




 本文介绍如何整合Hadoop HA与Spark HA集群,并通过具体步骤演示如何配置环境、启动服务及运行WordCount示例程序。
本文介绍如何整合Hadoop HA与Spark HA集群,并通过具体步骤演示如何配置环境、启动服务及运行WordCount示例程序。
原创转载请注明出处:http://agilestyle.iteye.com/blog/2294233
前提条件
整合步骤
cd到spark的conf的目录,修改spark-env.sh

添加如下
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.4/etc/hadoop

保存退出,将spark-env.sh分发到其他两个节点
scp spark-env.sh hadoop-0000:/home/hadoop/app/spark-1.6.1-bin-hadoop2.6/conf scp spark-env.sh hadoop-0001:/home/hadoop/app/spark-1.6.1-bin-hadoop2.6/conf
启动
首先启动Hadoop HA
http://hadoop-0000:50070 —— active
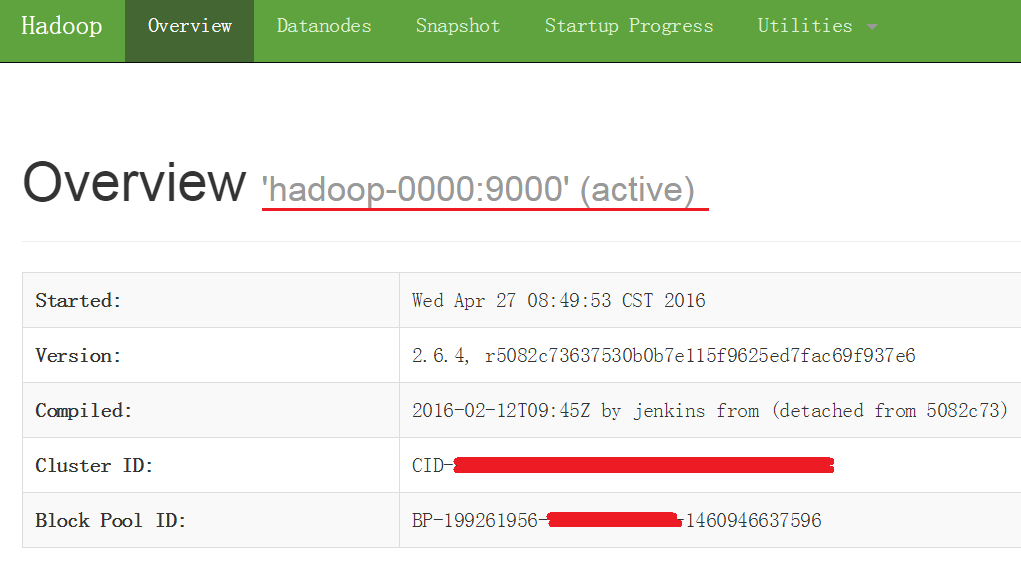
http://hadoop-0001:50070 —— standby
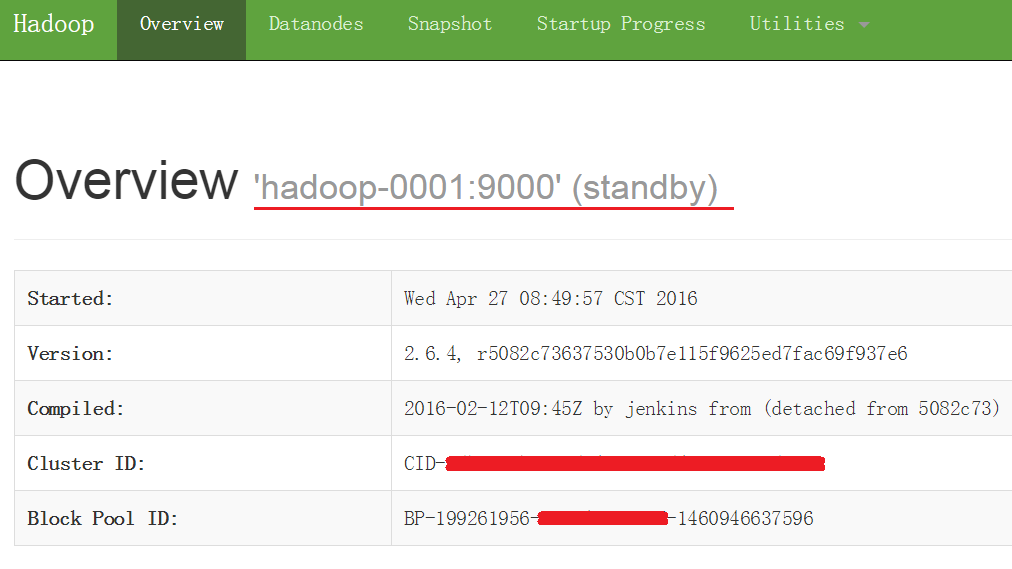
接着启动Spark HA(这里选择是hadoop-0002作为master)
http://hadoop-0002:8080 —— ALIVE
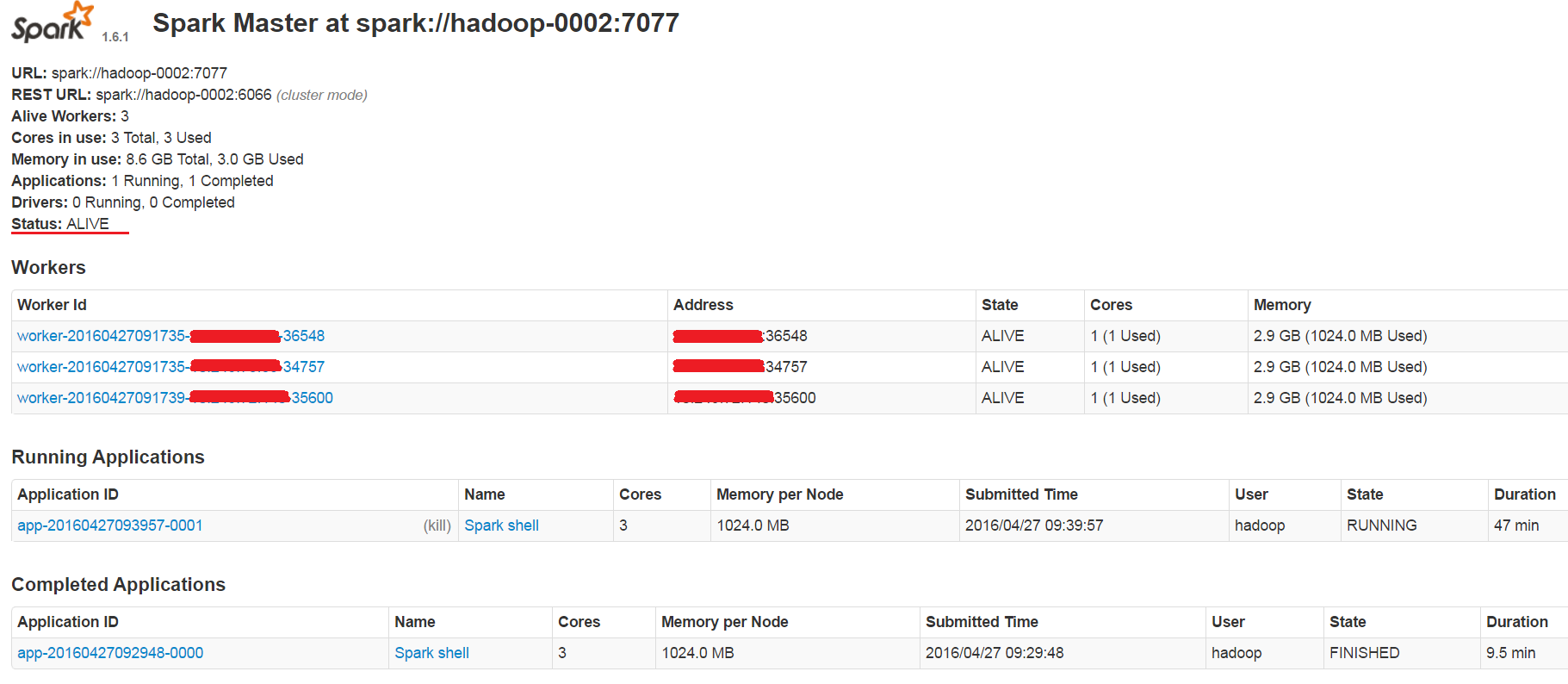
http://hadoop-0001:8080 —— STANDBY
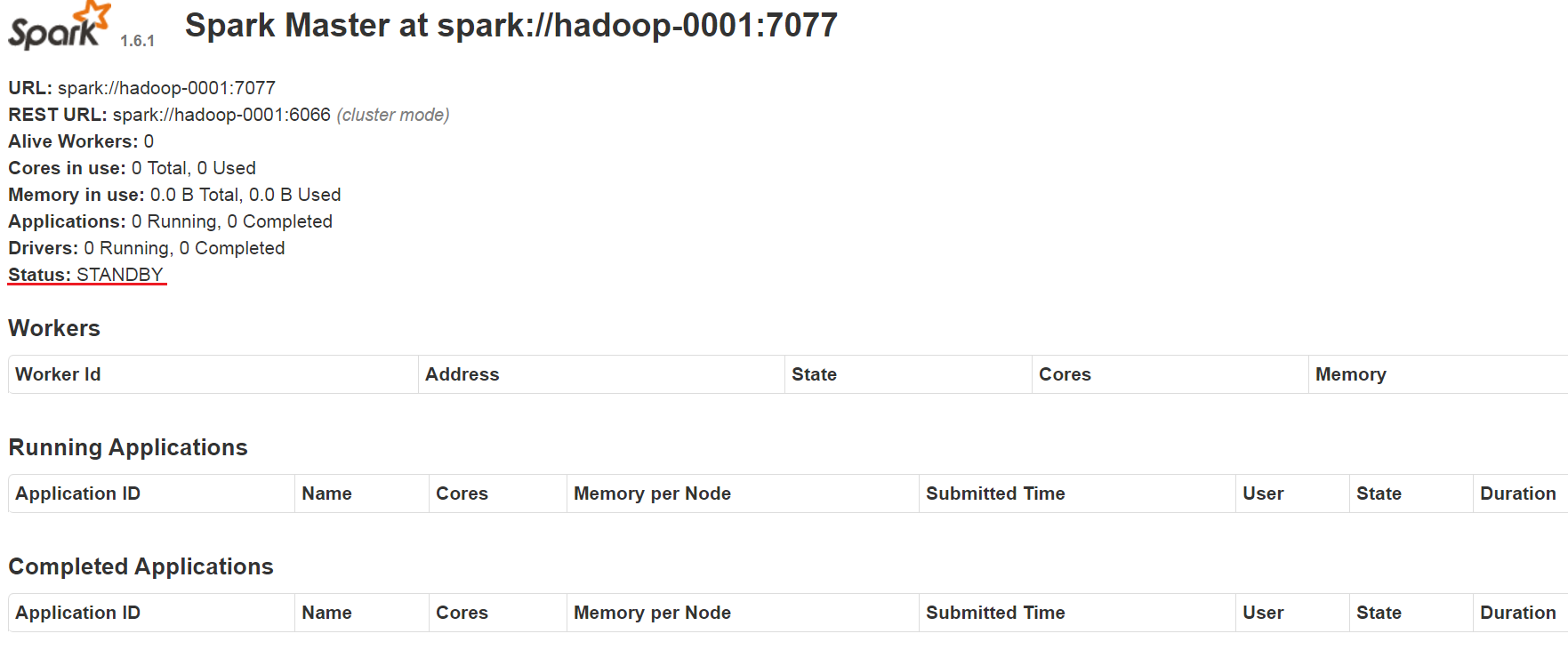
执行spark-shell
spark-shell --master spark://hadoop-0002:7077
WordCount
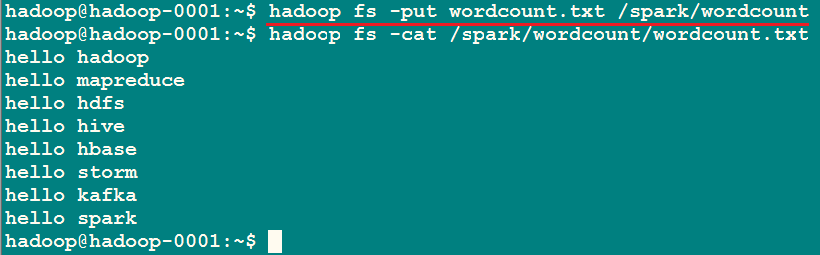
为了运行WordCount,需要上传一个文件到HDFS
hadoop fs -put wordcount.txt /spark/wordcount
切回spark-shell,执行如下
val rdd = sc.textFile("hdfs://hadoop-0000:9000/spark/wordcount/wordcount.txt")

接着执行
rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect
这条语句等价于
rdd.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b).collect


















 1565
1565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









