




2025年是AI的风口,不过很多人还只是停留在简单使用ChatGPT的层面上,今天偷偷曝光了顶尖AI人才都在学的技能路线图,大家可以看一下圈内都在学习什么新技术?在当下 AI 持续进阶的浪潮中,Transformer 与 Python 的技术地位依旧稳固且不断拓展。
Transformer 自问世以来,便革新了序列数据处理方式。其自注意力机制摒弃传统循环与卷积连接,高效捕捉长距离依赖关系,成为众多 AI 应用的中流砥柱。近期,相关研究更是成果斐然。有团队引入动态双曲正切函数(DyT)替代归一化层,让无需归一化的 Transformer 模型在多种任务中性能超越传统模型。在视觉领域,基于 Transformer 的分割技术不断演进,新方法在非铺装路面、高分辨率遥感影像及视频语义分割等方面表现卓越;还有研究提出动态局部增强模块(DLE)和一元共现激励模块(UCE),增强了 Transformer 对局部特征的捕捉能力。不仅如此,UIUC、斯坦福与哈佛联合提出的能量驱动 Transformer(EBT),突破传统前馈推理模式,以能量最小化模拟人类深度思考,训练更高效、推理更精准,在多模态任务中展现出强大扩展性能。
Python 作为 AI 开发的首选语言,凭借简洁语法与丰富第三方库,贯穿 AI 开发全流程。从数据预处理、模型搭建到部署,开发者借助 NumPy、SciPy 进行科学计算,利用 TensorFlow、PyTorch 搭建深度学习模型,依靠 NLTK、SpaCy 处理自然语言。2024 年,Python 在 TIOBE 指数中优势显著,在 GitHub 上使用量稳居榜首,其在 AI 领域的核心地位愈发凸显。
展望未来,Transformer 有望在多模态融合、模型架构优化等方向取得更大突破;Python 也将随社区发展,持续推出新库与特性,更好适配 AI 复杂需求。为此,我们精心设计以下四门课程:
🌟 课程一:第十期:2025最新AI-Python机器学习与深度学习实践技术应用培训班 时间:2025年8月25日-28日 培训方式:【腾讯会议直播】 🌟 课程二:第八期:2025最新Transformer模型及深度学习前沿技术应用高级培训班 时间:2025年9月12日-15日 培训方式:【腾讯会议直播】 🌟 课程三:第十三期:破“卷”立新-国自然、省级基金项目撰写技巧全流程实战培训班 时间:2025年8月30日-31日 培训方式:【腾讯会议直播】 🌟 课程四:第四期:高水平学术论文写作的“破局”之道暨ai支持下的高分scl论文前期准备、写作、高质量图表制作、投稿技巧一站式提升高级培训班 时间:2025年9月5日-6日、12日-13日 培训方式:【腾讯会议直播】 📚 课程一 📢 近年来,人工智能技术的迅猛发展,尤其是以ChatGPT和DeepSeek为代表的大语言模型的广泛应用,正在重塑科研范式与技术实践方式。大型语言模型不仅在自然语言处理领域取得突破,也日益成为助力Python编程、加速机器学习与深度学习项目落地的重要工具。与此同时,以PyTorch为代表的深度学习框架,凭借其灵活、高效、易扩展的特性,持续受到科研人员和工程师的青睐。 为了帮助科研工作者、工程师及AI从业者全面掌握前沿大语言模型的能力,深入理解并实践Python编程与深度学习方法,Ai尚研修特别推出【2025最新ChatGPT和DeepSeek等大语言模型助力Python编程、机器学习与深度学习实践技术应用培训班】。本培训班融合最新技术动态与实战经验,旨在系统提升学员以下能力:(1)掌握ChatGPT、DeepSeek等大语言模型在代码生成、模型调试、实验设计、论文撰写等方面的实际应用技巧;(2)深入理解深度学习与经典机器学习算法的关联与差异,掌握其理论基础;(3)熟练运用PyTorch实现各类深度学习模型,包括迁移学习、循环神经网络(RNN)、长短时记忆网络(LSTM)、时间卷积网络(TCN)、自编码器、生成对抗网络(GAN)、YOLO目标检测等前沿技术。 