




https://www.pianshen.com/article/57371204499/
梯度回传过程中可能会梯度消失或者爆炸,为了避免这种情况,设置一个梯度剪裁。
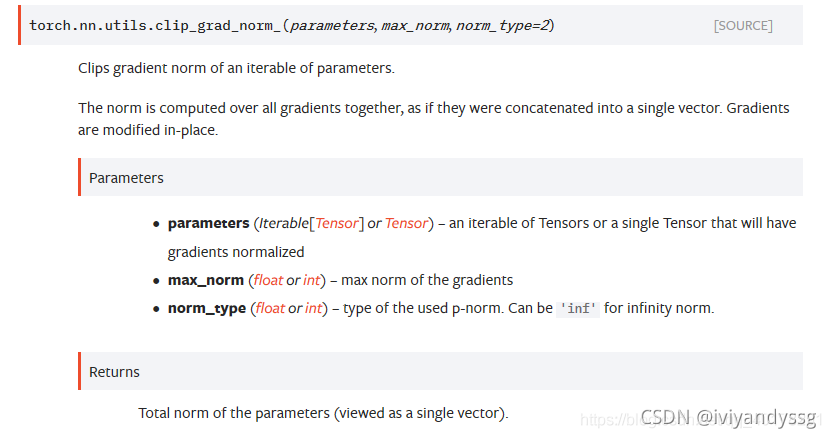
利用torch.nn.utils.clip_grad_norm_(parameters, max_norm, norm_type=2)完成。
参数1是模型参数,参数2是最大梯度范数,参数3是范数类型,默认为L2范数。
PS. 在train的过程中做这个,val和test过程中不做。
使用案例:

https://www.pianshen.com/article/57371204499/
梯度回传过程中可能会梯度消失或者爆炸,为了避免这种情况,设置一个梯度剪裁。
利用torch.nn.utils.clip_grad_norm_(parameters, max_norm, norm_type=2)完成。
参数1是模型参数,参数2是最大梯度范数,参数3是范数类型,默认为L2范数。
PS. 在train的过程中做这个,val和test过程中不做。
使用案例:
您可能感兴趣的与本文相关的镜像

PyTorch 2.5
PyTorch 是一个开源的 Python 机器学习库,基于 Torch 库,底层由 C++ 实现,应用于人工智能领域,如计算机视觉和自然语言处理
 1564
1445
1万+
1391
1564
1445
1万+
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























