




 本文详细介绍了Python中的字符串处理方法,包括字符串的创建、访问、连接、切片等基本操作,以及大小写转换、去除空白、查找替换等常用函数。此外还讲解了如何处理Unicode字符串,并提供了if语句的使用示例。
本文详细介绍了Python中的字符串处理方法,包括字符串的创建、访问、连接、切片等基本操作,以及大小写转换、去除空白、查找替换等常用函数。此外还讲解了如何处理Unicode字符串,并提供了if语句的使用示例。
原文:http://code.google.com/edu/languages/google-python-class/strings.html
Python Strings
Google Code University › Programming Languages
Python有一个内置的字符串类叫做str,它有很多非常方便的功能 (还有一个比较老的类叫做string,应当避免使用). String字面值可以用单引号或双引号表示(单引号更常用一些). 如果想要在字符串中包含单引号或双引号,可以使用反斜杠转义 -- 例如 \n \' \". 双引号可以直接包含单引号而不回踩产生任何冲突 (例如: "I didn't do it") ,同时单引号也可以包含双引号. 可以通过在每一行后面加上\来使用多行的字符串. """或'''可以声明使用多行字符串。
Python中的字符串类型是"不可变"数据(immutable),即创建之后就不能修改 (同Java中的String一样). 因此我们在对字符串进行连接的时候往往创建了新的字符串. 例如 ('hello' + 'there') 使用hello、there创建了一个新的字符串hellothere.
string中的字符可以使用标准[]进行访问, 同Java一样,python使用零开头的索引方式.如果索引不存在python会跑出一个error. 与Perl不同,Python如果遇到错误会停止执行,而不是使用一个默认值。"slice" 关键字 (如下) 可以从一个字符串中获取它的紫川. len(string)可以返回stirng的长度. []和len()可以在任何序列中使用 -- strings, lists, 等等.. Python希望所有不同类型的操作都可以用同样的方式进行. Python新手提示: 不要定义一个len变量去避免使用len()函数. '+'可以连接两个字符串.
s = 'hi' print s[1] ## i print len(s) ## 2 print s + ' there' ## hi there
不同于Java '+' 不会自动把数字类型转换成string类型并完成连接. str()函数用来完成转换操作.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
对于Number类型来说, +, /, * 按照通常的方式执行. 但是没有 ++ 操作符,有 +=, -=。 如果你想要对整数进行整除操作,建议使用//进行。 (python 3000 之前, /就可以进行整除操作,但是现在建议使用//来进行整除.)
print函数打印一个或多个python变量并以一个新行结束 (在行尾使用逗号可以取消新行结尾). "raw"(原生)字符串以一个'r'开头,字符串内容中的转义将被全部忽略, 因此 r'x\nx' 会输出 'x\nx'. 'u'开头的字符串允许你编写unicode字符串 (Python有很多的unicode字符库支持 -- 看后文的文档).
raw = r'this\t\n and that' print raw ## this\t\n and that multi = """It was the best of times. It was the worst of times."""
String 函数
下面是一些最常用的string操作函数. 一个函数运行在一个对象之上 (OOP uh) :
- s.lower(), s.upper() -- 大小写转换
- s.strip() -- 将字符串头尾的空白去掉
- s.isalpha()/s.isdigit()/s.isspace()... -- 测试字符串的类型
- s.startswith('other'), s.endswith('other') -- 测试字符串包含
- s.find('other') -- 查找目标字符串的索引(非正则),找不到返回-1
- s.replace('old', 'new') -- returns a string where all occurrences of 'old' have been replaced by 'new'
- s.split('delim') -- 根据给定的字符分割字符串(非正则),如:'aaa,bbb,ccc'.split(',') -> ['aaa', 'bbb', 'ccc']. s.split()默认以空白字符分割。
- s.join(list) -- split()的逆操作,如:'---'.join(['aaa', 'bbb', 'ccc']) -> aaa---bbb---ccc
在google搜索"python str" 并找到 python.org string methods 可以获得所有的string函数
Python并没有一个单独的“字符”类型,所有的字符都是以字符串的形式存在.
