







 本文详细解析了MongoDB服务端处理删除记录请求的过程,包括消息解析、条件匹配、记录删除及索引更新等关键步骤。
本文详细解析了MongoDB服务端处理删除记录请求的过程,包括消息解析、条件匹配、记录删除及索引更新等关键步骤。
在之前的一篇文章 中,介绍了assembleResponse函数(位于instance.cpp第224行),它会根据op操作枚举类型来调用相应的crud操作,枚举类型定义如下:
- enum Operations {
- opReply = 1, /* reply. responseTo is set. */
- dbMsg = 1000, /* generic msg command followed by a string */
- dbUpdate = 2001, /* update object */
- dbInsert = 2002,
- //dbGetByOID = 2003,
- dbQuery = 2004,
- dbGetMore = 2005,
- dbDelete = 2006,
- dbKillCursors = 2007
- };
可以看到dbDelete = 2002 为删除操作枚举值。当客户端将要删除的记录(或条件的document)发到服务端之后,mongodb通过消息封装方式将数据包中的字节流解析转成 message类型,并进一步转换成dbmessage之后,mongodb就会根据消息类型进行判断,以决定接下来执行的操作),下面我们看一下 assembleResponse在确定是删除操作时调用的方法,如下:
- assembleResponse( Message &m, DbResponse &dbresponse, const SockAddr &client ) {
- .....
- try {
- if ( op == dbInsert ) { //添加记录操作
- receivedInsert(m, currentOp);
- }
- else if ( op == dbUpdate ) { //更新记录
- receivedUpdate(m, currentOp);
- }
- else if ( op == dbDelete ) { //删除记录
- receivedDelete(m, currentOp);
- }
- else if ( op == dbKillCursors ) { //删除Cursors(游标)对象
- currentOp.ensureStarted();
- logThreshold = 10;
- ss << "killcursors ";
- receivedKillCursors(m);
- }
- else {
- mongo::log() << " operation isn't supported: " << op << endl;
- currentOp.done();
- log = true;
- }
- }
- .....
- }
- }
从上面代码可以看出,系统在确定dbDelete操作时,调用了receivedDelete()方法(位于instance.cpp文件第323行),下面是该方法的定义:
- void receivedDelete(Message & m, CurOp & op) {
- DbMessage d(m); // 将Message消息转换成数据库消息格式
- const char * ns = d.getns(); // 获取相应名空间信息
- assert( * ns);
- uassert( 10056 , " not master " , isMasterNs( ns ) ); // 因为CUD操作在主库中操作,所以这里断言名空间包含的db信息中是不是主库,即"master"
- op.debug().str <<
- ns << ' ' ;
- // 获取"删除消息"结构体中的flags 标识位,如设置了该位,则仅删除查找到的第一条记录(document),否则删除所有匹配记录.
- // 关于消息结构体,参见我的这篇文章: http://www.cnblogs.com/daizhj/archive/2011/04/02/2003335.html
- int flags = d.pullInt(); //
- bool justOne = flags & RemoveOption_JustOne;
- bool broadcast = flags & RemoveOption_Broadcast;
- assert( d.moreJSObjs() );
- BSONObj pattern = d.nextJsObj(); // 获取"删除消息"结构体中的selector(也就是要删数据条件where)
- {
- string s = pattern.toString();
- op.debug().str << " query: " << s;
- op.setQuery(pattern);
- }
- writelock lk(ns);
- // 如果不更新所有节点(sharding)且当前物理结点是shard 状态时
- if ( ! broadcast & handlePossibleShardedMessage( m , 0 ) )
- return ;
- // if this ever moves to outside of lock, need to adjust check Client::Context::_finishInit
- Client::Context ctx(ns);
- long long n = deleteObjects(ns, pattern, justOne, true ); // 删除对象信息
- lastError.getSafe() -> recordDelete( n );
- }
上面方法主要是对消息中的flag信息进行解析,以获取消息中的删除条件等信息,并最终调用 deleteObjects方法,该方法位于query.cpp文件中,如下:
- // query.cpp文件 128行
- /* ns: 要删除的表集合(namespace, e.g. <database>.<collection>)
- pattern: 删除条件,相当于 "where" 字语(clause / criteria)
- justOne: 是否仅删除第一个匹配对象信息
- god: 是否允许访问系统名空间(system namespaces)
- */
- long long deleteObjects( const char * ns, BSONObj pattern, bool justOneOrig, bool logop, bool god, RemoveSaver * rs ) {
- if ( ! god ) { // 如果不能访问system空间,但却删除该空间信息时
- if ( strstr(ns, " .system. " ) ) {
- /* note a delete from system.indexes would corrupt the db. if done here, as there are pointers into those objects in NamespaceDetails.
