



 本文详细介绍了如何使用DOM(文档对象模型)来操作HTML和XML文档。包括创建、查询、修改及删除节点的操作方法,并展示了如何利用JavaScript实现这些功能。
本文详细介绍了如何使用DOM(文档对象模型)来操作HTML和XML文档。包括创建、查询、修改及删除节点的操作方法,并展示了如何利用JavaScript实现这些功能。
 <script language="JavaScript"><!--var doc = new ActiveXObject("Msxml2.DOMDocument"); //ie5.5+,CreateObject("Microsoft.XMLDOM") //加载文档//doc.load("b.xml");//创建文件头var p = doc.createProcessingInstruction("xml","version='1.0' encoding='gb2312'"); //添加文件头 doc.appendChild(p);//用于直接加载时获得根接点//var root = doc.documentElement;//两种方式创建根接点// var root = doc.createElement("students"); var root = doc.createNode(1,"students",""); //创建子接点 var n = doc.createNode(1,"ttyp",""); //指定子接点文本 //n.text = " this is a test"; //创建孙接点 var o = doc.createElement("sex"); o.text = "男"; //指定其文本 //创建属性 var r = doc.createAttribute("id"); r.value="test"; //添加属性 n.setAttributeNode(r); //创建第二个属性 var r1 = doc.createAttribute("class"); r1.value="tt"; //添加属性 n.setAttributeNode(r1); //删除第二个属性 n.removeAttribute("class"); //添加孙接点 n.appendChild(o); //添加文本接点 n.appendChild(doc.createTextNode("this is a text node.")); //添加注释 n.appendChild(doc.createComment("this is a comment ")); //添加子接点 root.appendChild(n); //复制接点 var m = n.cloneNode(true); root.appendChild(m); //删除接点 root.removeChild(root.childNodes(0)); //创建数据段 var c = doc.createCDATASection("this is a cdata"); c.text = "hi,cdata"; //添加数据段 root.appendChild(c); //添加根接点 doc.appendChild(root); //查找接点 var a = doc.getElementsByTagName("ttyp"); //var a = doc.selectNodes("//ttyp"); //显示改接点的属性 for(var i= 0;i<a.length;i++)
<script language="JavaScript"><!--var doc = new ActiveXObject("Msxml2.DOMDocument"); //ie5.5+,CreateObject("Microsoft.XMLDOM") //加载文档//doc.load("b.xml");//创建文件头var p = doc.createProcessingInstruction("xml","version='1.0' encoding='gb2312'"); //添加文件头 doc.appendChild(p);//用于直接加载时获得根接点//var root = doc.documentElement;//两种方式创建根接点// var root = doc.createElement("students"); var root = doc.createNode(1,"students",""); //创建子接点 var n = doc.createNode(1,"ttyp",""); //指定子接点文本 //n.text = " this is a test"; //创建孙接点 var o = doc.createElement("sex"); o.text = "男"; //指定其文本 //创建属性 var r = doc.createAttribute("id"); r.value="test"; //添加属性 n.setAttributeNode(r); //创建第二个属性 var r1 = doc.createAttribute("class"); r1.value="tt"; //添加属性 n.setAttributeNode(r1); //删除第二个属性 n.removeAttribute("class"); //添加孙接点 n.appendChild(o); //添加文本接点 n.appendChild(doc.createTextNode("this is a text node.")); //添加注释 n.appendChild(doc.createComment("this is a comment ")); //添加子接点 root.appendChild(n); //复制接点 var m = n.cloneNode(true); root.appendChild(m); //删除接点 root.removeChild(root.childNodes(0)); //创建数据段 var c = doc.createCDATASection("this is a cdata"); c.text = "hi,cdata"; //添加数据段 root.appendChild(c); //添加根接点 doc.appendChild(root); //查找接点 var a = doc.getElementsByTagName("ttyp"); //var a = doc.selectNodes("//ttyp"); //显示改接点的属性 for(var i= 0;i<a.length;i++)
 ...{
...{ alert(a[i].xml); for(var j=0;j<a[i].attributes.length;j++)
alert(a[i].xml); for(var j=0;j<a[i].attributes.length;j++)
