




 本文详细解析了Hadoop中不同输入格式(如TextInputFormat、DBInputFormat、NLineInputFormat、KeyValueInputFormat)如何处理数据,并介绍了如何在MapReduce中使用这些输入格式。包括对每个输入格式的工作原理、特性以及在实际应用中的示例进行阐述。
本文详细解析了Hadoop中不同输入格式(如TextInputFormat、DBInputFormat、NLineInputFormat、KeyValueInputFormat)如何处理数据,并介绍了如何在MapReduce中使用这些输入格式。包括对每个输入格式的工作原理、特性以及在实际应用中的示例进行阐述。
0 TextInputFormat extends FileInputFomrat<LongWritable,Text> 是默认读取文件的切分器
其内的LineRecordReader:用来读取每一行的内容,
LineRecordReader:内的 nextKeyValue(){}中,key的赋值在:
initialize()方法内, key=start=split.getStart(); split假如对应文件 hello.txt 期内为hello you hello me
那么起始位置就是0
end = start + split.getLength(),
而行文本在方法 读取到的行字节长度=readLine(...)中读取,对应到LineReader.readLine(...) 170行
string key = getCurrentKey() string value = getCurrentValue() 中得到
然后在Mapper类中:
while(LineRecordReader.nextKeyValue()){
key = linerecordreader.getCurrentKey()'
value = linerecordreader.getCurrentValue()
map.(key,value,context); 不停的将键值对写出去
}
1 DBInputFormat:
DBInputFormat 在读取数据时,产生的键值对是 <LongWritable,DBWritable的实例>
LongWritable仍旧是偏移量,
可以参看 org.apache.hadoop.mapreduce.lib.db.DBRecordReader.nextKeyValue()/232行,如下
key.set(pos + split.getStart()); 来确认 表示的仍旧是偏移量
package inputformat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.net.URI;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import mapreduce.MyWordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 目的: 将mysql/test库/myuser表中将字段id,name对应的属性通过 mapreduce(下面例子仅是通过map 没有reduce操作)将记录写出到hdfs中
* mysql--->map--->hdfs
* 要运行本示例
* 1.把mysql的jdbc驱动放到各TaskTracker节点的hadoop/mapreduce/lib目录下
* 2.重启集群
*
*/
public class MyDBInputFormatApp {
private static final String OUT_PATH = "hdfs://hadoop0:9000/out";
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
// 连接数据库 代码尽量考前写 写在后面执行会报错
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://hadoop0:3306/test", "root", "admin");
final FileSystem filesystem = FileSystem.get(new URI(OUT_PATH), conf);
if(filesystem.exists(new Path(OUT_PATH))){
filesystem.delete(new Path(OUT_PATH), true);
}
final Job job = new Job(conf , MyDBInputFormatApp.class.getSimpleName()); // 创建job
job.setJarByClass(MyDBInputFormatApp.class);
job.setInputFormatClass(DBInputFormat.class);// 指定inputsplit具体实现类
// 下面方法参数属性为: 操作javabean, 对应表名, 查询条件,排序要求,需要查询的表字段
DBInputFormat.setInput(job, MyUser.class, "myuser", null, null, "id", "name");//
// 设置map类和map处理的 key value 对应的数据类型
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0); //指定不需要使用reduce,直接把map输出写入到HDFS中
job.setOutputKeyClass(Text.class); // 设置job output key 输出类型
job.setOutputValueClass(NullWritable.class);// 设置job output value 输出类型
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.waitForCompletion(true);
}
//<k1,v1>对应的是数据库对应表下记录位置,和这行对应的JavaBean, <k2,v2>表示经过map处理好输出结果
public static class MyMapper extends Mapper<LongWritable, MyUser, Text, NullWritable>{
protected void map(LongWritable key, MyUser value, Context context) throws java.io.IOException ,InterruptedException {