- */
- uassert( 12050 , " cannot delete from system namespace " , legalClientSystemNS( ns , true ) );
- }
- if ( strchr( ns , ' $ ' ) ) {
- log() << " cannot delete from collection with reserved $ in name: " << ns << endl;
- uassert( 10100 , " cannot delete from collection with reserved $ in name " , strchr(ns, ' $ ' ) == 0 );
- }
- }
- NamespaceDetails * d = nsdetails( ns ); // 获取名空间详细信息
- if ( ! d )
- return 0 ;
- uassert( 10101 , " can't remove from a capped collection " , ! d -> capped ); // 确保当前collection不是capped类型(该类型集合会自动删除旧数据)
- long long nDeleted = 0 ;
- int best = 0 ;
- shared_ptr < MultiCursor::CursorOp > opPtr( new DeleteOp( justOneOrig, best ) ); // 构造“删除操作”实例对象并用其构造游标操作(符)实例
- shared_ptr < MultiCursor > creal( new MultiCursor( ns, pattern, BSONObj(), opPtr, ! god ) ); // 构造MultiCursor查询游标(参见构造方法中的 nextClause()语句)
- if ( ! creal -> ok() ) // 如果查询游标指向地址是否正常(主要判断是否null),因为系统会根据上面游标初始信息决定使用什么样的方式进行信息查询(比如是否使用B树索引等)
- return nDeleted;
- shared_ptr < Cursor > cPtr = creal;
- auto_ptr < ClientCursor > cc( new ClientCursor( QueryOption_NoCursorTimeout, cPtr, ns) ); // 将游标封装以便下面遍历使用
- cc -> setDoingDeletes( true ); // 设置_doingDeletes(删除中)标志
- CursorId id = cc -> cursorid();
- bool justOne = justOneOrig;
- bool canYield = ! god && ! creal -> matcher() -> docMatcher().atomic();
- do {
- if ( canYield && ! cc -> yieldSometimes() ) { // 查看是否已到期(每个cc都会有一个读写操作时间,该值取决子获取读写锁时系统分配的时间,详见client.cpp 文件中的方法 int Client::recommendedYieldMicros( int * writers , int * readers ) {)
- cc.release(); // 时间已到则释放该对象(意味着已在别的地方被删除?)
- // TODO should we assert or something?
- break ;
- }
- if ( ! cc -> ok() ) {
- break ; // if we yielded, could have hit the end
- }
- // this way we can avoid calling updateLocation() every time (expensive)
- // as well as some other nuances handled
- cc -> setDoingDeletes( true );
- DiskLoc rloc = cc -> currLoc(); // 游标当前所指向的记录所在地址
- BSONObj key = cc -> currKey(); // 游标当前所指向的记录的key
- // NOTE Calling advance() may change the matcher, so it's important
- // to try to match first.
- bool match = creal -> matcher() -> matches( key , rloc ); // 将当前游标指向的记录与游标中的where条件进行比较
- if ( ! cc -> advance() ) // 游标移到下一个记录位置
- justOne = true ;
- if ( ! match )
- continue ;
- assert( ! cc -> c() -> getsetdup(rloc) ); // 不允许复本, 因为在多键值索引中可能会返回复本
- if ( ! justOne ) {
- /* NOTE: this is SLOW. this is not good, noteLocation() was designed to be called across getMore
- blocks. here we might call millions of times which would be bad.
