




 这篇博客详细介绍了如何在Linux环境下,一步步搭建大数据单节点环境,包括安装jdk、hadoop、hbase和spark。通过修改配置文件、设置环境变量、格式化namenode等步骤,最终成功启动hadoop、hbase和spark,并能通过Web界面进行访问和管理。适合初学者参考。
这篇博客详细介绍了如何在Linux环境下,一步步搭建大数据单节点环境,包括安装jdk、hadoop、hbase和spark。通过修改配置文件、设置环境变量、格式化namenode等步骤,最终成功启动hadoop、hbase和spark,并能通过Web界面进行访问和管理。适合初学者参考。
接触大数据已经有将近三年多时间了,实际项目也有将近两年多,这篇文章写给哪些和我当初刚学大数据时的朋友们,让大伙少走点弯路,千里之行始于足下,所以还是从单节点的大数据集群环境搭建开始,后续我有时间会陆续进行更新新的博客。
准备工作
-
linux机器一台
-
hadoop-2.4.1 文件
-
hbase-1.0.0 文件
-
jdk-8u45-linux-i586.rpm 文件
-
spark-1.3.1 文件
将所有文件都传到linux系统/usr/local目录下
第一步:安装jdk
切换到jdk-8u45-linux-i586.rpm文件所在目录,执行rpm –ivh jdk-8u45-linux-i586.rpm
第二步:安装hadoop
-
将hadoop文件上传到linux的/usr/local目录下

-
切换到root用户下

-
生成ssh秘钥(公钥 id_rsa、私钥 id_rsa.pub)生成的路径为:/root/.ssh,用于无密码登录 ssh-keygen -t rsa

-
切换到秘钥目录 cd /root/.ssh

-
将公钥追加到authorized_keys文件中:
cat id_rsa.pub > authorized_keys

-
切换到 config 文件 cd /etc/selinux/

-
修改config文件(#SELINUX=enforcing 改成 SELINUX=disabled) vim config

修改成功后,直接按ESC键、wq键保存并退出
-
测试是否可以无密码登录 ssh localhost

如果出现上面的信息,需要重启下linux。
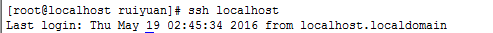
重启后ssh localhost 后,出现上面信息表示无密码登陆成功
-
在/etc/profile.d目录下设置环境变量 vim hadoop.sh 在空白文件中编写,然后必须重启服务器

因为原来不存在hadoop.sh文件,所以执行vim时会创建一个新的hadoop.sh,然后再新的文件中增加如下配置:
export HADOOP_HOME=/usr/local/hadoop-2.4.1
export PATH=$PATH:$HADOOP_HOME/bin


在看到目录下新增了一个hadoop.sh文件后,重启服务器
-
修改hadoop目录下etc中的core-site.xml 、yarn-site.xml、hadoop-env.sh 文件,具体内容为jdk目录、localhost换成具体IP地址等
首先切换到配置目录:cd /usr/local/hadoop-2.4.1/etc/hadoop/

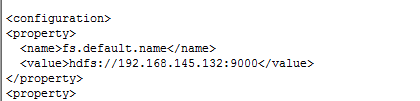
修改core-site.xml文件,将localhost换成IP,保存并退出
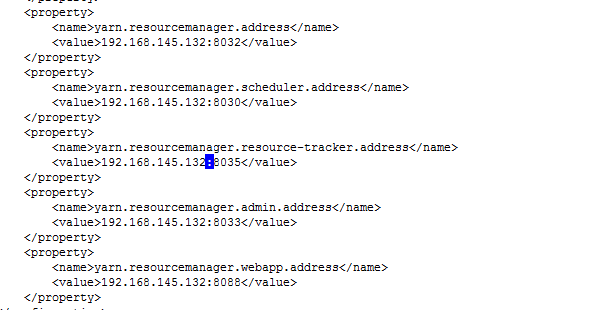
修改yarn-site.xml文件,将localhost换成IP,保存并退出
修改hadoop-env.sh文件,修改java_home路径,保存并退出s

