






 本文详细介绍了线程池的工作原理,包括线程池的创建、核心参数解释、常见线程池类型及其适用场景。探讨了如何合理配置线程池以避免资源浪费,以及在高并发环境下如何使用有界队列防止内存溢出。
本文详细介绍了线程池的工作原理,包括线程池的创建、核心参数解释、常见线程池类型及其适用场景。探讨了如何合理配置线程池以避免资源浪费,以及在高并发环境下如何使用有界队列防止内存溢出。
-
创建对象仅仅在JVM的堆里为线程分配一块内存,而创建一个线程需要调用操作系统内核的API,然后操作系统要为线程分配一系列的资源。所以线程是一个重量级的对象,应该避免频繁的创建和销毁。
-
线程池是一种生产者-消费者模式
ThreadPoolExecutor
ThreadPoolExecutor的构造函数比较复杂,最完备的构造有7个参数。
ThreadPoolExecutor(
//(线程数量)线程池最小线程数。
int corePoolSize,
//线程池创建的最大线程数。
int maximumPoolSize,
//当线程池中空闲线程数量超过corePoolSize时,多余的线程会在多长时间内被销毁。
long keepAliveTime,
//keepAliveTime的单位。
TimeUnit unit,
/**
* 任务队列,
* 被添加到线程池中,但尚未被执行的任务;
* 它一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列几种;
*/
BlockingQueue<Runnable> workQueue,
/**
*线程工厂,用于创建线程,一般用默认即可。
*/
ThreadFactory threadFactory,
//自定义拒绝策略。当任务太多时如何拒绝任务。
RejectedExecutionHandler handler
)
参数说明补充:
handler:通过这个参数你可以自定义任务的拒绝策略。如果线程池中所有的线程都在忙碌,并且工作队列也满了(前提是工作队列是有界队列),那么此时提交任务,线程池就会拒绝接收。至于拒绝的策略, 你可以通过handler这个参数来指定。ThreadPoolExecutor已经提供了以下4种策略。
- CallerRunsPolicy:提交任务的线程自己去执行该任务。(推荐使用)
- AbortPolicy:默认的拒绝策略,会throws RejectedExecutionException
- DiscardPolicy:直接丢弃任务,没有任何异常抛出。
- DiscardOldestPolicy:丢弃最老的任务,其实就是把最早进入工作队列的任务丢弃,然后把新任务加入 到工作队列。
缓冲队列
- BlockingQueue 是双缓冲队列。BlockingQueue 内部使用两条队列,允许两个线程同
时向队列一个存储,一个取出操作。在保证并发安全的同时,提高了队列的存取效率。- ArrayBlockingQueue:规定大小的BlockingQueue,其构造必须指定大小。其所含
的对象是FIFO 顺序排序的。- LinkedBlockingQueue:大小不固定的BlockingQueue,若其构造时指定大小,生
成的BlockingQueue 有大小限制,不指定大小,其大小有Integer.MAX_VALUE 来
决定。其所含的对象是FIFO 顺序排序的。- PriorityBlockingQueue:类似于LinkedBlockingQueue,但是其所含对象的排序不
是FIFO,而是依据对象的自然顺序或者构造函数的Comparator 决定。- SynchronizedQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成。
重要属性和方法
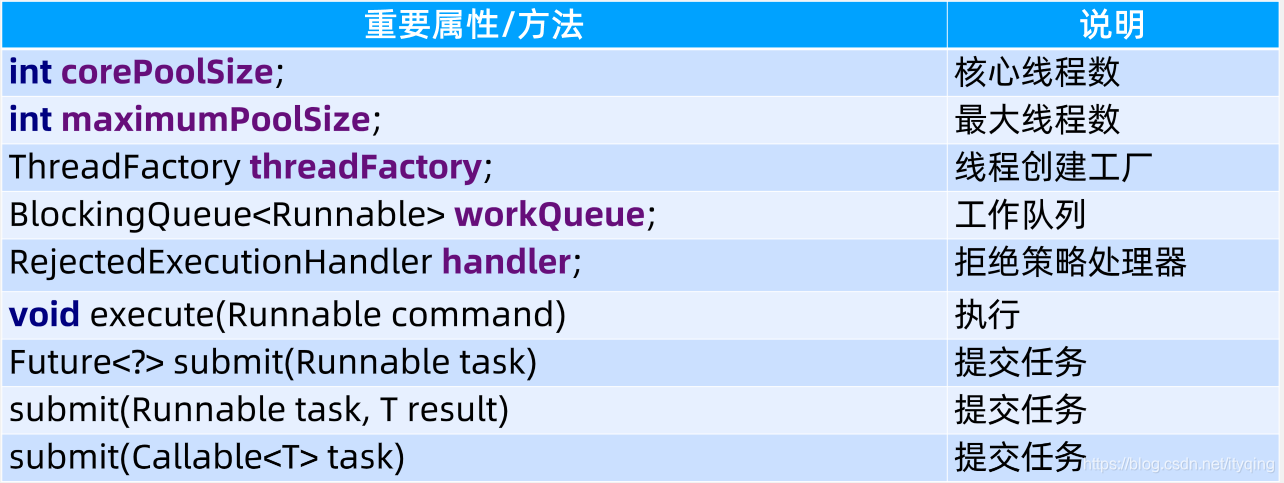
详情:https://www.cnblogs.com/dafanjoy/p/9729358.html
ThreadPoolExecutor提供的3个submit()方法和1个FutureTask工具类来支持获得执行任务执行结果的需求:
// 提交Runnable任务
Future<?> submit(Runnable task);
// 提交Callable任务
Future<T> submit(Callable<T> task);
// 提交Runnable任务及结果引⽤
Future<T> submit(Runnable task, T result);
- 提交Runnable任务submit(Runnable task) :这个方法的参数是一个Runnable接口,Runnable接扣的run()方法是没有返回值的,所以 submit(Runnable task) 这个方法返回的Future仅可以用来断言任务已经结束了,类似于Thread.join()。
