(分区)0个副本名叫kafeidou的topic
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
volumes:
- ./kafka-logs:/kafka
depends_on:
- zookeeper
- 使用
docker-compose up -d --build启动服务 - 使用
docker exec -it kakfa /bin/bash进入docker容器,后续验证操作同安装包安装
如下提供命令实操截图
1.3 关于Kafka配置
kafka 配置一般在config/server.properties中,一般可能要修改的几个配置如下
# 集群-broker唯一标识,多个broker记得修改
broker.id=1
# 端口号
listeners=PLAINTEXT://0.0.0.0:9092
# 日志地址,多个broker记得修改
log.dir=/tmp/kafka-logs-1
# 对外暴露的地址,docker记得填宿主机地址
advertised.listeners=PLAINTEXT://xx:9092
如果linux操作没问题,但是外部连接不上kafka,检查
advertised.listeners配置
2. Kafka API
2.1 概述
Kafka常用的API可以分为5类,包括admin,producer,consumer,stream,connect
2.1.1 Admin
实际就包含了topic的增删查功能
2.2.2 Producer
发放方式
- 异步非阻塞发送
- 异步阻塞发送
- 异步回调发送
注意:
- Producer是线程安全的,使用多线程操作同一个producer是没问题的
- Producer内部是批量发送的,虽然看起来是一条一条发送,但其内部是按批次来发送的
2.2.3 Consumer
- consumer不是线程安全的,多线程消费会有两种处理
a. 每个线程都创建一个consumer,保证线程安全: 可以维护offset,相对更常用一点
b. 只创建一个consumer,将消息异步处理: 无法保证offset,但是性能好 - consumer组内的消费者数量最好是和partition数量一致,绝对不能比partition多
- 手动控制offset起始位置:
consumer.seek - 限流:
consumer.assign();consumer.pause();consumer.resume() - Rabalance
2.3.4 Stream
一般结合spark或者flink等大数据引擎一起用
source processor->processor->stream->processor-> sink processor
2.3.5 Connect
目前来说是比较鸡肋的,不看也罢.主要应用常见就是导入导出数据,比如从A数据源导入B数据源
2.2 实战
实战方面建议从SE API开始进行,如果直接从Springboot开始,容易陷入Spring框架谜团中,不够纯粹.当SE API熟悉后,再整合Springboot会更得心应手.
2.2.1 创建Maven项目
新建空白Maven项目,然后引入Kakfa Client依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>xyz.yq56</groupId>
<artifactId>kafka_se</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<artifactId>spring-boot-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.2.5.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
</dependencies>
</project>
2.2.2 Admin
创建和查询topic
public class AdminSample {
public static final String TOPIC_NAME = "yq_topic";
private static AdminClient client;
public static AdminClient adminClient() {
Properties props = new Properties();
props.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.103:9092");
props.setProperty(AdminClientConfig.RECEIVE_BUFFER_CONFIG, String.valueOf(104857600));
return AdminClient.create(props);
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
client = adminClient();
System.out.println(client);
createTopic();
listTopics();
}
public static void createTopic() {
short rs = 1;
NewTopic newTopic = new NewTopic(TOPIC_NAME, 1, rs);
CreateTopicsResult topics = client.createTopics(Collections.singletonList(newTopic));
System.out.println("topics:" + topics);
}
public static void listTopics() throws ExecutionException, InterruptedException {
ListTopicsResult topics = client.listTopics();
Set<String> names = topics.names().get();
names.forEach(System.out::println);
}
}
3 Kafka面试题
3.1 Kafka如何保证有序性
- Kafka的特性只支持单Partition有序(不建议)
- key+offset保证业务有序
3.2 Kafka为什么吞吐量大
- 日志顺序读写和快速检索
- 零拷贝: sendfile
- Partition机制
- 批量发送接收和数据压缩机制
4 Kafka原理
4.1 日志
- 日志以Partition为单位保存
- 目录格式: Topic+数字
- 文件格式: 日志条目 序列
- 消息: 4字节头+N字节消息(消息长度,版本号 ,CRC校验码,具体消息)
4.1.1 日志分段
- 每个partition日志分成n个大小相等的segment
- 每个segment中消息数量不一定相等
- 每个partition只支持顺序读写
4.1.2 Segment存储结构
- Partiton将消息添加到最后一个segment中
- Segment达到一定阈值才会flush到磁盘
- Segment分为两部分: index和log
4.1.3 日志读操作
- 查找segment
- 全局offset,计算segment的offset
- 通过index的offset查找具体数据
4.1.4 日志写操作
- 串行追加消息到文件最后
- 文件达到阈值,则滚动到新文件中
4.2 零拷贝
sendfile

















 1895
1895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