 ...{ alert(a[i].attributes[j].name);
...{ alert(a[i].attributes[j].name); }
} } //修改节点,利用XPATH定位节点 var b = doc.selectSingleNode("//ttyp/sex"); b.text = "女"; //alert(doc.xml); //XML保存(需要在服务端,客户端用FSO) //doc.save(); //查看根接点XML if(n) ...{ alert(n.ownerDocument.xml); }//--></script>
} //修改节点,利用XPATH定位节点 var b = doc.selectSingleNode("//ttyp/sex"); b.text = "女"; //alert(doc.xml); //XML保存(需要在服务端,客户端用FSO) //doc.save(); //查看根接点XML if(n) ...{ alert(n.ownerDocument.xml); }//--></script>
在DOM眼中,HTML跟XML一样是一种树形结构的文档,<html>是根(root)节点,<head>、<title>、<body>是<html>的子(children)节点,互相之间是兄弟(sibling)节点;<body>下面才是子节点<table>、<span>、<p>等等。如下图: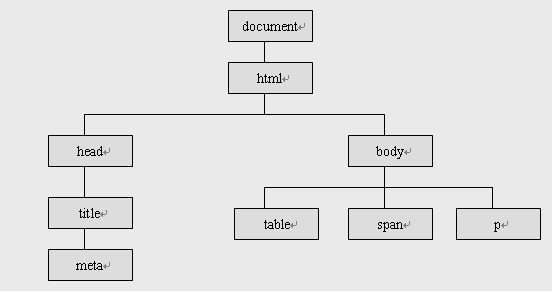
这个是不是跟XML的结构有点相似呢。不同的是,HTML文档的树形主要包含表示元素、标记的节点和表示文本串的节点。
HTML文档的节点
DOM下,HTML文档各个节点被视为各种类型的Node对象。每个Node对象都有自己的属性和方法,利用这些属性和方法可以遍历整个文档树。由于HTML文档的复杂性,DOM定义了nodeType来表示节点的类型。这里列出Node常用的几种节点类型:
| 接口 | nodeType常量 | nodeType值 | 备注 |
| Element | Node.ELEMENT_NODE | 1 | 元素节点 |
| Text | Node.TEXT_NODE | 3 | 文本节点 |
| Document | Node.DOCUMENT_NODE | 9 | document |
| Comment | Node.COMMENT_NODE | 8 | 注释的文本 |
| DocumentFragment | Node.DOCUMENT_FRAGMENT_NODE | 11 | document片断 |
| Attr | Node.ATTRIBUTE_NODE | 2 | 节点属性 |
DOM树的根节点是个Document对象,该对象的documentElement属性引用表示文档根元素的Element对象(对于HTML文档,这个就是<html>标记)。Javascript操作HTML文档的时候,document即指向整个文档,<body>、<table>等节点类型即为Element。Comment类型的节点则是指文档的注释。具体节点类型的含义,请参考《Javascript权威指南》,在此不赘述。
Document定义的方法大多数是生产型方法,主要用于创建可以插入文档中的各种类型的节点。常用的Document方法有:
| 方法 | 描述 |
| createAttribute() | 用指定的名字创建新的Attr节点。 |
| createComment() | 用指定的字符串创建新的Comment节点。 |
| createElement() | 用指定的标记名创建新的Element节点。 |
| createTextNode() | 用指定的文本创建新的TextNode节点。 |
| getElementById() | 返回文档中具有指定id属性的Element节点。 |
| getElementsByTagName() | 返回文档中具有指定标记名的所有Element节点。 |
对于Element节点,可以通过调用getAttribute()、setAttribute()、removeAttribute()方法来查询、设置或者删除一个Element节点的性质,比如<table>标记的border属性。下面列出Element常用的属性:
| 属性 | 描述 |
| tagName | 元素的标记名称,比如<p>元素为P。HTML文档返回的tabName均为大写。 |
Element常用的方法:
| 方法 | 描述 |
| getAttribute() | 以字符串形式返回指定属性的值。 |
| getAttributeNode() | 以Attr节点的形式返回指定属性的值。 |
| getElementsByTabName() | 返回一个Node数组,包含具有指定标记名的所有Element节点的子孙节点,其顺序为在文档中出现的顺序。 |
| hasAttribute() | 如果该元素具有指定名字的属性,则返回true。 |
| removeAttribute() | 从元素中删除指定的属性。 |
| removeAttributeNode() | 从元素的属性列表中删除指定的Attr节点。 |
| setAttribute() | 把指定的属性设置为指定的字符串值,如果该属性不存在则添加一个新属性。 |
| setAttributeNode() | 把指定的Attr节点添加到该元素的属性列表中。 |
Attr对象代表文档元素的属性,有name、value等属性,可以通过Node接口的attributes属性或者调用Element接口的getAttributeNode()方法来获取。不过,在大多数情况下,使用Element元素属性的最简单方法是getAttribute()和setAttribute()两个方法,而不是Attr对象。
使用DOM操作HTML文档
Node对象定义了一系列属性和方法,来方便遍历整个文档。用parentNode属性和childNodes[]数组可以在文档树中上下移动;通过遍历childNodes[]数组或者使用firstChild和nextSibling属性进行循环操作,也可以使用lastChild和previousSibling进行逆向循环操作,也可以枚举指定节点的子节点。而调用appendChild()、insertBefore()、removeChild()、replaceChild()方法可以改变一个节点的子节点从而改变文档树。
需要指出的是,childNodes[]的值实际上是一个NodeList对象。因此,可以通过遍历childNodes[]数组的每个元素,来枚举一个给定节点的所有子节点;通过递归,可以枚举树中的所有节点。下表列出了Node对象的一些常用属性和方法:
Node对象常用属性:
| 属性 | 描述 |

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









