



从这里我们将正式进入机器学习的世界
一、线性回归:
在前面的学习中,我们知道对于监督学习我们有回归和分类,这两大类别。回归在机器学习中是指建立因变量与自变量之间关系的模型,并通过这种关系进行预测和分析的过程。回归分析可以分为线性回归和非线性回归两大类。
1.线性回归的概念:
是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维度的超平面,使得预测值与真实值之间的误差最小化。
2.线性回归的符号约定:
m:代表训练集之中的样本数目。
n:代表特征的数目。
x:代表特征变量/输入变量。
y:代表目标变量/输出变量。
(x,y):代表训练集的样本。
(xi,yi):代表训练集的第i个样本;其中xi是特征矩阵的第i行,是一个向量我们默认为列向量。而且这里的i我们放在上标的位置,我们还添加了一个下标j:xij这里表示特征矩阵第i行的第j个特征。
h:代表学习算法的解决方案或者函数。
3.损失函数和代价函数的区别:
损失函数(Loss Function)是定义在单个样本上的,用于计算模型对单个样本预测结果的误差。它衡量了模型在单个样本上的错误程度。常见的损失函数包括均方误差、交叉熵等。对于其用途:损失函数通常用于指导每个训练样例的学习过程。在每次迭代时,通过反向传播算法计算梯度并更新模型权重,以最小化损失函数
代价函数(Cost Function)是定义在整个训练集上的,是所有样本损失函数的平均值。换句话说,代价函数是全局损失,用于评估模型在整个训练集上的性能。对于其用途:代价函数通常在模型训练结束后用于评估整个模型的表现。它帮助优化算法找到最佳参数组合,以期望模型在未见过的数据上也能表现出良好的泛化能力。对于代价函数而言
4.线性回归的最小二乘法求解:
对于线性回归模型: y = β₀ + β₁x₁ + β₂x₂ + ... + βₙxₙ + ε而言:我们需要找到一组(β₀,β₁,β₂,...,βₙ)使得代价函数的值最小:
多元线性回归中,特征是多维的,可以使用向量形式表示预测函数,并引入矩阵来简化计算过程。损失函数可以用矩阵表示为,其中X是样本矩阵,y是目标变量向量,w是参数向量。
https://zhuanlan.zhihu.com/p/48255611
这里引用这篇文章的计算过程。
5.梯度下降法:
机器学习中的梯度下降是一种优化算法,用于最小化损失函数,从而训练模型参数。
主要原理:我们首先要知道几个概念:预测函数、代价函数。
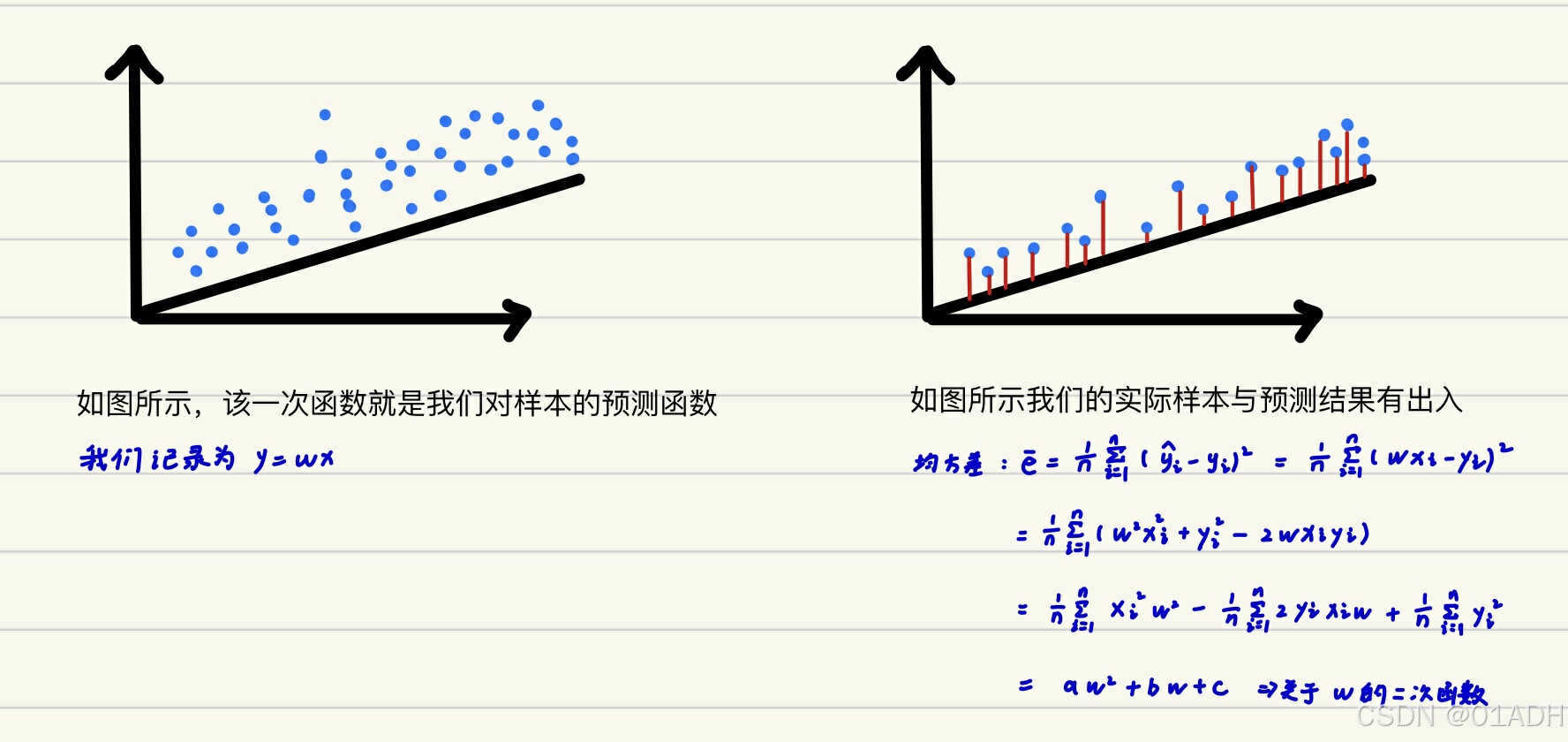
首先我们随便选择一条直线y=wx以后,我们再计算所有样本点的损失函数,随后再计算代价函数,并且整理我们会发现该代价函数是有关评估系数w的一个二次函数,而且开口向上,说明他有极小值,此时对应的w正是我们需要的理想的评估系数。
此时我们要从当前的wi开始移动以获取最理想的取值w',首先我们需要确定移动的方向。