在操作过程中如果碰到权限问题 chmod 777 (hadoop)目录 也可以是通配符 *.sh
-
格式化namenode,如果格式化成功后在hadoop目录(/usr/local/hadooptmp/namedata/current/)下会新增一个 hadooptmp目录,并且在hadooptemp目录下会有namedata/current/目录下
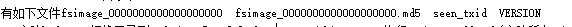
hadoop namenode –format
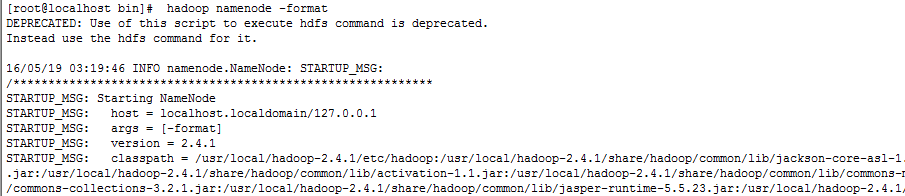

查看/usr/local/hadooptmp/namedata/current/目录下是否新增hadooptmp目录,并且在hadooptemp目录下会有namedata/current/目录

-
启动hadoop
切换目录cd /usr/local/hadoop-2.4.1/sbin 执行 ./start-dfs.sh(启动所有./start-all.sh 停止所有./stop-all.sh)
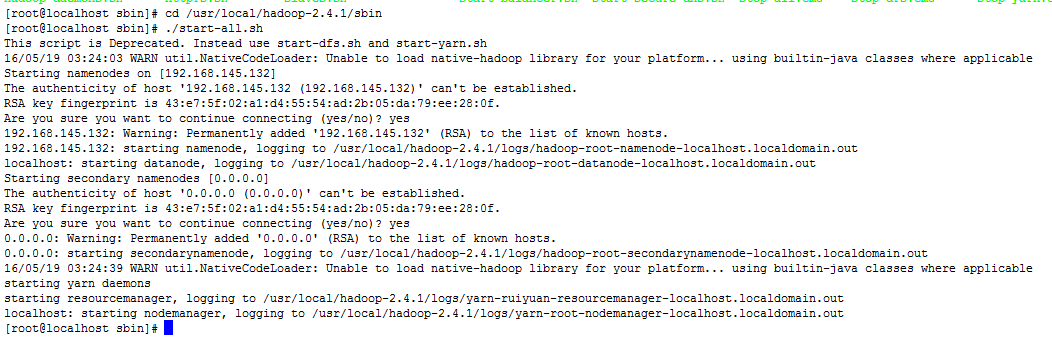
-
查看启动项,如果出现下面jps下面的五项,代表hadoop启动成功

-
往hadoop的fs目录下上传文件 hadoop fs -put 上传文件完整目录 上传后的文件名称
例如:hadoop fs -put /usr/local/hadoop-2.4.1/sbin/start-all.sh /hadoopTest.chenfeng