- 提交Callable任务 submit(Callable task):这个方法的参数是一个Callable接口,它只有一个 call()方法,并且这个方法是有返回值的,所以这个方法返回的Future对象可以通过调用其get()方法来获取任务的执行结果。
- 提交Runnable任务及结果引用 submit(Runnable task, T result):这个方法很有意思,假设这个方法返回的Future对象是f,f.get()的返回值就是传给submit()方法的参数result。Runnable接口的实现类Task声明了一个有 参构造函数 Task(Result r) ,创建Task对象的时候传入了result对象,这样就能在类Task的run()方法 中对result进行各种操作了。result相当于主线程和子线程之间的桥梁,通过它主子线程可以共享数据。
常用方法:
在ThreadPoolExecutor类中有几个非常重要的方法:
execute()
submit()
shutdown()
shutdownNow()
execute()方法实际上是Executor中声明的方法,在ThreadPoolExecutor进行了具体的实现,这个方法是ThreadPoolExecutor的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。
submit()方法是在ExecutorService中声明的方法,在AbstractExecutorService就已经有了具体的实现,在ThreadPoolExecutor中并没有对其进行重写,这个方法也是用来向线程池提交任务的,但是它和execute()方法不同,它能够返回任务执行的结果,去看submit()方法的实现,会发现它实际上还是调用的execute()方法,只不过它利用了Future来获取任务执行结果(Future相关内容将在下一篇讲述)。
shutdown()和shutdownNow()是用来关闭线程池的。
使用并发工具包Executors创建线程池(不建议使用)
//创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
ExecutorService executor1 = Executors.newCachedThreadPool();
//创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
ExecutorService executor2 = Executors.newFixedThreadPool(10);
//创建一个定长线程池,支持定时及周期性任务执行。
ExecutorService executor3 = Executors.newScheduledThreadPool (10);
//创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
ExecutorService executor4 = Executors.newSingleThreadExecutor ();
- newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任
务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务
的执行顺序按照任务的提交顺序执行。 - newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线
程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充
一个新线程。 - newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添
加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者
说JVM)能够创建的最大线程大小。 - newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
不建议使用Executors,Executors提供的很多方法默认使用都是无界的LinkedBlockingQueue, 高负载情境下,无界队列很容易导致OOM,而OOM会导致所有请求都无法处理,所以强力建议使用有界队列。
使用线程池要注意什么
无界队列很容易导致OOM,而OOM会导致所有请求都无法处理,所以强力建议使用有界队列。
使用有界队列,当任务过多时,线程池会触发执行拒绝策略,线程默认的拒绝会。


















 8415
8415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











