




 本文深入探讨了哈希表的基本概念、哈希函数、装载因子与冲突解决策略,通过具体代码实例展示了哈希表在数组和链表中的应用,以及与传统数据结构相比的优势。同时,介绍了哈希表的性能分析,包括查找速度、存储空间占用和平均查找长度,为读者提供全面理解哈希表的知识框架。
本文深入探讨了哈希表的基本概念、哈希函数、装载因子与冲突解决策略,通过具体代码实例展示了哈希表在数组和链表中的应用,以及与传统数据结构相比的优势。同时,介绍了哈希表的性能分析,包括查找速度、存储空间占用和平均查找长度,为读者提供全面理解哈希表的知识框架。
博客开始先发几句牢骚:今天这网速太慢了!我打开这个编辑页面就花了我半个小时!!!!!坑爹啊!还有,这是我第一次是现在word上编辑,再进行复制粘贴的。。。可能在排版上出现一点点问题吧,但我实在没有精力弄这个了,现在只是将哈希表的一些基本概述了一遍,接下来我会对HashMap和HashTable进行对比,找出他们之间的差别!
好了,开始今天的话题吧!
谈到hash表,对于我们在大二第二学期就学过了数据结构的来说,是有所了解的了,那时候我们是用的C语言,但由于那时候哈希表这一章是放在最后再讲的,随着课程的结束,我们的实验部分也就木有来的及时间去做了,现在重新拿起这些知识,只想感叹一句,理论理解和实践动手操作有着一条鸿沟!
一、数据结构之查找表
在说哈希表之前先简单介绍一下查找表,查找表是一种数据结构,是存放着同类型数据元素的集合,这里主要讲动态查找表。我们对查找表的操作大部分都是查找,但是这里所说的查找不仅仅只是检索的意思,而是包含四个意思:
1、查询某个“特定的”数据元素是否在查找表中
2、检索某个“特定的”数据元素的各种属性
3、在查找表中插入一个数据元素
4、从查找表中删去某个数据元素
特别是在对数据库的操作中,我们有查询、删除、添加等功能,随着数据量的增加,要求我们对数据的处理速度也要不断的提升,我们可以用顺序存储结构的数组,也可以用链式存储结构的链表来对数据进行处理,但数组的插入数据的效率很慢,而链表的查询速度很慢,这里我用实际代码来验证了
数组的代码为:
package cn.java1118;
/**
* 在数组中进行插入和查找
* @author acer
*
*/
public class ArrayTest {
//一个存放整型数据的数组
public Integer[] array;
/**
* 给出数组大小的构造函数
* @param capcity:数组大小
*/
public ArrayTest(int capcity){
array = new Integer[capcity];
//并将数组初始化
for(int i=0;i<capcity;i++){
array[i] = i;
}
}
/**
* 在数组下标为index的位置插入一个数据
* @param index:下标位置
*/
public void insertDate(int index,int Data){
//看空间是否足够
if(null==array[array.length-1]){
System.out.println("空间不足");
//说明空间不足
Integer[] oldArray = array;
array = new Integer[oldArray.length+1];
for(int j=0;j<oldArray.length;j++){
array[j] = oldArray[j];
}
}else{
// System.out.println("在这个位置插入一个值:"+index);
for(int i=array.length-1;i>index;i--){
if(null!=array[i-1]){
array[i] = array[i-1];
}
}
array[index] = Data;
}
}
/**
* 根据下标取得数值
* @param index:下标
* @return:对应下标里面的值
*/
public int get(int index){
return array[index];
}
/**
* 进行测试的主函数
* @param args
*/
public static void main(String[] args) {
ArrayTest array = new ArrayTest(100000);
//开始插入的时间
Long BeginTime1=System.currentTimeMillis();
for(int i=0;i<100000;i++){
array.insertDate(i, i);
}
//插入结束的时间
Long EndTime1=System.currentTimeMillis();
System.out.println("插入的时间为-->"+(EndTime1-BeginTime1));
//开始查询的时间
Long BeginTime2=System.currentTimeMillis();
array.get(10);
//查询结束的时间