- */
- cc -> c() -> noteLocation(); // 记录当前游标移动到的位置
- }
- if ( logop ) { // 是否保存操作日志
- BSONElement e;
- if ( BSONObj( rloc.rec() ).getObjectID( e ) ) {
- BSONObjBuilder b;
- b.append( e );
- bool replJustOne = true ;
- logOp( " d " , ns, b.done(), 0 , & replJustOne ); // d表示delete
- }
- else {
- problem() << " deleted object without id, not logging " << endl;
- }
- }
- if ( rs ) // 将删除记录的bson objects 信息保存到磁盘文件上
- rs -> goingToDelete( rloc.obj() /* cc->c->current() */ );
- theDataFileMgr.deleteRecord(ns, rloc.rec(), rloc); // 删除查询匹配到的记录
- nDeleted ++ ; // 累计删除信息数
- if ( justOne ) {
- break ;
- }
- cc -> c() -> checkLocation(); // 因为删除完记录好,会造成缓存中相关索引信息过期,用该方法能确保索引有效
- if ( ! god )
- getDur().commitIfNeeded();
- if ( debug && god && nDeleted == 100 ) // 删除100条信息之后,显示内存使用预警信息
- log() << " warning high number of deletes with god=true which could use significant memory " << endl;
- }
- while ( cc -> ok() );
- if ( cc. get () && ClientCursor::find( id , false ) == 0 ) { // 再次在btree bucket中查找,如没有找到,表示记录已全部被删除
- cc.release();
- }
- return nDeleted; // 返回已删除的记录数
- }
上面的代码主要执行构造查询游标,并将游标指向地址的记录取出来与查询条件进行匹配,如果匹配命中,则进行删除。这里考虑到如果记录在内存时,如果删除 记录后,内存中的b树结构会有影响,所以在删除记录前/后分别执行noteLocation/checkLocation方法以校正 查询cursor的当前位置。因为这里是一个while循环,它会找到所有满足条件的记录,依次删除它们。因为这里使用了MultiCursor,该游标在我看来就是一个复合游标 ,它不仅包括了cursor 中所有功能,还支持or条件操作。而有关游标的构造和继承实现体系,mongodb做的有些复杂,很难几句说清,我会在本系列后面另用篇幅进行说明,敬请期待 。
注意上面代码段中的这行代码:
- theDataFileMgr.deleteRecord(ns, rloc.rec(), rloc); // 删除查询匹配到的记录
- 该行代码执行了最终的删除记录操作,其定义如下:
- // pdfile.cpp文件 912行
- // 删除查询匹配查询到的记录
- void DataFileMgr::deleteRecord( const char * ns, Record * todelete, const DiskLoc & dl, bool cappedOK, bool noWarn) {
- dassert( todelete == dl.rec() ); // debug断言,检查要删除的Record信息与传入的dl是否一致(避免函数调用过程中被修改?)
- NamespaceDetails * d = nsdetails(ns);
- if ( d -> capped && ! cappedOK ) { // 如果是capped collection类型,则不删除
- out () << " failing remove on a capped ns " << ns << endl;
- uassert( 10089 , " can't remove from a capped collection " , 0 );
- return ;
- }
- // 如果还有别的游标指向当前dl(并发情况下),则提升它们
- ClientCursor::aboutToDelete(dl);
- // 将要删除的记录信息从索引b村中移除
- unindexRecord(d, todelete, dl, noWarn);
- // 删除指定记录信息
- _deleteRecord(d, ns, todelete, dl);
- NamespaceDetailsTransient::get_w( ns ).notifyOfWriteOp();
- }
上面删除记录方法deleteRecord中,执行的删除顺序与我之前写的那篇插入记录方式正好相反(那篇文章中是选在内存中分配记录然后将地址放到b树 中),这里是先将要删除记录的索引信息删除,然后再删除指定记录(更新内存中的记录信息而不是真的删除,稍后会进行解释)。
首先我们先看一下上面代码段的unindexRecord方法:
- // pdfile.cpp文件 845行
- /* 在所有索引中去掉当前记录信息中的相关索引键(包括多键值索用)信息 */
- static void unindexRecord(NamespaceDetails * d, Record * todelete, const DiskLoc & dl, bool noWarn = false ) {
- BSONObj obj(todelete);