-
查看hdfs目录 命令: hadoop fs -ls /

可以看到刚刚上传的文件已经在hdfs目录中了
-
删除hadoop上的的文件夹 hadoop fs -rm -r /jeffResult*

可以看到上传的文件已经从hdfs目录中删除了
-
Web访问地址
hadoop启动成功后能访问的web地址: http://192.168.145.132:50070
yarn启动后访问地址: http://192.168.145.132:8088/cluster
hadoop具体语法及用法详见: http://blog.youkuaiyun.com/wf1982/article/details/6215545
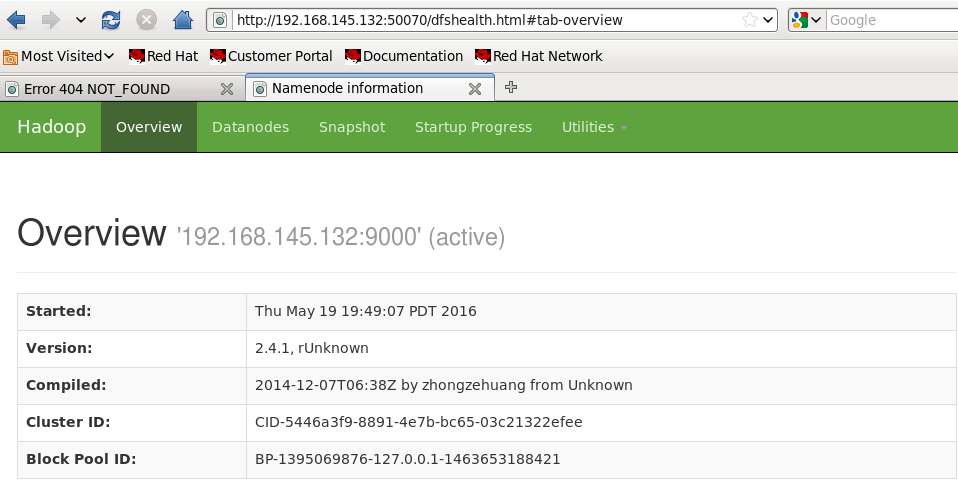
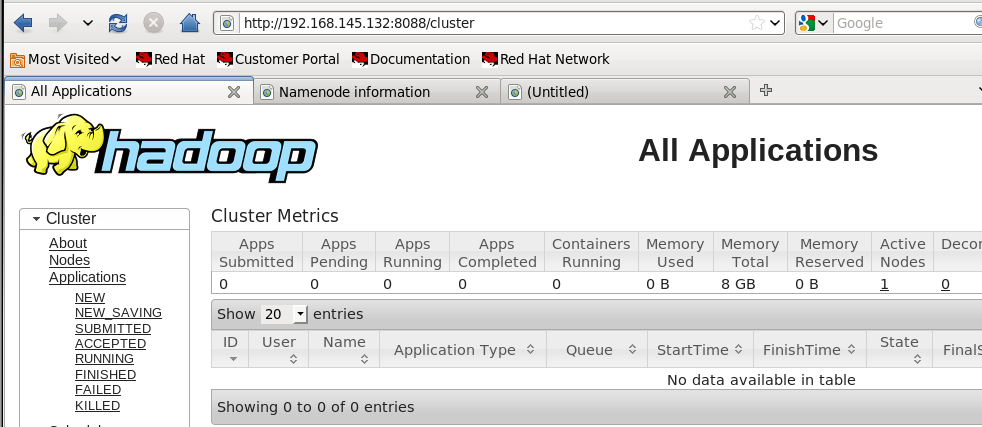
如果用java程序连接到hadoop的9000端口时出错,注意看slaves文件中的配置,不要用localhost,可以直接用本机IP,也可以在hosts配置一个名称如linux1,然后在这个地方配置成linux1
第三步:安装hbase
-
将hbase文件上传到linux的/usr/local目录下

-
切换到hbase/conf目录下

-
修改hbase-env.sh文件
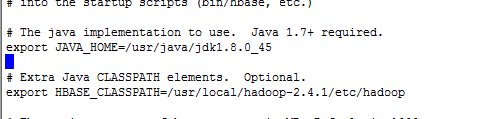
主要是修改java_home路径,保存并退出
-
修改hbase-site.xml文件,添加如下内容,这个目录系统会自动创建

主要修改了hbase.rootdir和hbase.zokeeper.quorum(可为localhost)配置,保存并推出
-
创建hbase 快速启动
切换到/etc/profile.d目录下,执行vim hbase.sh命令,将下面配置添加到文件中,保存并退出

可以看到此时目录下新增了一个hbase.sh的文件

然后重启服务器,在命令窗口即可执行hbase shell快速启动命令了
-
启动hbase

切换到/hbase/bin目录下,执行 ./start-hbase.sh,执行结果见上图
-
测试hbase
在命令窗口执行hbase shell命令,见下图

然后在

输入list命令查看现在hbase中所有的表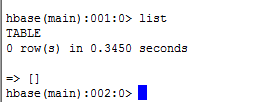
然后执行建表语句创建一个chenfeng的表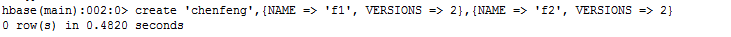
可以看到此时已经有chenfeng这个表了
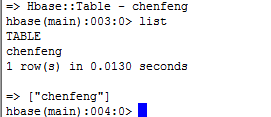
至此hbase单机版已经成功了
master访问地址:http://192.168.11.132:60030/master-status
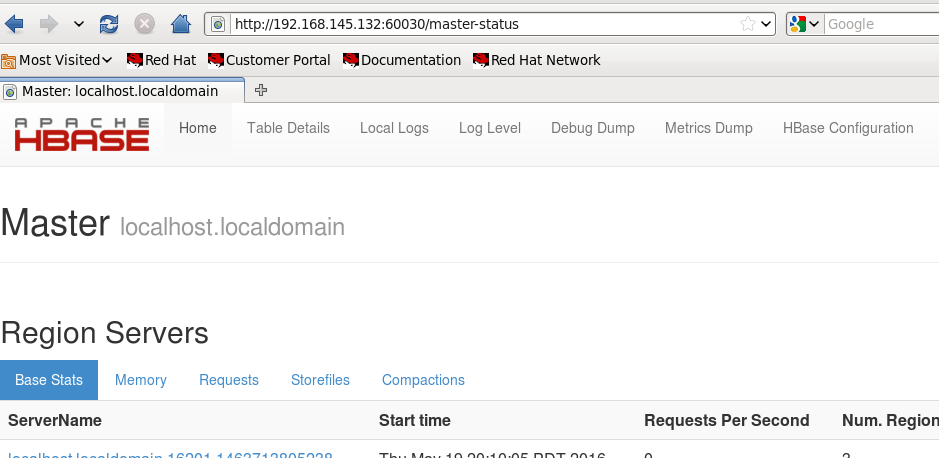
-
hbase具体命令及用法
第四步:安装spark
-
将spark放入到/usr/local目录中