接下来我们需要确定移动的步幅:这时候我们引入概念——学习率 :
我们移动的过程用这样一个代数式表示:新w=旧w-斜率×学习率。

这是我们考虑的最简单的情况,在实际问题之中会有许多特征变量取去影响我们的目的变量,此时我们的预测函数,就不会是简单的可以在平面直角坐标系的函数了,相应的代价函数也会复杂。随着特征变量的增加,我们会得到多元函数的预测函数,这将十分复杂,无法直观的再坐标系之中表现出来,但是梯度下降法仍然适用
下面介绍一些常见的梯度下降方法:
批量梯度下降(BGD)
批量梯度下降法是最原始的形式,它在更新每一参数时都使用所有的样本来进行更新
特点:全局最优解;易于并行实现,当样本数目很多时,训练过程会很慢。
随机梯度下降(SGD)
随机梯度下降法每次迭代使用一个样本来对参数进行更新。
特点:训练速度快,准确度下降,并不是全局最优;不易于并行实现
小批量梯度下降(MBGD)
小批量梯度下降法在每次更新参数时使用b个样本(b一般为10)
特点:可能不会收敛也可能不会在很小的范围内波动,训练过程比较快,而且也要保证最终参数训练的准确率。
6.正则化:
首先介绍一下过拟合与欠拟合:
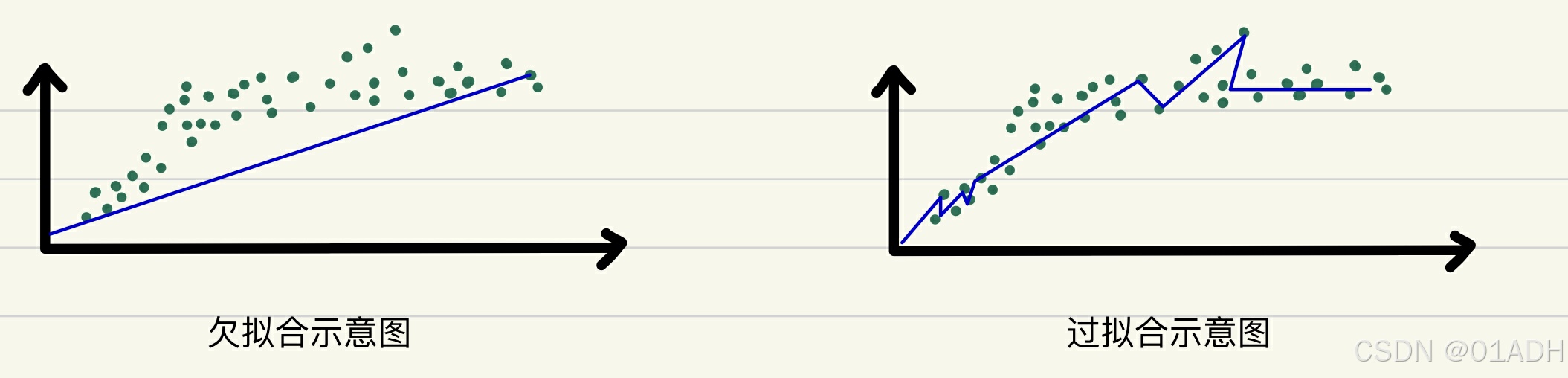
欠拟合:是指模型在训练数据和新数据上都表现不佳的现象。这通常是因为模型过于简单,无法捕捉到数据中的复杂模式。
过拟合:是指模型在训练数据上表现优异,但在新数据上表现较差的现象。这通常是因为模型过于复杂,以至于它不仅学习了训练数据中的真实模式,还学习了数据的噪声和异常值。
L1正则化:L1正则化是指在损失函数中添加一个等于所有权重绝对值之和的惩罚项,这个惩罚项乘以一个正则化参数λ。
L2正则化:通过在损失函数中增加权重参数的平方和作为惩罚项来实现。这个惩罚项乘以一个正则化参数λ。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