- int n = d -> nIndexes;
- for ( int i = 0 ; i < n; i ++ )
- _unindexRecord(d -> idx(i), obj, dl, ! noWarn); // 操作见下面代码段
- if ( d -> indexBuildInProgress ) { // 对后台正在创建的索引进行_unindexRecord操作
- // always pass nowarn here, as this one may be missing for valid reasons as we are concurrently building it
- _unindexRecord(d -> idx(n), obj, dl, false ); // 操作见下面代码段
- }
- }
- // pdfile.cpp文件 815行
- /* unindex all keys in index for this record. */
- static void _unindexRecord(IndexDetails & id, BSONObj & obj, const DiskLoc & dl, bool logMissing = true ) {
- BSONObjSetDefaultOrder keys;
- id.getKeysFromObject(obj, keys); // 通过记录获取键值信息
- for ( BSONObjSetDefaultOrder::iterator i = keys.begin(); i != keys.end(); i ++ ) {
- BSONObj j = * i;
- if ( otherTraceLevel >= 5 ) { // otherTraceLevel为外部变量,定义在query.cpp中,目前作用不清楚
- out () << " _unindexRecord() " << obj.toString();
- out () << " /n unindex: " << j.toString() << endl;
- }
- nUnindexes ++ ; // 累加索引数
- bool ok = false ;
- try {
- ok = id.head.btree() -> unindex(id.head, id, j, dl); // 在btree bucket中删除记录的索引信息
- }
- catch (AssertionException & e) {
- problem() << " Assertion failure: _unindex failed " << id.indexNamespace() << endl;
- out () << " Assertion failure: _unindex failed: " << e.what() << ' /n ' ;
- out () << " obj: " << obj.toString() << ' /n ' ;
- out () << " key: " << j.toString() << ' /n ' ;
- out () << " dl: " << dl.toString() << endl;
- sayDbContext();
- }
- if ( ! ok && logMissing ) {
- out () << " unindex failed (key too big?) " << id.indexNamespace() << ' /n ' ;
- }
- }
- }
上面代码主要是把要删除的记录的B树键值信息取出,然后通过循环(可能存在多键索引,具体参见我之前插入记录那篇文章中B树索引构造的相关内容)删除相应B树索引信息,下面代码段就是在B树中查找(locate)并最终删除(delKeyAtPos)的逻辑:
- // btree.cpp文件 1116行
- /* 从索引中移除键值 */
- bool BtreeBucket::unindex( const DiskLoc thisLoc, IndexDetails & id, const BSONObj & key, const DiskLoc recordLoc ) const {
- if ( key.objsize() > KeyMax ) { // 判断键值是否大于限制
- OCCASIONALLY problem() << " unindex: key too large to index, skipping " << id.indexNamespace() << /* ' ' << key.toString() << */ endl;
- return false ;
- }
- int pos;
- bool found;
- DiskLoc loc = locate(id, thisLoc, key, Ordering::make(id.keyPattern()), pos, found, recordLoc, 1 ); // 从btree bucket中查找指定记录并获得位置信息(pos)
- if ( found ) {
- loc.btreemod() -> delKeyAtPos(loc, id, pos, Ordering::make(id.keyPattern())); // 删除指定位置的记录信息
- return true ;
- }
- return false ;
- }
在删除b树索引之后,接着就是“删除内存(或磁盘,因为mmap机制)中的记录”了,也就是之前DataFileMgr::deleteRecord()方法的下面代码:
- _deleteRecord(d, ns, todelete, dl)
其定义如下:
- //pdfile.cpp文件 859行
- /* deletes a record, just the pdfile portion -- no index cleanup, no cursor cleanup, etc.