-
切换到spark的conf目录,修改spark-env.sh文件,主要是local_ip master_ip等项

Vim spark-env.sh 进入编辑状态
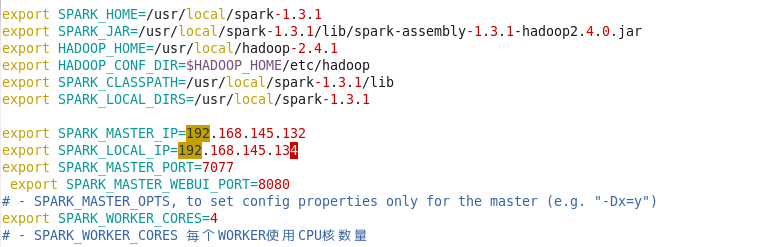
修改后保存并退出(注意:如果原来没有local_ip配置项,需要新增)
-
启动spark,启动文件放在了sbin目录

-
spark启动完成后查看端口是否已经启动监听 netstat -apn|grep 8080
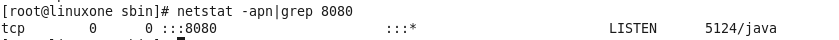
-
如果spark启动后虚拟机能访问,但是其他电脑不能访问,可能是防火墙的问题 service iptables status(查看防火墙命令) service iptables start/stop(启动关闭命令)

-
spark访问路径(weburl):http://192.168.11.132:8080/
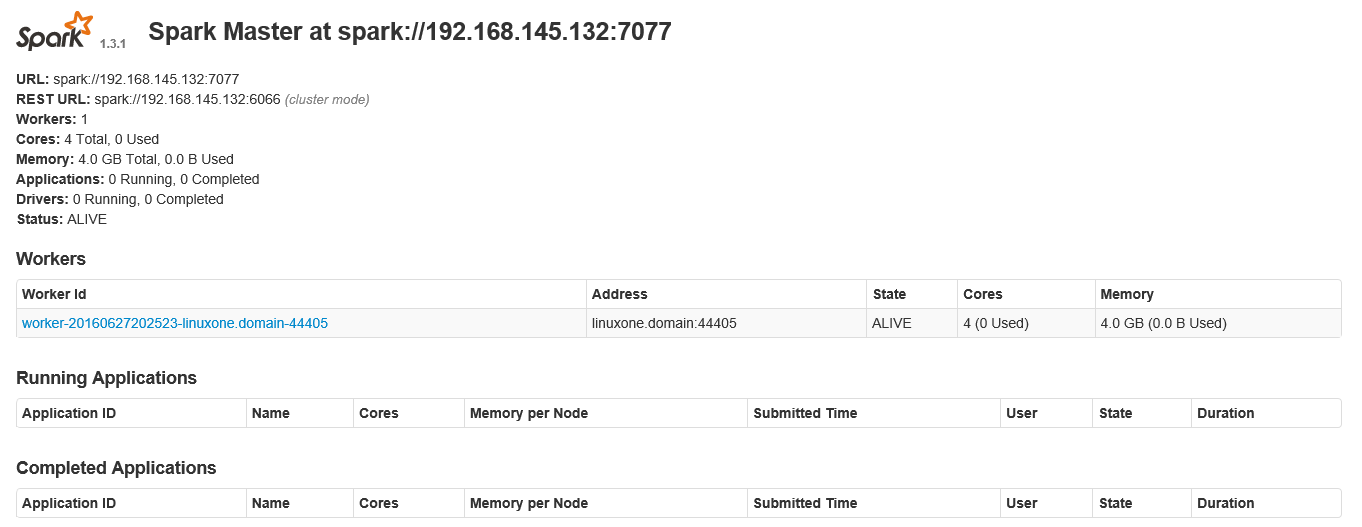

















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