Long EndTime2=System.currentTimeMillis();//记录EndTime
System.out.println("查找的时间为--->"+(EndTime2-BeginTime2));
}
}
这是我测试出来的结果:(这还只是数据量为100000的时候,当我用1000000测试的时候,等了好久都不出结果。。。)
插入的时间为-->27645
查找的时间为--->0
链表的代码:
package cn.java1118;
/**
* 在链表中进行插入和查找
*
* @author acer
*
*/
public class ListTest {
// 头结点
public Node head;
//构造函数
public ListTest(){
head = new Node();
head.data = 0;
head.index = 0;
}
/**
* 插入数据
*
* @param index
* :下标
* @param data
* :数据
*/
public void insert(int index, int data) {
Node newNode = new Node();
newNode.setData(data);
newNode.setIndex(index);
if(null!= head.next){
newNode.next = head.next;
}
head.next = newNode;
}
/**
* 根据索引值找数据
*
* @param index
* :索引值
* @return:数据
*/
public int get(int index) {
Node newNode = head;
// int t=0;
while (newNode.index != index) {
// t++;
// System.out.println("查询的次数为:"+t);
newNode = newNode.next;
}
return newNode.data;
}
// 内部类设置链表的节点
public class Node {
// 下一个节点
private Node next;
// 存放的整型数据
private int data;
// 索引的位置
private int index;
// set和get方法
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
}
/**
* 用于测试的主函数
*
* @param args
*/
public static void main(String[] args) {
ListTest list = new ListTest();
// 开始插入的时间
Long BeginTime1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
list.insert(i, i);
}
// 插入结束的时间
Long EndTime1 = System.currentTimeMillis();
System.out.println("插入的时间为-->" + (EndTime1 - BeginTime1));
// 开始查询的时间
Long BeginTime2 = System.currentTimeMillis();
for(int i=2;i<100;i++){
list.get(i);
}
// 查询结束的时间
Long EndTime2 = System.currentTimeMillis();// 记录EndTime
System.out.println("查找的时间为--->" + (EndTime2 - BeginTime2));
}
}
这是我测试出来的结果:(这里的用的链表用了索引,在查找的时候根本没有有去跟每一个值去比较,插入的时候也只是插入到第一个节点的后面,查找的数据量也没有测试很多,但时间就有这么长了,可想而知用链表查询的速度是多慢了。。。)
插入的时间为-->201
查找的时间为--->475
为此出现一种复合型的数据结构来弥补这两个缺陷,该结构就是哈希表,也称为散列表。
二、哈希表的基本知识介绍
哈希表是一种数据结构。是一种可以进行快速查询和插入以及删除的数据结构,以前我们进行查找一个数据的时候,一般都要与数组或者链表中的每一个值进行比较,而在哈希表中,利用一个关键字跟数据值绑定在一起形成键值对,再将关键字和哈希地址形成一种映射的关系,关键字作为记录在表中相应的存储位置,这样就可以很快的找到我们想要查询的东东了。
哈希表的查找过程如图所示:
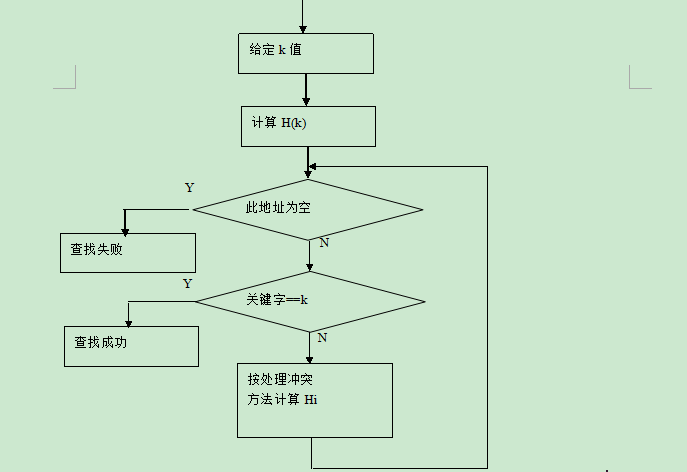
正因为关键字与哈希地址的映射关系这么重要,那么就有下面的问题,这个映射怎么去设置?!这里我们把这样的映射叫做哈希函数,我们可以很清楚的指导哈希函数是一个压缩映象,因此,在一般情况下,很容易产生“冲突”现象,即: key1¹ key2,而 f(key1) = f(key2),冲突问题又该怎样解决呢?!
