




 本文详细介绍了Elasticsearch的数据写入流程和读取流程。写入流程包括客户端发送请求、协调节点处理请求并同步数据到副本节点等步骤;读取流程则是通过docid查询并实现负载均衡。
本文详细介绍了Elasticsearch的数据写入流程和读取流程。写入流程包括客户端发送请求、协调节点处理请求并同步数据到副本节点等步骤;读取流程则是通过docid查询并实现负载均衡。
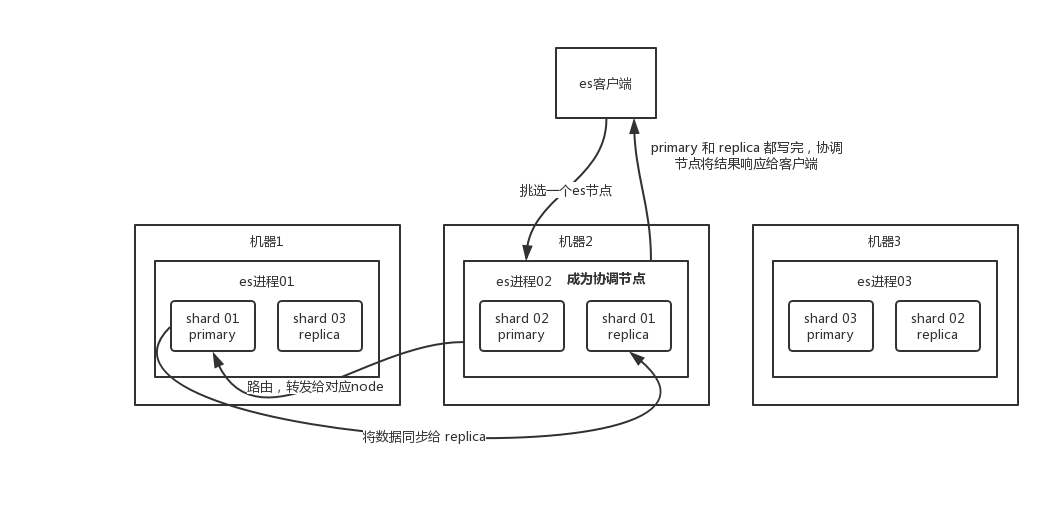
一、数据写流程
- 客户端选择一个 集群任意节点 发送请求过去,这个 node 就是 coordinating node(协调节点)。
- coordinating node(协调节点) 对 document 进行路由,将请求转发给对应的 node(有 primary shard)。
- 实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica node。
- coordinating node 如果发现 primary node 和所有 replica node 都搞定之后,就返回响应结果给客户端。
有一些可选的请求参数允许您影响这个过程,可能以数据安全为代价提升性能。这些选项很
少使用,因为 Elasticsearch 已经很快,但是为了完整起见, 请参考下面表格
| 参数 | 含义 |
|---|---|
| consistency | consistency,即一致性。在默认设置下,即使仅仅是在试图执行一个 写 操作之前,主分片都会要求 必须有 规定数量 ( quorum)(或者换种说法,也即必须要有大多数)的分片副本处于活跃可用状态,才会去执行 写 操作 其中分副本可以是主分片或者副本分片 。这是为了避免在发生网络分区故障( network partition )的时候进行 写 操作,进而导致数据不一致。 规定数量 即:int( (primary + number_of_replicas) / 2 ) + 1。 consistency参数的值可以设为 one (只要主分片状态 ok 就允许执行 写 操作) ),all (必须要主分片和所有副本分片的状态没问题才允许执行 写 操作) ), 或quorum 。默认值为 quorum , 即大多数的分片副本状态没问题就允许执行 写操作。注意,规定数量的计算公式中 number_of_replicas 指的是在索引设置中的设定副本分片数,而不是指当前处理活动状态的副本分片数。如果你的索引设置中指定了当前索引拥有三个副本分片,那规定数量的计算结果即:int( (primary + 3 replicas) / 2 ) + 1 = 3。如果此时你只启动两个节点,那么处于活跃状态的分片副本数量就达不到规定数量,也因此您将无法索引和删除任何文档。 |
| timeout | 如果没有足够的副本分片会发生什么?Elasticsearch 会等待,希望更多的分片出现。默认情况下,它最多等待 1 分钟。 如果你需要,你可以使用 timeout 参数使它更早终止: 100 100 毫秒, 30s 是 30 秒。 |
二、数据读流程
可以通过 doc id 来查询,会根据 doc id 进行 hash路由查询,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。- 客户端发送请求到任意一个 node,成为 coordinate node。
- coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
- 接收请求的 node 返回 document 给 coordinate node。
- coordinate node 返回 document 给客户端。

















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