培训课程采用“理论讲解 + 案例实战 + 动手实操 + 互动讨论”四位一体的教学模式,不仅重视知识传授,更注重技能落地与解决实际问题的能力培养。通过本次培训,学员将系统掌握从大语言模型到深度学习模型的全链路技术路径,提升科研创新力与工程实战力,在高水平项目攻坚和论文产出中实现突破。 无论您是科研人员、工程师,还是希望拥抱AI未来的技术从业者,本次培训班都将为您提供一场高价值、高密度的学习体验,助您在智能时代实现技术跃升与职业进阶。 📅 培训时间 培训方式:腾讯会议直播 直播时间:2025年8月25日-28日(腾讯会议直播) 📋 课程内容简要 第一章 ChatGPT与DeepSeek等大语言模型助力AI编程必备技能详解 1、大语言模型提示词(Prompt)撰写技巧(为ChatGPT设定身份、明确任务内容、提供任务相关的背景、举一个参考范例、指定返回的答案格式等) 2、Cursor与Trae等AI编程开发环境简介与演示 3、利用ChatGPT和DeepSeek上传本地数据(Excel/CSV表格、txt文本、PDF、图片等) 4、利用ChatGPT和DeepSeek实现描述性统计分析(数据的频数分析:统计直方图;数据的集中趋势分析:数据的相关分析) 5、利用ChatGPT和DeepSeek实现数据预处理(数据标准化与归一化、数据异常值与缺失值处理、数据离散化及编码处理、手动生成新特征)代码自动生成运行 6、利用ChatGPT和DeepSeek实现代码逐行讲解 7、利用ChatGPT和DeepSeek实现代码Bug调试与修改 8、实操练习 第二章 Python基础知识串讲 1、Python环境搭建(Python软件下载、安装与版本选择;PyCharm下载、安装;Python之Hello World;第三方模块的安装与使用;Python 2.x与Python 3.x对比) 2、Python基本语法(Python变量命名规则;Python基本数学运算;Python常用变量类型的定义与操作;Python程序注释) 3、Python流程控制(条件判断;for循环;while循环;break和continue关键字;嵌套循环与可变循环) 4、Python函数与对象(函数的定义与调用;函数的参数传递与返回值;变量作用域与全局变量;对象的创建与使用) 5、Matplotlib的安装与图形绘制(设置散点、线条、坐标轴、图例、注解等属性;绘制多图;图的嵌套) 6、科学计算模块库(Numpy的安装;ndarray类型属性与数组的创建;数组索引与切片;Numpy常用函数简介与使用;Pandas常用函数简介与使用) 7、实操练习 第三章PyTorch简介与环境搭建 1、深度学习框架概述(PyTorch、Tensorflow、Keras等) 2、PyTorch简介(PyTorch的版本、动态计算图与静态计算图、PyTorch的优点) 3、PyTorch的安装与环境配置(Pip vs. Conda包管理方式、验证是否安装成功、CPU版与GPU版的安装方法) 4、实操练习 第四章 PyTorch编程入门与进阶 1、张量(Tensor)的定义,以及与标量、向量、矩阵的区别与联系) 2、张量(Tensor)的常用属性与方法(dtype、device、layout、requires_grad、cuda等) 3、张量(Tensor)的创建(直接创建、从numpy创建、依据数值创建、依据概率分布创建) 4、张量(Tensor)的运算(加法、减法、矩阵乘法、哈达玛积(element wise)、除法、幂、开方、指数与对数、近似、裁剪) 5、张量(Tensor)的索引与切片 6、PyTorch的自动求导(Autograd)机制与计算图的理解 7、PyTorch常用工具包及API简介(torchvision(transforms、datasets、model)、torch.nn、torch.optim、torch.utils(Dataset、DataLoader)) 8、实操练习 第五章 ChatGPT和DeepSeek等大语言模型助力统计分析与可视化 