context.write(new Text(value.toString()), NullWritable.get());
};
}
/**
* Writable是为了在Hadoop各节点之间传输使用的,因此需要实例化
* DBWritable表示和数据库传输时使用的
* @author zm
*
*/
public static class MyUser implements Writable, DBWritable{
int id;
String name;
// 针对Writable 需要重写的方法
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(id);
Text.writeString(out, name);
}
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
this.name = Text.readString(in);
}
// 针对DBWritable需要重写的方法
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setInt(1, id);
statement.setString(2, name);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.id = resultSet.getInt(1);
this.name = resultSet.getString(2);
}
@Override
public String toString() {
return id + "\t" + name;
}
}
}
2 NLineInputFormat:
这种格式下,split的数量就不是由文件对应block块个数决定的, 而是由设置处理多少行决定,
比如一个文件 100行, 设置NlineInputFormat 处理2行,那么会产生50个map任务, 每个map任务
仍旧一行行的处理 会调用2次map函数、
package inputformat;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* TextInputFormat处理的数据来自于一个InputSplit。InputSplit是根据大小划分的。
* NLineInputFormat决定每个Mapper处理的记录数是相同的。
* 设置map处理行数多,则需要产生的map个数就会减少
*/
public class MyNLineInputFormatApp {
private static final String INPUT_PATH = "hdfs://hadoop0:9000/hello";
private static final String OUT_PATH = "hdfs://hadoop0:9000/out";
public static void main(String[] args) throws Exception{
// 定义conf
Configuration conf = new Configuration();
//设置每个map可以处理多少条记录,默认是1行,这里设置为每个map处理的记录数都是2个
conf.setInt("mapreduce.input.lineinputformat.linespermap", 2);
final FileSystem filesystem = FileSystem.get(new URI(OUT_PATH), conf);
if(filesystem.exists(new Path(OUT_PATH))){
filesystem.delete(new Path(OUT_PATH), true);
}
// 定义job
final Job job = new Job(conf , MyNLineInputFormatApp.class.getSimpleName());
job.setJarByClass(MyNLineInputFormatApp.class);
// 定义 inputformat要处理的文件位置和具体处理实现类
FileInputFormat.setInputPaths(job, INPUT_PATH);
job.setInputFormatClass(NLineInputFormat.class);
// 设置map
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置处理最终结果输出路径
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
//解析源文件会产生2个键值对,分别是<0,hello you><10,hello me>;所以map函数会被调用2次
protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable,Text,Text,LongWritable>.Context context) throws java.io.IOException ,InterruptedException {
//为什么要把hadoop类型转换为java类型?
final String line = value.toString();
final String[] splited = line.split("\t");
//产生的<k,v>对少了
for (String word : splited) {
//在for循环体内,临时变量word的出现次数是常量1
context.write(new Text(word), new LongWritable(1));
}
};
}
//map函数执行结束后,map输出的<k,v>一共有4个,分别是<hello,1><you,1><hello,1><me,1>
//分区,默认只有一个区
//排序后的结果:<hello,1><hello,1><me,1><you,1>
//分组后的结果:<hello,{1,1}> <me,{1}> <you,{1}>
//归约(可选)
//map产生的<k,v>分发到reduce的过程称作shuffle
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
//每一组调用一次reduce函数,一共调用了3次
//分组的数量与reduce函数的调用次数有什么关系?
//reduce函数的调用次数与输出的<k,v>的数量有什么关系?
