




 本文介绍了异常检测的概念及其在诈骗侦测、网络入侵检测和医疗领域的应用。异常检测不是简单的二元分类问题,分为有标签和无标签数据的处理方式。在有标签数据情况下,通过ROC AUC score来评估模型性能,避免因样本不均衡导致的错误评估。文章还探讨了使用Auto-encoder进行异常检测的方法。
本文介绍了异常检测的概念及其在诈骗侦测、网络入侵检测和医疗领域的应用。异常检测不是简单的二元分类问题,分为有标签和无标签数据的处理方式。在有标签数据情况下,通过ROC AUC score来评估模型性能,避免因样本不均衡导致的错误评估。文章还探讨了使用Auto-encoder进行异常检测的方法。
目录
异常检测概述
对于异常检测任务来说,我们希望能够通过现有的样本来训练一个函数,它能够从数据中学习到某些正常的特征,根据输入与现有样本之间是否足够相似,诊断出非正常的数据。
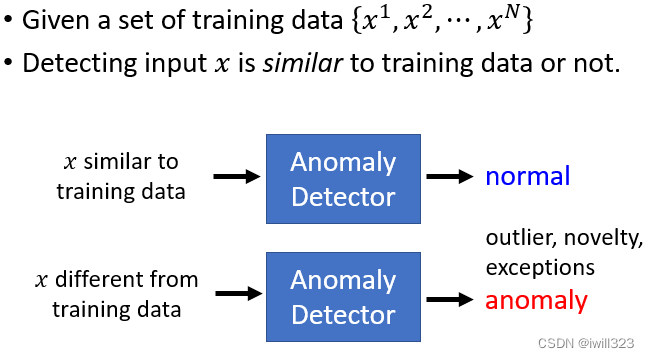
数据的正常和异常,取决于训练资料是什么,并没有特定谁是异常的,不是说异常就一定是不好的东西

通常来说,Anoamly Detector在不同的领域里面有不同名字,也被叫做Novelty Detection,Outlier Detection,Forgery Detection,Out-of-distribution Detection。
应用
异常检测应用广泛,实际应用场景有:诈骗侦测、网络入侵检测、癌细胞检测。
- 诈欺侦测(Fraud Detection)。训练数据是正常的刷卡行为,收集很多的交易记录,这些交易记录视为正常的交易行为,若今天有一笔新的交易记录,就可以用异常检测的技术来侦测这笔交易记录是否有盗刷的行为。(正常的交易金额比较小,频率比较低,若短时间内有非常多的高额消费,这可能是异常行为)
- 网络系统的入侵侦测,训练数据是正常连线。若有一个新的连线,你希望用Anoramly Detection让机器自动决定这个新的连线是否为攻击行为
- 医疗(癌细胞的侦测),训练数据是正常细胞。若给一个新的细胞,让机器自动决定这个细胞是否为癌细胞。

异常侦测不是一个单纯的二元分类问题
最简单的想法就是Binary Classification,它是收集一组正常的数据和一组异常的数据,将正常的资料标记为class 1,异常资料作为class 2,然后让机器一起训练一个二分类的分类器。
但实际上是很难按照这样的做法来实现的:
- 只要是非正常的都是异常,变化太大,没有办法将异常数据全部收集齐全,没有办法知道整个异常的数据(Class2)是咋样的,所以不应该将异常的数据视为一个类别。
- 对于正常的数据收集是比较简单的,但对于异常数据的收集通常是较难的
Anomaly Detection两种类别
第一类:给定一组训练数据,并且带有某种类型的label,使用这些数据先训练一个classifier。数据和label中并没有unknown,但是期望classifier有能力知道新给定的训练数据不在原本的训练数据中,会给新的训练数据贴上“unknown”的标签。也被称为Open-set Recognition。
第二类:所有的训练数据都是没有标签的,通过相似度来判断异常数据。这里面又分两种情况:
- clean: 所有数据都是正常数据
- polluted: 训练资料已经被混杂了一些异常的资料
数据存在标签
训练
给定一组Simpsons家族人物的数据,并且这些数据都是有label的,训练一个Simpsons的家族分类器,输入人物图片,输出名字。可以使用这个Classifier来做异常侦测,输入一个人物,判断其是否属于Simpsons家庭。

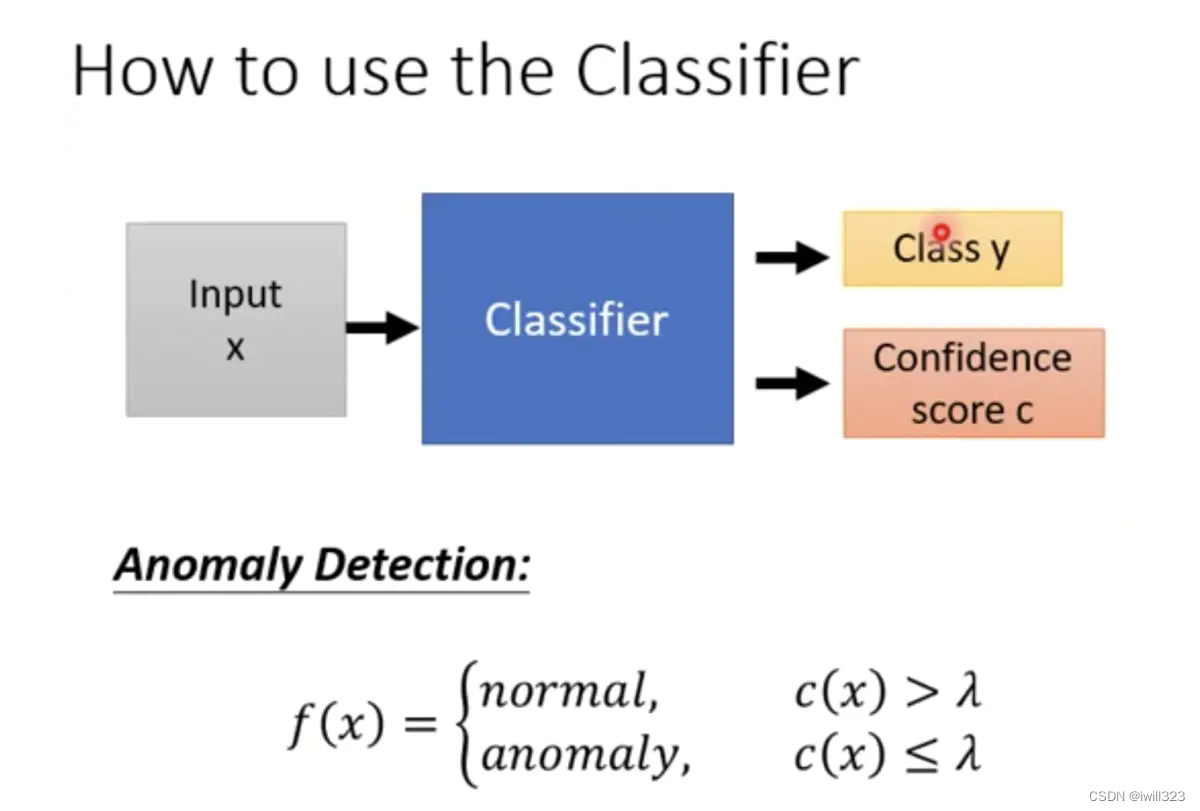
输入x 之后,分类model输出一个分布,将该分布的最大值作为信心分数c(x),和设置的阈值λ 进行比较,判断是否异常,小于则是异常,大于则是正常。
当输出分布比较集中,最高的分数比较高的时候就是正常;分布比较平均,最高分数比较低就是异常。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