1、统计数据的描述与可视化(数据的描述性统计:均值、中位数、众数、方差、标准差、极差、四分位数间距等;条形图、直方图、散点图、箱线图等) 2、概率分布与统计推断(离散概率分布:二项分布、泊松分布;连续概率分布:正态分布、均匀分布、指数分布;点估计与区间估计;最大似然估计与贝叶斯估计;假设检验:t检验、卡方检验、F检验;P值与显著性水平等) 3、回归分析(多元线性回归模型;最小二乘法估计;变量选择与模型优化;多重共线性与解决方法;Ridge回归;LASSO回归;ElasticNet回归等) 4、案例讲解:利用ChatGPT和DeepSeek实现统计分析与可视化代码的自动生成与运行 5、实操练习 第六章 ChatGPT和DeepSeek等大语言模型助力前向型神经网络 1、BP神经网络的基本原理(人工神经网络的分类有哪些?有导师学习和无导师学习的区别是什么?BP神经网络的拓扑结构和训练过程是怎样的?什么是梯度下降法?BP神经网络建模的本质是什么?) 2、BP神经网络的Python代码实现(怎样划分训练集和测试集?为什么需要归一化?归一化是必须的吗?什么是梯度爆炸与梯度消失?) 3、PyTorch代码实现神经网络的基本流程(Data、Model、Loss、Gradient)及训练过程(Forward、Backward、Update) 4、案例讲解:Linear模型、Logistic模型、Softmax函数输出、BP神经网络 5、值得研究的若干问题(隐含层神经元个数、学习率、初始权值和阈值等如何设置?什么是交叉验证?过拟合(Overfitting)与欠拟合(Underfitting)、泛化性能评价指标的设计、样本不平衡问题、模型评价与模型选择等) 6、利用ChatGPT和DeepSeek实现BP神经网络模型的代码自动生成与运行 7、实操练习 第七章 ChatGPT和DeepSeek等大语言模型助力决策树、随机森林、XGBoost与LightGBM 1、决策树的工作原理(微软小冰读心术的启示;什么是信息熵和信息增益?ID3算法和C4.5算法的区别与联系);决策树除了建模型之外,还可以帮我们做什么事情? 2、随机森林的工作原理(为什么需要随机森林算法?广义与狭义意义下的“随机森林”分别指的是什么?“随机”体现在哪些地方?随机森林的本质是什么?怎样可视化、解读随机森林的结果?) 3、Bagging与Boosting的区别与联系 4、AdaBoost vs. Gradient Boosting的工作原理 5、常用的GBDT算法框架(XGBoost、LightGBM) 6、决策树、随机森林、XGBoost、LightGBM中的ChatGPT提示词库讲解 7、案例讲解:利用ChatGPT和DeepSeek实现决策树、随机森林、XGBoost、LightGBM模型的代码自动生成与运行 8. 实操练习 第八章 ChatGPT和DeepSeek等大语言模型助力变量降维与特征选择 1、主成分分析(PCA)的基本原理 2、偏最小二乘(PLS)的基本原理 3、常见的特征选择方法(优化搜索、Filter和Wrapper等;前向与后向选择法;区间法;无信息变量消除法;正则稀疏优化方法等) 4、遗传算法(Genetic Algorithm, GA)的基本原理(以遗传算法为代表的群优化算法的基本思想是什么?选择、交叉、变异三个算子的作用分别是什么?) 5、SHAP法解释特征重要性与可视化(Shapley值的定义与计算方法、SHAP值的可视化与特征重要性解释) 6、案例讲解:利用ChatGPT和DeepSeek实现变量降维与特征选择的代码自动生成与运行 7、实操练习 第九章 ChatGPT和DeepSeek等大语言模型助力卷积神经网络 1、深度学习简介(深度学习大事记:Model + Big Data + GPU + AlphaGo) 2、深度学习与传统机器学习的区别与联系(神经网络的隐含层数越多越好吗?深度学习与传统机器学习的本质区别是什么?) 2、卷积神经网络的基本原理(什么是卷积核、池化核?CNN的典型拓扑结构是怎样的?CNN的权值共享机制是什么?CNN提取的特征是怎样的?) 