三、哈希函数
数据中的关键字(key)和该数据在表中的位置存在着一种函数关系,这个函数f(key)就叫做哈希函数。哈希函数其实就是一个映射,是将关键字的集合映射到某个地址集合中
构造哈希函数的方法有以下几种:
1、直接定址法
哈希函数为关键字的线性函数,H(key) = a*key+b;这样的哈希函数中,地址集合的大小=关键字集合大小
2、数字分析法
根据关键字(整型)每一位上的数字出现的频率来决定哈希地址集合的范围,如果某一个位上的数字出现得比较集中(即频率比较高),则哈希地址在这一位上的数字不变,反之,在分散得比较均匀的位上选取的概率大一些。一般这种方法适用的范围是:事先估计出所有关键字每一位上数字出现的频率!
3、平方取中法
以关键字的平方值的中间几位作为存储地址。
4、折叠法
将关键字分割成若干部分,然后取它们的叠加和为哈希地址。
5、除留余数法
哈希函数为:H(key) = key MOD p ( p≤m ),其中, m为表长, p 为不大于 m 的素数或是不含 20 以下的质因子
6、随机数法
哈希函数为随机函数:H(key) = Random(key)
四、装载因子
装载因子λ=![]() ,当装载因子很小的时候就浪费了存储空间,当装载因子很大的时候就容易出现冲突,所以要选择恰当大小的装载因子,这样能提高查找和插入的速度,及提高查找性能!
,当装载因子很小的时候就浪费了存储空间,当装载因子很大的时候就容易出现冲突,所以要选择恰当大小的装载因子,这样能提高查找和插入的速度,及提高查找性能!
五、解决冲突的办法
1、开放定址法
Hi = ( H(key) + di ) MOD m,其中m为表长,H(key)为哈希函数,di的大小可以自己定,一般是这样的,如果两个key的哈希地址一样,那第二个key在这个哈希地址的周围去寻找没有放值的地址。这里根据增量序列di的大小不一样,分为以下三种方法:
1) 线性探测再散列
di = c*i 最简单的情况 c=1
2) 二次探测再散列
di = ![]() …,
…,
3) 随机探测再散列
di是一组伪随机数列或者
di=i×H2(key) (又称双散列函数探测)
2、链地址法
将所有哈希地址相同的记录都链接在同一链表中。
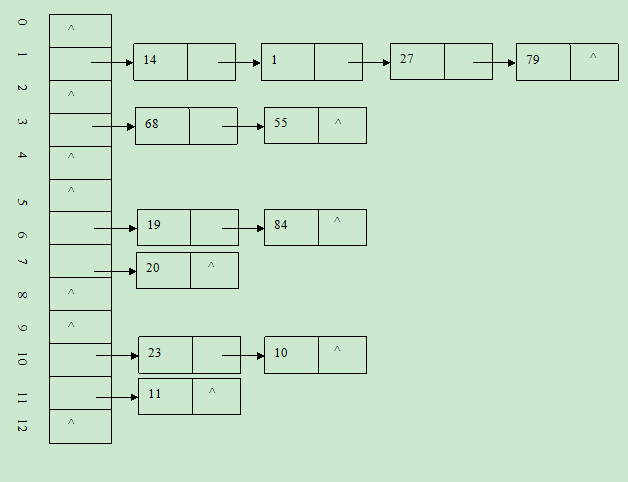
例如:
一组关键字(19,14,23,1,68,20,84,27,55,11,10,79),哈希函数为:H(key)=key MOD 13, 用链地址法处理冲突为:
(![]()
![]()
![]()
![]()
![]() 我画的分析图粘贴不上来。。。下次再弄吧。。。)
我画的分析图粘贴不上来。。。下次再弄吧。。。)
3、再哈希法
构造若干个哈希函数,当发生冲突时,根据另一个哈希函数计算下一个哈希地址,直到冲突不再发生。
六、性能分析
要知道其实哈希表就像是在数组中存放链表一样的复合型的数据结构,它结合了数组和链表的优点:
1、查找的速度
这里根据哈希函数得到哈希地址,再根据装载因子的大小看,不会像链表一样,全部放在一条链上面,这里是将其分散开来,则查找起来也会快一些。
2、查找所占用的存储空间的大小
由于数据量的增加,再哈希过程是会存在的,然而它是一个动态的变化过程,并不像数组一样可能会占用很多空闲的空间。
3、平均查找长度ASL
![]() ,因为有冲突的存在,hash表中的ASL是不可能为1了,主要是根据哈希函数和装载因子的大小而定的!
,因为有冲突的存在,hash表中的ASL是不可能为1了,主要是根据哈希函数和装载因子的大小而定的!
由于一篇可以放的代码量有限,性能的测试就放在下一章吧。。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









