




 本文探讨了Docker环境下MySQL的应用技巧,包括localhost的理解、连接Docker内MySQL的方法、库表数据保存机制及docker-compose的使用注意事项。
本文探讨了Docker环境下MySQL的应用技巧,包括localhost的理解、连接Docker内MySQL的方法、库表数据保存机制及docker-compose的使用注意事项。
最先提一句,据说docker若崩溃难以恢复,docker上是否放mysql需要慎重考虑
1.localhost在docker里意味着什么?
不是docker所在的服务器的ip地址
docker里的tomcat容器上的web项目连接mysql的url中,例如
spring.datasource.url=jdbc:mysql://域名:3306/数据库名?characterEncoding=UTF-8&serverTimezone=GMT
如果这个mysql和这里的docker安装在同一台服务器上(当然实际生产环境时MySQL单独存放的),无论这个mysql安装docker上还是直接安装在linux上,
域名不要使用localhost(这相当于一个相对地址),
而要用ip地址(这相当于一个绝对地址),
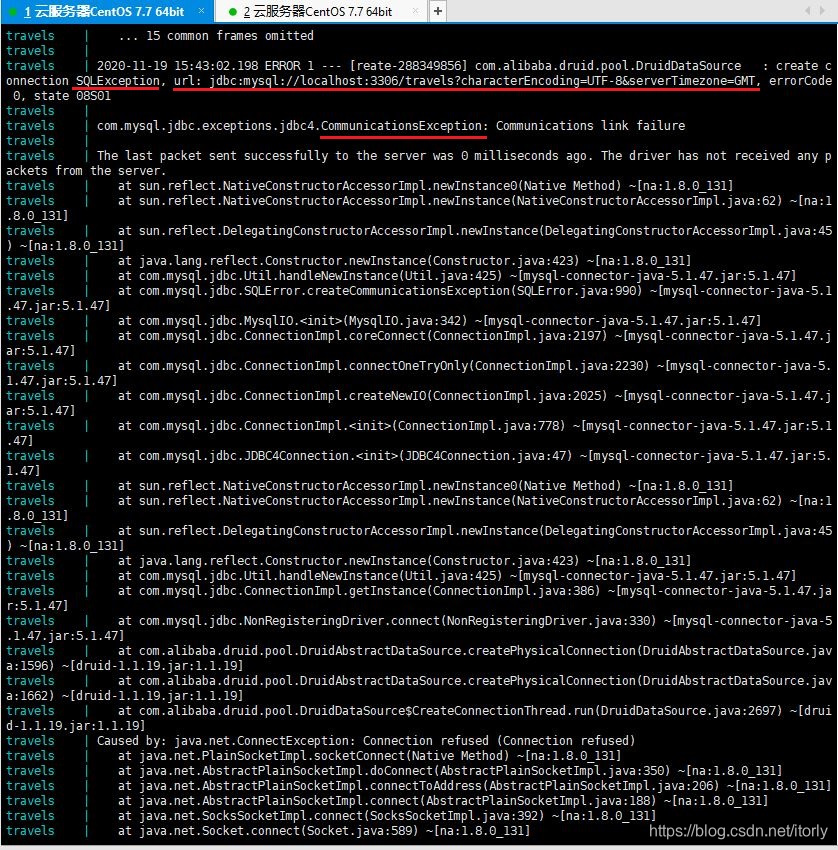
例如连接docker里的mysql容器,用localhost会导致连接mysql失败,tomcat运行日志报sqlException和communicationException异常:
2.如何登录docker里的mysql容器?
运行在docker里的mysql容器,linux上访问它要加 -h 127.0.0.1, 如:
mysql -h 127.0.0.1 -u root -p
当然要访问它也可以使用客户端navicat。
3.关于docker上的mysql容器里面的库及其表的存在或清空问题
3.1docker
执行关闭容器命令
docker stop 容器id
,此前创建的库表依然存在 。
执行删除容器命令
docker rm 容器id
,此前创建的库表被清空。
3.2docker-compose
(1)执行关闭或关闭并删除命令
docker-compose stop|down
之后 ,之前建立的库表依然存在。
(2)执行构建命令
docker-compose build
或 执行构建并启动命令
docker-compose up --build
,之前建立的库表被清空。
4.docker-compose启动支持类似事务回滚的设定吗?
在执行命令
docker-compose up -d
之后,有的容器启动失败虽然会报错,但是其余容器照常启动并运行,不会发生类似事务回滚的机制。
如果可以设定事务回滚的机制是否更加合理?即同一个docker-compose.yml管理的所有容器,只要启动失败的容器,那么其余所有容器都不应该照常启动运行。

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