3、卷积神经网络的进化史:LeNet、AlexNet、Vgg-16/19、GoogLeNet、ResNet等经典深度神经网络的区别与联系 4、利用PyTorch构建卷积神经网络(Convolution层、Batch Normalization层、Pooling层、Dropout层、Flatten层等) 5、卷积神经网络调参技巧(卷积核尺寸、卷积核个数、移动步长、补零操作、池化核尺寸等参数与特征图的维度,以及模型参数量之间的关系是怎样的?) 6、案例讲解与实践:利用ChatGPT和DeepSeek实现卷积神经网络模型的代码自动生成与运行 (1)CNN预训练模型实现物体识别 (2)利用卷积神经网络抽取抽象特征 (3)自定义卷积神经网络拓扑结构 7、实操练习 第十章 ChatGPT和DeepSeek等大语言模型助力迁移学习 1、迁移学习算法的基本原理(为什么需要迁移学习?为什么可以迁移学习?迁移学习的基本思想是什么?) 2、基于深度神经网络模型的迁移学习算法 3、案例讲解:利用ChatGPT和DeepSeek实现迁移学习的代码自动生成与运行 4、实操练习 第十一章 ChatGPT和DeepSeek等大语言模型助力生成式对抗网络 1、生成式对抗网络GAN(什么是对抗生成网络?为什么需要对抗生成网络?对抗生成网络可以帮我们做什么?GAN给我们带来的启示) 2、GAN的基本原理及GAN进化史 3、案例讲解:利用ChatGPT和DeepSeek实现GAN的代码自动生成与运行 4、实操练习 第十二章 ChatGPT和DeepSeek等大语言模型助力RNN与LSTM 1、循环神经网络RNN的基本工作原理 2、长短时记忆网络LSTM的基本工作原理 3、案例讲解:利用ChatGPT和DeepSeek实现LSTM神经网络模型的代码自动生成与运行 4、实操练习 第十三章 ChatGPT和DeepSeek等大语言模型助力时间卷积网络 1、时间卷积网络(TCN)的基本原理 2、TCN与1D CNN、LSTM的区别与联系 3、案例讲解:利用ChatGPT和DeepSeek实现TCN模型的代码自动生成与运行 1)时间序列预测:新冠肺炎疫情预测 2)序列-序列分类:人体动作识别 4、实操练习 第十四章 ChatGPT和DeepSeek等大语言模型助力目标检测 1、什么是目标检测?目标检测与目标识别的区别与联系 2、YOLO模型的工作原理,YOLO模型与传统目标检测算法的区别 3、案例讲解:利用ChatGPT和DeepSeek实现YOLO的代码自动生成与运行 (1)利用预训练好的YOLO模型实现目标检测(图像检测、视频检测、摄像头实时检测) (2)数据标注演示(LabelImage使用方法介绍) (3)训练自己的目标检测数据集 4、实操练习 第十五章 ChatGPT和DeepSeek等大语言模型助力自编码器 1、什么是自编码器(Auto-Encoder, AE)? 2、经典的几种自编码器模型原理介绍(AE、Denoising AE, Masked AE) 3、案例讲解:利用ChatGPT和DeepSeek实现自编码器的代码自动生成与运行 (1)基于自编码器的噪声去除 (2)基于自编码器的手写数字特征提取与重构 (3)基于掩码自编码器的缺失图像重构 4、实操练习 第十六章 ChatGPT和DeepSeek等大语言模型助力U-Net语义分割 1、语义分割(Semantic Segmentation)简介 2、U-Net模型的基本原理 3、案例讲解:利用ChatGPT和DeepSeek实现U-Net语义分割模型的代码自动生成与运行 4、实操练习 第十七章 复习与答疑讨论 1、课程相关资料拷贝与分享 2、答疑与讨论(大家提前把问题整理好) 📞 报名咨询 联系人:王倩 微信二维码: 📚 课程二 📢 近年来,伴随着以卷积神经网络(CNN)为代表的深度学习的快速发展,人工智能迈入了第三次发展浪潮,AI技术在各个领域中的应用越来越广泛。