- caller must check if capped
- */
- void DataFileMgr::_deleteRecord(NamespaceDetails *d, const char *ns, Record *todelete, const DiskLoc& dl) {
- /* remove ourself from the record next/prev chain */
- {
- if ( todelete->prevOfs != DiskLoc::NullOfs )//如果要删除记录的前面有信息则记录到日志中
- getDur().writingInt( todelete->getPrev(dl).rec()->nextOfs ) = todelete->nextOfs;
- if ( todelete->nextOfs != DiskLoc::NullOfs )//如果要删除记录的前面有信息则记录到日志中
- getDur().writingInt( todelete->getNext(dl).rec()->prevOfs ) = todelete->prevOfs;
- }
- //extents是一个数据文件区域,该区域有所有记录(records)均属于同一个名空间namespace
- /* remove ourself from extent pointers */
- {
- Extent *e = getDur().writing( todelete->myExtent(dl) );
- if ( e->firstRecord == dl ) {//如果要删除记录为该extents区域第一条记录时
- if ( todelete->nextOfs == DiskLoc::NullOfs )//且为唯一记录时
- e->firstRecord.Null();//则该空间第一元素为空
- else//将当前空间第一条(有效)记录后移一位
- e->firstRecord.set(dl.a(), todelete->nextOfs);
- }
- if ( e->lastRecord == dl ) {//如果要删除记录为该extents区域最后一条记录时
- if ( todelete->prevOfs == DiskLoc::NullOfs )//如果要删除记录的前一条信息位置为空时
- e->lastRecord.Null();//该空间最后一条记录清空
- else //设置该空间最后一条(有效)记录位置前移一位
- e->lastRecord.set(dl.a(), todelete->prevOfs);
- }
- }
- /* 添加到释放列表中 */
- {
- {//更新空间统计信息
- NamespaceDetails::Stats *s = getDur().writing(&d->stats);
- s->datasize -= todelete->netLength();
- s->nrecords--;
- }
- if ( strstr(ns, ".system.indexes") ) {//如果为索引空间,则把要删除记录在内存中的信息标识为0
- /* temp: if in system.indexes, don't reuse, and zero out: we want to be
- careful until validated more, as IndexDetails has pointers
- to this disk location. so an incorrectly done remove would cause
- a lot of problems.
- */
- memset(getDur().writingPtr(todelete, todelete->lengthWithHeaders), 0, todelete->lengthWithHeaders);
- }
- else {
- DEV {
- unsigned long long *p = (unsigned long long *) todelete->data;
- *getDur().writing(p) = 0;
- //DEV memset(todelete->data, 0, todelete->netLength()); // attempt to notice invalid reuse.
- }
- d->addDeletedRec((DeletedRecord*)todelete, dl);//向当前空间的“要删除记录链表”中添加当前要删除的记录信息
- }
- }
- }
这里有一个数据结构要先解析一下,因为mongodb在删除记录时并不是真把记录从内存中remove出来,而是将该删除记录数据置空(写0或特殊数字加 以标识)同时将该记录所在地址放到一个list列表中,也就是上面代码注释中所说的“释放列表”,这样做的好就是就是如果有用户要执行插入记录操作 时,mongodb会首先从该“释放列表”中获取size合适的“已删除记录”地址返回,这种废物利用 的 方法会提升性能(避免了malloc内存操作),同时mongodb也使用了bucket size数组来定义多个大小size不同的列表,用于将要删除的记录根据其size大小放到合适的“释放列表”中(deletedList),有关该 deletedList内容,详见namespace.h文件中的注释内容。
上面代码中如果记录的ns 在索引中则进行使用memset方法重置该记录数据,否则才执行将记录添加到“释放列表”操作,如下:
- void NamespaceDetails::addDeletedRec(DeletedRecord * d, DiskLoc dloc) {
- BOOST_STATIC_ASSERT( sizeof (NamespaceDetails::Extra) <= sizeof (NamespaceDetails) );
- {
- Record * r = (Record * ) getDur().writingPtr(d, sizeof (Record));
- d = & r -> asDeleted(); // 转换成DeletedRecord类型
- // 防止引用已删除的记录
- (unsigned & ) (r -> data) = 0xeeeeeeee ; // 修改要删除记录的数据信息
- }
- DEBUGGING log() << " TEMP: add deleted rec " << dloc.toString() << ' ' << hex << d -> extentOfs << endl;
- if ( capped ) { // 如果是cap集合方式,则会将记录放到该集全中
- if ( ! cappedLastDelRecLastExtent().isValid() ) {
- // Initial extent allocation. Insert at end.
