




一.理解Flink的乱序问题
理解Flink的乱序问题,的先理解Flink的时间语义.
Flink有3中时间语义:
Event Time:事件创建的时间
Ingestion Time:数据进入Flink的时间,后续版本好像这个时间语义.也就不讨论了.
Processing Time:执行操作算子的本地系统时间,与机器相关.(Event Time的使用,必须配合WaterMark)
Flink的时间语义的使用,需要搭配window机制.没有window开窗也就不存在乱序问题.反正所有数据最终都会被处理. 只有开窗了,窗口关闭了,有的数据没进来才会导致数据丢失,进而导致计算结果错误.
那么思考一个问题:什么时间语义才会导致乱序呢?
答:Event Time.
解释:ProcessingTime以算子处理时间为准,就不存在乱序问题.
但是Event Time以数据产生时间为准.当 Flink 以 Event Time 模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子.由于网络、分布式等原因,会导致乱序数据的产生.乱序数据会让窗口计算不准确
总结:Flink的乱序,需要基于Event Time 并且 后续有开窗操作
二.Flink的乱序问题处理
1.WaterMark
1.1WaterMark的理解
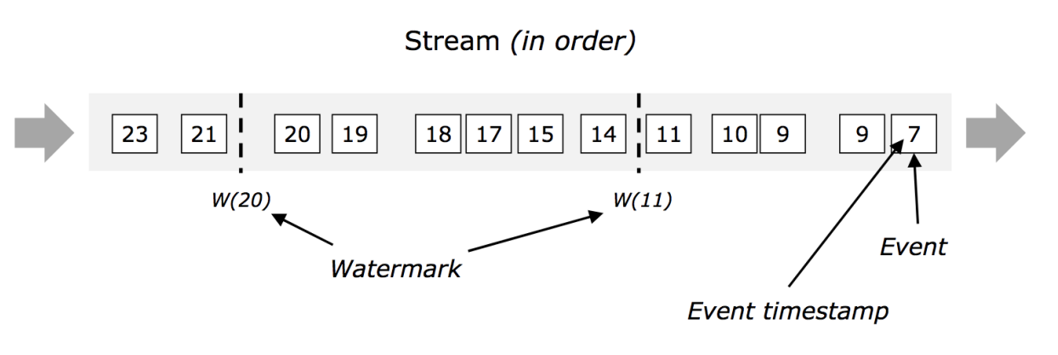
1.在事件时间体系中, 时间的进度依赖于数据本身, 和任何设备的时间无关. 事件时间程序必须制定如何产生Event Time Watermarks(水印) . 在事件时间体系中, 水印是表示时间进度的标志(作用就相当于现实时间的时钟).
2.数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,window 的执行也是由 Watermark 触发的(但是这种事理想情况,所谓的理想情况就是设置乱序程度刚好满足最大乱序时间差)
3.是一个特殊的时间戳,生成之后随着流的流动而向后传递。
4.单调递增的(时间不能倒退)。
==我的理解:==WaterMark主要用来控制窗口的关闭,和计算时间. 至于数据应该进入到哪个窗口里边还是基于数据自身的Event Time
1.2WaterMark的分类
有序流中的WaterMark
事件是有序的(生成数据的时间和被处理的时间顺序是一致的), watermark是流中一个简单的周期性的标记。
有序场景:
1、 底层调用的也是乱序的Watermark生成器,只是乱序程度传了一个0ms。
2、 Watermark = maxTimestamp – outOfOrdernessMills – 1ms
= maxTimestamp – 0ms – 1ms
=>事件时间 – 1ms
//TODO 设置WaterMark 通常在开始时候设置
/**
* 参入填入 生成WaterMark的策略:有两个:单调增长和固定延迟的策略
*/
SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = map.assignTimestampsAndWatermarks(
WatermarkStrategy
//有序流WaterMark
.<WaterSensor>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
//指定哪个字段作为事件时间字段
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
return element.getTs() * 1000;
}
})
);
// waterSensorSingleOutputStreamOperator.print();
//TODO 将相同key聚合到一起
KeyedStream<WaterSensor, String> keyedStream = waterSensorSingleOutputStreamOperator.keyBy(r -> r.getId());
//TODO 开启一个基于事件时间的滚动窗口
WindowedStream<WaterSensor, String, TimeWindow> window = keyedStream.window(TumblingEventTimeW 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