protected void reduce(Text key, java.lang.Iterable<LongWritable> values, org.apache.hadoop.mapreduce.Reducer<Text,LongWritable,Text,LongWritable>.Context context) throws java.io.IOException ,InterruptedException {
//count表示单词key在整个文件中的出现次数
long count = 0L;
for (LongWritable times : values) {
count += times.get();
}
context.write(key, new LongWritable(count));
};
}
}
3 KeyValueInputFormat:
如果行中有分隔符,那么分隔符前面的作为key,后面的作为value
如果行中没有分隔符,那么整行作为key,value为空
默认分隔符为 \t
package inputformat;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 以hello文件内容为如下为例:
* hello you
* hello me
*
* 特点是:
* Each line is divided into key and value parts by a separator byte. If no
such a byte exists, the key will be the entire line and value will be empty
通过分隔符将每一行切分 切分后结果分别作为key value
如果没有分隔符,那么正一行就作为key 值为null
如果一行中有多个制表符的话,会取第一个作为key 剩余作为value,后面的也不会再分割了
KeyValueInputForamt他用特定分隔符分割来形成自己的key value,看源码(KeyValueLineRecordReader下为\t)默制默认分隔符为制表符
输出结果为:
hello 1
you 1
helllo 1
me 1
*/
public class MyKeyValueTextInputFormatApp {
private static final String INPUT_PATH = "hdfs://hadoop0:9000/hello";
private static final String OUT_PATH = "hdfs://hadoop0:9000/out";
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");
final FileSystem filesystem = FileSystem.get(new URI(OUT_PATH), conf);
if(filesystem.exists(new Path(OUT_PATH))){
filesystem.delete(new Path(OUT_PATH), true);
}
// 创建job
final Job job = new Job(conf , MyKeyValueTextInputFormatApp.class.getSimpleName());
job.setJarByClass(MyKeyValueTextInputFormatApp.class);
// 设置InputFormat处理文件路径和具体操作实体类
FileInputFormat.setInputPaths(job, INPUT_PATH);
job.setInputFormatClass(KeyValueTextInputFormat.class);
// 设置map
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置reduce 这里reduce设置为0
job.setNumReduceTasks(0);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置最终结果输出路径
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<Text, Text, Text, LongWritable>{
protected void map(Text key, Text value, org.apache.hadoop.mapreduce.Mapper<Text,Text,Text,LongWritable>.Context context) throws java.io.IOException ,InterruptedException {
context.write(key, new LongWritable(1));
context.write(value, new LongWritable(1));
};
}
}
4 GenericWritable
适用于 不同输入源下,多map输出类型不同
package inputformat;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.GenericWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* MyMapper, MyMapper2的 v2输出类型一个是longWritable,一个是String, 两者需要统一成一个输出类型,
* 以方便job在设置v2类型----> job.setMapOutputValueClass(MyGenericWritable.class)
*
* 文件hello 内容为:
* hello you
* hello me
*
* 文件hello2 内容为:
* hello,you
* hello,me
* @author zm
*
*
*结果:
*[root@master hadoop]# hadoop fs -text /out/part-r-00000
Warning: $HADOOP_HOME is deprecated.
hello 4
me 2
you 2
*/
public class MyGenericWritableApp {
private static final String OUT_PATH = "hdfs://master:9000/out";
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
final FileSystem filesystem = FileSystem.get(new URI(OUT_PATH), conf);
if(filesystem.exists(new Path(OUT_PATH))){
filesystem.delete(new Path(OUT_PATH), true);
}
final Job job = new Job(conf , MyGenericWritableApp.class.getSimpleName());
job.setJarByClass(MyGenericWritableApp.class);
// 设置每种输入文件的位置 具体切分文件类 和对应的处理map类
MultipleInputs.addInputPath(job, new Path("hdfs://master:9000/hello"), KeyValueTextInputFormat.class, MyMapper.class);
MultipleInputs.addInputPath(job, new Path("hdfs://master:9000/hello2"), TextInputFormat.class, MyMapper2.class);
// 设置map
//job.setMapperClass(MyMapper.class); //不应该有这一行 上面已经设置好了map类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(MyGenericWritable.class);
// 设置reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置输出结果存放路径
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper<Text, Text, Text, MyGenericWritable>{
//解析源文件会产生2个键值对,分别是<hello,you> <hello,me>;所以map函数会被调用2次
// 处理后结果为: <hello,(MyGenericWritable(1),MyGenericWritable(1))> <you,(MyGenericWritable(1))> <me,(MyGenericWritable(1))>
protected void map(Text key, Text value, org.apache.hadoop.mapreduce.Mapper<Text,Text,Text,MyGenericWritable>.Context context) throws java.io.IOException ,InterruptedException {
context.write(key, new MyGenericWritable(new LongWritable(1)));
context.write(value, new MyGenericWritable(new LongWritable(1)));
};
}
public static class MyMapper2 extends Mapper<LongWritable, Text, Text, MyGenericWritable>{
//解析源文件会产生2个键值对,分别是<0,(hello,you)><10,(hello,me)>;键值对内的()是我自己加上去的为了便于和前面偏移量的,区分开来 所以map函数会被调用2次
// 处理后结果为: <hello,(MyGenericWritable("1"),MyGenericWritable("1"))> <you,(MyGenericWritable("1"))> <me,(MyGenericWritable("1"))>
protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable,Text,Text,MyGenericWritable>.Context context) throws java.io.IOException ,InterruptedException {
//为什么要把hadoop类型转换为java类型?