String Slices (字符串切割)
"slice" 关键词是适用于序列元素的很方便的工具 -- 尤其是字符串和列表. s[start:end]表示从start开始到end(不包含end)位置结束. 加入我们有一个 s = "Hello"
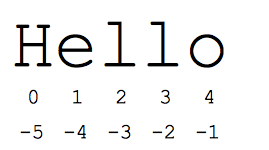
- s[1:4] is 'ell' -- chars starting at index 1 and extending up to but not including index 4
- s[1:] is 'ello' -- 不写边界默认为0或总长度
- s[:] is 'Hello' -- 遍历整个字符串的常用方法
- s[1:100] is 'ello' -- 不会报错
与正数对应,负数作为索引会从字符串的末尾开始计数:
- s[-1] is 'o' -- last char (1st from the end)
- s[-4] is 'e' -- 4th from the end
- s[:-3] is 'He' -- going up to but not including the last 3 chars.
- s[-3:] is 'llo' -- starting with the 3rd char from the end and extending to the end of the string.
slices有一个众所周知的小技巧, s[:n] + s[n:] == s. 这段代码在n越界的情况下也会正常执行. 这些特性同样也适用于list,我们会在后面讲到。
String %
Python有一个与 printf() 类似的工具. 可以使用后面的变量替换printf中的% (%d int, %s string, %f/%g floating point),如右侧的元组(tuple) (元组是一组被逗号风格的,以圆括号包含的一组数):
# % operator text = "%d little pigs come out or I'll %s and %s and %s" % (3, 'huff', 'puff', 'blow down')
上面的字符串可能有些长,但是你不能像在其他语言中那样直接换行, 这是因为python把每一行都当做单独的一条语句 (这就是为什么我们不需要在每行结束使用分号). 我们可以用一个外层圆括号包含整个语句来解决这个问题. 这种跨行编辑的特性同样适用于: ( ), [ ], { }.
# add parens to make the long-line work: text = ("%d little pigs come out or I'll %s and %s and %s" % (3, 'huff', 'puff', 'blow down'))
i18n Strings (Unicode)
通常的Python字符串不是unicode编码, 他们仅仅是无格式的字节. 我们可以使用'u'前缀来使用unicode字符串:
> ustring = u'A unicode \u018e string \xf1' > ustring u'A unicode \u018e string \xf1'
unicode字符串是不同于str类型的另外的字符串,但是他们是兼容的 (他们有共同的父类 "basestring"), 并且正则表达式也能正常工作(unicode中使用正则同样需要unicode版的正则)。
可以使用ustring.encode('utf-8')把一个unicode字符串编码成unicode字节。同时unicode(s, encoding)可以把一个编码过的unicode字节还原为unicode字符串:
## (unistring from above contains a unicode string) > s = unistring.encode('utf-8') > s 'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding > t = unicode(s, 'utf-8') ## Convert bytes back to a unicode string > t == unistring ## It's the same as the original, yay!
True
内建的print函数对unicode支持不够好. 所以你可以先encode这些unicode字符串然后再进行print. 在file-reading章节,我们可以看到如果对一个含有unicode字符的文件进行操作。 值的注意的是,不同于这里讲的python2.x,Python 3000对字符处理进行了重新整理。
If Statement(If语句)
Python不使用 { } 对 if/loops/function 这样的操作进行封装,而是使用空白缩进、冒号对代码块进行组织。 If语句也不需要使用圆括号进行封装 , 并且也可以使用如 *elif* 和 *else* 这样的语句。
任何值都可以作为if判断的条件.如下这些”空值“都被当做False : None, 0, 空白字符串(String), 空列表(List),空字典(Dict). Boolean类型为: True and False (int表示为1和0). 不同于C++和Java,“==”符号被overload以适应字符串判断. 布尔类型可以使用 *and*, *or*, *not* (Python不适用C-style && || !)进行组合. 下面是一组示例代码,注意其中的缩进和条件判断以及冒号
if speed >= 80: print 'License and registration please' if mood == 'terrible' or speed >= 100: print 'You have the right to remain silent.' elif mood == 'bad' or speed >= 90: print "I'm going to have to write you a ticket." write_ticket() else: print "Let's try to keep it under 80 ok?"
我发现冒号是我最容易犯的一个错误. 并且不要把判断条件放到括号里. 如果代码很多,你可以把他们放到同一行里,如:
if speed >= 80: print 'You are so busted' else: print 'Have a nice day'


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