为了帮助广大学员更加深入地学习人工智能领域最近3-5年的新理论与新技术,Ai尚研修推出全新的“Python深度学习进阶与应用”培训课程,让你系统掌握AI新理论、新方法及其Python代码实现。课程采用“理论讲解+案例实战+动手实操+讨论互动”相结合的方式,抽丝剥茧、深入浅出讲解注意力机制、Transformer模型(BERT、GPT-1/2/3/3.5/4、DETR、ViT、Swin Transformer等)、生成式模型(变分自编码器VAE、生成式对抗网络GAN、扩散模型Diffusion Model等)、目标检测算法(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SDD等)、图神经网络(GCN、GAT、GIN等)、强化学习(Q-Learning、DQN等)、深度学习模型可解释性与可视化方法(CAM、Grad-CAM、LIME、t-SNE等)的基本原理及Python代码实现方法。(备注:该培训课程为进阶课程,需要学员掌握卷积神经网络、循环神经网络等前序基础知识。同时,应具备一定的Python编程基础,熟悉numpy、pandas、matplotlib、scikit-learn、pytorch等第三方模块库。)现通知如下: 📅 培训时间 培训方式:线上直播 直播时间:2025年9月12日-15日(腾讯会议直播) 📋 课程内容简要 课程安排 课程导学 第一章 注意力(Attention)机制详解 1、注意力机制的背景和动机(为什么需要注意力机制?注意力机制的起源和发展里程碑)。 2、注意力机制的基本原理(什么是注意力机制?注意力机制的数学表达与基本公式、用机器翻译任务带你了解Attention机制、如何计算注意力权重?) 3、注意力机制的主要类型:键值对注意力机制(Key-Value Attention)、自注意力(Self-Attention)与多头注意力(Multi-Head Attention)、Soft Attention 与 Hard Attention、全局(Global)与局部(Local)注意力 4、注意力机制的优化与变体:稀疏注意力(Sparse Attention)、自适应注意力(Adaptive Attention)、动态注意力机制(Dynamic Attention)、跨模态注意力机制(Cross-Modal Attention) 5、注意力机制的可解释性与可视化技术:注意力权重的可视化(权重热图) 6、案例演示 7、实操练习 第二章 自然语言处理(NLP)领域的Transformer模型详解 1、Transformer模型的提出背景(从RNN、LSTM到注意力机制的演进、Transformer模型的诞生背景及其在自然语言处理和计算视觉中的重要性) 2、Transformer模型的进化之路(RCTM→RNN Encoder-Decoder→Bahdanau Attention→Luong Attention→Self Attention) 3、Transformer模型拓扑结构(编码器、解码器、多头自注意力机制、前馈神经网络、层归一化和残差连接等) 4、Transformer模型工作原理(输入数据的Embedding、位置编码、层规范化、带掩码的自注意力层、编码器到解码器的多头注意力层、编码器的完整工作流程、解码器的完整工作流程、Transformer模型的损失函数) 5、BERT模型的工作原理(输入表示、多层Transformer编码器、掩码语言模型MLM、下一句预测NSP) 6、GPT系列模型(GPT-1 / GPT-2 / GPT-3 / GPT-3.5 / GPT-4)的工作原理(单向语言模型、预训练、自回归生成、Zero-shot Learning、上下文学习、RLHF人类反馈强化学习、多模态架构) 7、案例演示 8、实操练习 第三章 计算视觉(CV)领域的Transformer模型详解 1、ViT模型(提出的背景、基本架构、与传统CNN的比较、输入图像的分块处理、位置编码、Transformer编码器、分类头、ViT模型的训练与优化、ViT模型的Python代码实现) 