final String line = value.toString();
final String[] splited = line.split(",");
//产生的<k,v>对少了
for (String word : splited) {
System.out.println("MyMapper2 word is:" + word);
//在for循环体内,临时变量word的出现次数是常量1
final Text text = new Text("1");
context.write(new Text(word), new MyGenericWritable(text));
}
};
}
//map产生的<k,v>分发到reduce的过程称作shuffle
public static class MyReducer extends Reducer<Text, MyGenericWritable, Text, LongWritable>{
//每一组调用一次reduce函数,一共调用了3次
//分组的数量与reduce函数的调用次数有什么关系?
//reduce函数的调用次数与输出的<k,v>的数量有什么关系?
protected void reduce(Text key, java.lang.Iterable<MyGenericWritable> values, org.apache.hadoop.mapreduce.Reducer<Text,MyGenericWritable,Text,LongWritable>.Context context) throws java.io.IOException ,InterruptedException {
//count表示单词key在整个文件中的出现次数
long count = 0L;
for (MyGenericWritable times : values) {
final Writable writable = times.get();
if(writable instanceof LongWritable) {
count += ((LongWritable)writable).get();
}
if(writable instanceof Text) {
count += Long.parseLong(((Text)writable).toString());
}
}
context.write(key, new LongWritable(count));
};
}
/**
*
* @author zm
*
*/
public static class MyGenericWritable extends GenericWritable{
public MyGenericWritable() {}
public MyGenericWritable(Text text) {
super.set(text);
}
public MyGenericWritable(LongWritable longWritable) {
super.set(longWritable);
}
// 数组里面存放要处理的类型
@Override
protected Class<? extends Writable>[] getTypes() {
return new Class[] {LongWritable.class, Text.class};
}
}
}
5 CombineTextInputFormat:
将输入源目录下多个小文件 合并成一个文件(split)来交给mapreduce处理 这样只会生成一个map任务
比如用户给的文件全都是10K那种的文件, 其内部也是用的TextInputFormat 当合并大小大于(64M)128M的时候,