- d -> nextDeleted = DiskLoc();
- if ( cappedListOfAllDeletedRecords().isNull() ) // deletedList[0] 是否为空,该值指向一个被删除的记录列表
- getDur().writingDiskLoc( cappedListOfAllDeletedRecords() ) = dloc; // 持久化该删除记录
- else {
- DiskLoc i = cappedListOfAllDeletedRecords(); // 如果为空向该列表中添加删除记录
- for (; ! i.drec() -> nextDeleted.isNull(); i = i.drec() -> nextDeleted ) // 遍历到最后一条记录
- ;
- i.drec() -> nextDeleted.writing() = dloc; // 将要删除的记录信息追加到链接尾部
- }
- }
- else {
- d -> nextDeleted = cappedFirstDeletedInCurExtent(); // 将deletedList[0]放到“删除记录”的后面
- getDur().writingDiskLoc( cappedFirstDeletedInCurExtent() ) = dloc; // 持久化deletedList[0]信息并将当前要删除的dloc绑定到deletedList[0]位置
- // always compact() after this so order doesn't matter
- }
- }
- else {
- int b = bucket(d -> lengthWithHeaders); // 获取一个适合存储当前数据尺寸大小的bucket的序号, 参见当前文件的bucketSizes设置
- DiskLoc & list = deletedList[b]; // 该值会与上面的cappedLastDelRecLastExtent(获取deletedList[0])相关联
- DiskLoc oldHead = list; // 取出第一条(head)记录
- getDur().writingDiskLoc(list) = dloc; // 将旧的记录信息数据持久化,并将list首记录绑定成当前要删除的dloc
- d -> nextDeleted = oldHead; // 将(第一条)旧记录绑定到当前已删除记录的nextDeleted上,形成一个链表
- }
- }
这样,就完成了将记录放到“释放列表”中的操作,上面的bucket中提供的大小款式 如下:
- // namespace.cpp 文件37行
- /* deleted lists -- linked lists of deleted records -- are placed in 'buckets' of various sizes
- so you can look for a deleterecord about the right size.
- */
- int bucketSizes[] = {
- 32 , 64 , 128 , 256 , 0x200 , 0x400 , 0x800 , 0x1000 , 0x2000 , 0x4000 ,
- 0x8000 , 0x10000 , 0x20000 , 0x40000 , 0x80000 , 0x100000 , 0x200000 ,
- 0x400000 , 0x800000
- };
最后,用一张时序图回顾一下删除记录时mongodb服务端代码的执行流程:
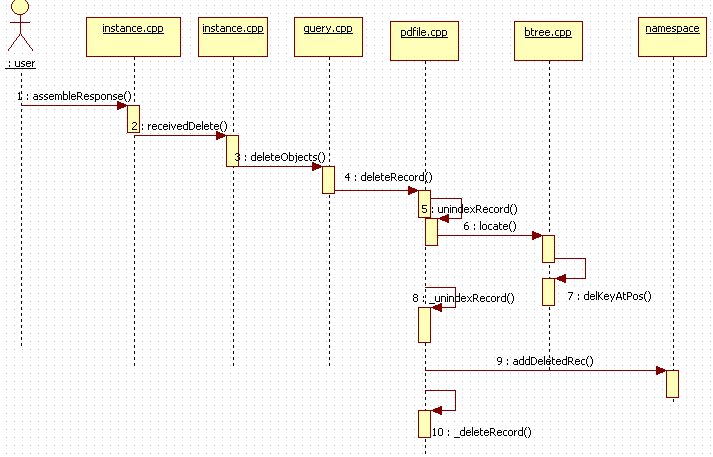
好了,今天的内容到这里就告一段落了,在接下来的文章中,将会介绍客户端发起Update操作时,Mongodb的执行流程和相应实现部分。
原文链接:http://www.cnblogs.com/daizhj/archive/2011/04/06/2006740.html
作者: daizhj, 代震军
微博: http://t.sina.com.cn/daizhj
Tags: mongodb,c++,source code

















 2114
2114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