2、Swin Transformer模型(提出的背景、基本架构、与ViT模型的比较、分层架构、窗口机制、位置编码、Transformer编码器、模型的训练与优化、模型的Python代码实现) 3、DETR模型(提出的背景、基本架构、与RCNN、YOLO系列模型的比较、双向匹配损失与匈牙利匹配算法、匹配损失与框架损失、模型的训练与优化、模型的Python代码实现) 4、案例演示 5、实操练习 第四章 时间序列建模与预测的大语言模型 1、时间序列建模的大语言模型技术细节(基于Transformer的时间序列预测原理、自注意力机制、编码器-解码器结构、位置编码) 2、时间序列建模的大语言模型训练 3、Time-LLM模型详解(拓扑结构简介、重新编程时间序列输入、Prompt-as-Prefix (PaP)等) 4、基于TimeGPT的时间序列预测(TimeGPT工作原理详解、TimeGPT库的安装与使用) 5、案例演示与实操练习 第五章 目标检测算法详解 1、目标检测任务与图像分类识别任务的区别与联系。 2、两阶段(Two-stage)目标检测算法:R-CNN、Fast R-CNN、Faster R-CNN(RCNN的工作原理、Fast R-CNN和Faster R-CNN的改进之处 )。 3、一阶段(One-stage)目标检测算法:YOLO模型、SDD模型(拓扑结构及工作原理)。 4、案例演示 5、实操练习 第六章 目标检测的大语言模型 1、基于大语言模型的目标检测的工作原理(输入图像的特征提取、文本嵌入的生成、视觉和语言特征的融合、目标检测与输出) 2、目标检测领域的大语言模型概述(Pix2Seq、Grounding DINO、Lenna等) 3、案例演示与实操练习 第七章 语义分割的大语言模型 1、基于大语言模型的语义分割的工作原理(图像特征提取、文本嵌入生成、跨模态融合、分割预测) 2、语义分割领域的大语言模型概述(ProLab、Segment Anything Model、CLIPSeg、Segment Everything Everywhere Model等) 3、案例演示与实操练习 第八章 LLaVA多模态大语言模型详解 1、LLaVA的核心技术与工作原理(模型拓扑结构讲解) 2、LLaVA与其他多模态模型的区别(LLaVA模型的优势有哪些?) 3、LLaVA的架构与训练(LLaVA的多模态输入处理与特征表示、视觉编码器与语言模型的结合、LLaVA的训练数据与预训练过程) 4、LLaVA的典型应用场景(图像问答、图像生成与描述等) 5、案例演示与实操练习 第九章 物理信息神经网络 (PINN) 1、物理信息神经网络的背景(物理信息神经网络(PINNs)的概念及其在科学计算中的重要性、传统数值模拟方法与PINNs的比较) 2、PINN工作原理:物理定律与方程的数学表达、如何将物理定律嵌入到神经网络模型中?PINN的架构(输入层、隐含层、输出层的设计)、物理约束的形式化(如何将边界条件等物理知识融入网络?)损失函数的设计(数据驱动与物理驱动的损失项) 3、案例演示4、实操练习 第十章 生成式模型详解 1、变分自编码器VAE(自编码器的基本结构与工作原理、降噪自编码器、掩码自编码器、变分推断的基本概念及其与传统贝叶斯推断的区别、VAE的编码器和解码器结构及工作原理)。 2、生成式对抗网络GAN(GAN提出的背景和动机、GAN的拓扑结构和工作原理、生成器与判别器的角色、GAN的目标函数、对抗样本的构造方法)。 3、扩散模型Diffusion Model(扩散模型的核心概念?如何使用随机过程模拟数据生成?扩散模型的工作原理)。 4、跨模态图像生成DALL.E(什么是跨模态学习?DALL.E模型的基本架构、模型训练过程)。 5、案例演示 6、实操练习 第十一章 自监督学习模型详解 1、自监督学习的基本概念(自监督学习的发展背景、自监督学习定义、与有监督学习和无监督学习的区别) 2、经典的自监督学习模型的基本原理、模型架构及训练过程(对比学习: SimCLR、MoCo;生成式方法:AutoEncoder、GPT;预文本任务:BERT掩码语言模型) 3、自监督学习模型的Python代码实现 4、案例演示 5、实操练习 第十二章 图神经网络详解 1、图神经网络的背景和基础知识(什么是图神经网络?