也会产生对应个数的split
6 SequenceFile: 也是合并, 还没明白和CombineTextInputFormat的区别在哪里:
import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Collection;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
public class SequenceFileMore {
public static void main(String[] args) throws IOException, URISyntaxException {
final Configuration conf = new Configuration();
final FileSystem fs = FileSystem.get(new URI("hdfs://h2single:9000/"), conf);
Path path = new Path("/sf_logs");
//写操作
final Writer writer = new SequenceFile.Writer(fs, conf, path, Text.class, BytesWritable.class);
// false表示不迭代子目录
Collection<File> listFiles = FileUtils.listFiles(new File("/usr/local/logs"), new String[]{"log"}, false);
for(File file : listFiles){ // 将/usr/local/logs下的所有.log文件 以对应文件文件名为key 对应文件内容字节数组为value 共同写入到/sf_logs内
String fileName = file.getName();
Text key = new Text(fileName);
byte[] bytes = FileUtils.readFileToByteArray(file);
BytesWritable value = new BytesWritable(bytes);
writer.append(key, value);
}
IOUtils.closeStream(writer);
//读操作
final SequenceFile.Reader reader = new SequenceFile.Reader(fs, path, conf);
final Text key = new Text();
final BytesWritable val = new BytesWritable();
while (reader.next(key, val)) {
String fileName = "/usr/local/logs_bak/" + key.toString();
File file = new File(fileName);
FileUtils.writeByteArrayToFile(file, val.getBytes());
}
IOUtils.closeStream(reader);
}
}
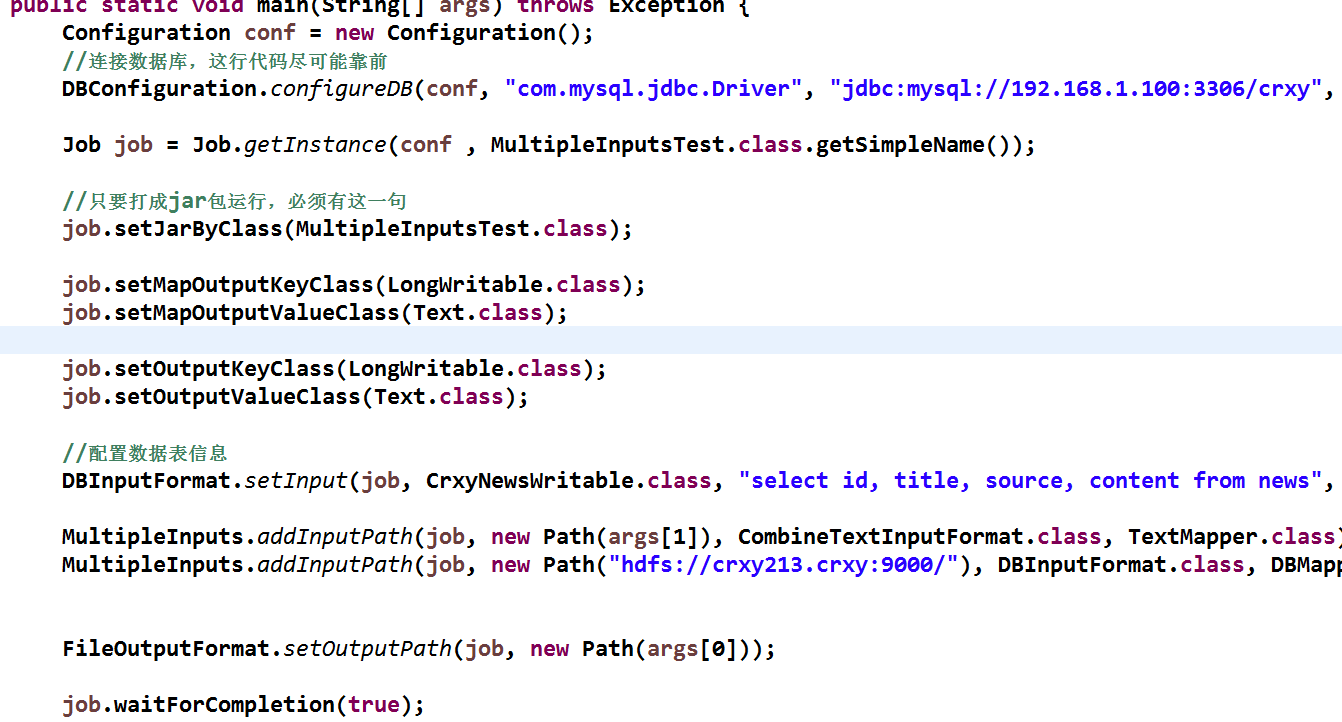
7 MultipleInputs: 对应于 多个文件处理类型下 比如又要处理数据库的文件 同时又要处理小文件
这里仅将main函数拼接展示下,各自对应的mapper类自己去写:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









