 Hive查询引擎解析
Hive查询引擎解析





 本文介绍了Hive作为Hadoop下的查询引擎,详细解析了其CLI、Client和WebUI三种用户接口,以及Driver如何将HQL语句转换为MapReduce调用的过程。重点讲述了语义解析器如何生成执行计划,包括编译、优化和执行三个阶段。
本文介绍了Hive作为Hadoop下的查询引擎,详细解析了其CLI、Client和WebUI三种用户接口,以及Driver如何将HQL语句转换为MapReduce调用的过程。重点讲述了语义解析器如何生成执行计划,包括编译、优化和执行三个阶段。
Hive 是Apache Hadoop 项目下的一个子项目,是一个底层用Map/Reduce实现的查询引擎,具体的介绍可以查看Hive的wiki 。
入口
Hive有三种用户接口:CLI、Client(JDBC、ODBC、thrift或其他)和WebUI,如下图所示: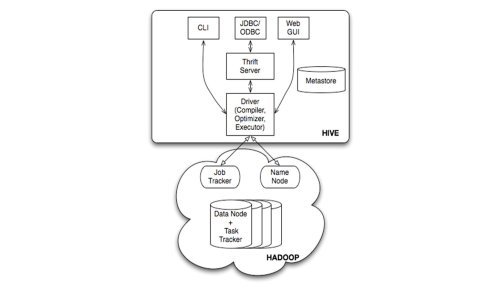
图1 Hive的入口
这些用户接口的工作是将用户输入的HQL语句解析成单条命令传递给Driver(包括用户配置,CLI还包括Session信息)。
Driver模块的工作是将HQL语句转化为MapReduce调用,包括主要的三个阶段:
编译:Compile,生成执行计划
优化:Optimize,优化执行计划(当前的Hive实现是在执行前做一次唯一的优化,没有反馈的过程,这使得优化工作只能是rule-based,做不到cost-based)。
执行:Execute,将执行计划提交给Hadoop。
本文主要记录的是Compile过程。
语义解析器
Compile过程的输入是抽象语法树(AST),输出是执行计划。这一过程由Driver调用,但是主要的逻辑在语义解析器中。语义解析器继承自BaseSemanticAnalyser,对每一种HQL命令,有对应的语义解析器类,包括下列:
表1 HQL命令对应的语义解析器
类 HQL命令类别 Task DCLSemanticAnalyzer DCL (taobao dist only) DCLTask DDLSemanticAnalyzer DDL DDLTask ExplainSemanticAnalyzer Explain ExplainTask FunctionSemanticAnalyzer FunctionTask LoadSemanticAnalyzer Load CopyTask MoveTask SemanticAnalyzer DML FetchTask ConditionalTask MapRedTask UserSemanticAnalyzer UserTask
语义解析器的工厂类SemanticAnalyzerFactory负责分发解析任务,它按照AST根节点的类别生成对应的解析器。
语义解析器部分的类图: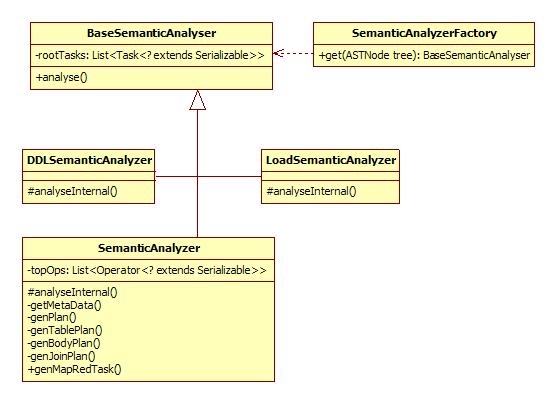
生成Operator树
下面以一个select语句为例解析Compile的过程:SELECT
s.name name, count(o.amount) sum_order, sum(o.amount) sum_amount
FROM t_sale s LEFT OUTER JOIN t_order o ON (s.id = o.sale_id)
GROUP BY s.id, s.name
如上所述,select语句由SemanticAnalyzer解析。其他的语义解析器较为简单略去不讲。这一查询语句的AST画出来类似这样:
Operator抽象了Hive中的一次操作。首先看一下上面的命令的执行计划
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-2 depends on stages: Stage-1
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-1
Map Reduce
Alias -> Map Operator Tree:
s
TableScan
alias: s
Reduce Output Operator
key expressions:
expr: id
type: int
sort order: +
Map-reduce partition columns:
expr: id
type: int
tag: 0
value expressions:
expr: id
type: int
expr: name
type: string
o
TableScan
alias: o
Reduce Output Operator
key expressions:
expr: sale_id
type: int
sort order: +
Map-reduce partition columns:
expr: sale_id
type: int
tag: 1
value expressions:
expr: amount
type: int
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join0 to 1
condition expressions:
0 {VALUE._col0} {VALUE._col1}
1 {VALUE._col4}
outputColumnNames: _col0, _col1, _col7
Select Operator
expressions:
expr: _col0
type: int
expr: _col1
type: string
expr: _col7
type: int
outputColumnNames: _col0, _col1, _col7
Group By Operator
aggregations:
expr: count(_col7)
expr: sum(_col7)
keys:
expr: _col0
type: int
expr: _col1
type: string
mode: hash
outputColumnNames: _col0, _col1, _col2, _col3
File Output Operator
compressed: false
GlobalTableId: 0
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
Stage: Stage-2
Map Reduce
Alias -> Map Operator Tree:
hdfs://hdpnn.cm3:9000/group/tbdev/shaojie/hive-tmp/1908438422/10002
Reduce Output Operator
key expressions:
expr: _col0
type: int
expr: _col1
type: string
sort order: ++
Map-reduce partition columns:
expr: _col0
type: int
expr: _col1
type: string
tag: -1
value expressions:
expr: _col2
type: bigint
expr: _col3
type: bigint
Reduce Operator Tree:
Group By Operator
aggregations:
expr: count(VALUE._col0)
expr: sum(VALUE._col1)
keys:
expr: KEY._col0
type: int
expr: KEY._col1
type: string
mode: mergepartial
outputColumnNames: _col0, _col1, _col2, _col3
Select Operator
expressions:
expr: _col1
type: string
expr: _col2
type: bigint
expr: _col3
type: bigint
outputColumnNames: _col0, _col1, _col2
File Output Operator
compressed: true
GlobalTableId: 0
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Stage: Stage-0
Fetch Operator
limit: -1
可以看到,上面的查询语句包含FilterOperator、SelectOperator等多个Operator,且Operator节点之间构成一颗Operator树。以后我们还会多次回顾这个执行计划。
PS:严格意义上的Operator节点之间的关系构成的结构是一个图。用树结构来描述语法是很自然的,例如AST,但树结构不足以描述语义,示例的 SELECT命令中,需要两次扫描表的操作,join操作需要基于扫描表的结果进行,这在Operator树中描述为“JoinOperator的父节点 为t_order表TableScan和t_sale表TableScan(多个父节点)”。
除了上述情况外,Operator树一般是退化为链表的树形结构,例外是所有的子查询又会是一颗子树。
SemanticAnalyzer通过一系列genXXXPlan方法来生成这颗Operator树。

















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