图神经网络的发展历程?为什么需要图神经网络?) 2、图的基本概念和表示(图的基本组成:节点、边、属性;图的表示方法:邻接矩阵;图的类型:无向图、有向图、加权图)。 3、图神经网络的工作原理(节点嵌入和特征传播、聚合邻居信息的方法、图神经网络的层次结构)。 4、图卷积网络(GCN)的工作原理。 5、图神经网络的变种和扩展:图注意力网络(GAT)、图同构网络(GIN)、图自编码器、图生成网络。 6、案例演示 7、实操练习 第十三章 强化学习详解 1、强化学习的基本概念和背景(什么是强化学习?强化学习与其他机器学习方法的区别?强化学习的应用领域有哪些? 2、Q-Learning(马尔可夫决策过程、Q-Learning的核心概念、什么是Q函数?Q-Learning的基本更新规则)。 3、深度Q网络(DQN)(为什么传统Q-Learning在高维或连续的状态空间中不再适用?如何使用神经网络代替Q表来估计Q值?目标网络的作用及如何提高DQN的稳定性?) 4、案例演示 5、实操练习 第十四章 深度学习模型可解释性与可视化方法详解 1、什么是模型可解释性?为什么需要对深度学习模型进行解释? 2、可视化方法有哪些(特征图可视化、卷积核可视化、类别激活可视化等)? 3、类激活映射CAM(Class Activation Mapping)、梯度类激活映射GRAD-CAM、局部可解释模型-敏感LIME(Local Interpretable Model-agnostic Explanation)、等方法原理讲解。 4、t-SNE的基本概念及使用t-SNE可视化深度学习模型的高维特征。 5、案例演示 6、实操练习 第十五章 神经架构搜索(Neural Architecture Search, NAS) 1、NAS的背景和动机(传统的神经网络设计依赖经验和直觉,既耗时又可能达不到最优效果。通过自动搜索,可以发现传统方法难以设计的创新和高效架构。) 2、NAS的基本流程:搜索空间定义(确定搜索的网络架构的元素,如层数、类型的层、激活函数等。)、搜索策略(随机搜索、贝叶斯优化、进化算法、强化学习等)、性能评估 3、NAS的关键技术:进化算法(通过模拟生物进化过程,如变异、交叉和选择,来迭代改进网络架构)、强化学习(使用策略网络来生成架构,通过奖励信号来优化策略网络)、贝叶斯优化(利用贝叶斯方法对搜索空间进行高效的全局搜索,平衡探索和利用) 4、案例演示5、实操练习 第十六章 讨论与答疑 1、相关学习资料分享与拷贝(图书推荐、在线课程推荐等) 2、建立微信群,便于后期的讨论与答疑 📞 报名咨询 联系人:王倩 微信二维码: 📚 课程三




📢 在社会经济蓬勃发展和人工智能时代全面到来的背景下,基金项目对创新性的要求日益严格。国家级和省级等各类项目的申请络绎不绝,项目书的撰写几乎占据了申请人全年的时间。申请人不仅需要提出独特且具有前瞻性的研究问题,展现突破性的科学思路和方法,还需紧跟国际前沿研究动态,积极参与国际合作项目,并充分展示项目对国际学术和科技发展的贡献。
面对时间紧迫、竞争激烈、标准严苛的三大挑战,尤其是青年学者,他们工作繁重、资源有限、缺乏基金申请经验,且尚未形成高效的研究团队。在当前激烈的竞争环境下,仅凭个人之力显然难以取得优势。基金申请作为每年学者的重要工作内容,需要投入大量的时间和精力,但许多人往往在提交前集中有限的时间进行撰写,结果往往不尽如人意。
在您的基金撰写过程中,是否遇到了以下问题:如何撰写摘要才能给评阅专家留下美好的第一印象?如何设计技术路线图才能吸引评阅专家的目光?如何区分难点问题和关键科学问题?每个章节应该突出哪些内容才能使项目书更加清晰明了?应广大学者的要求,Ai尚研修特举办“2025年科研项目基金撰写要点及技巧培训班”,现将相关事宜通知如下:
👍 学员好评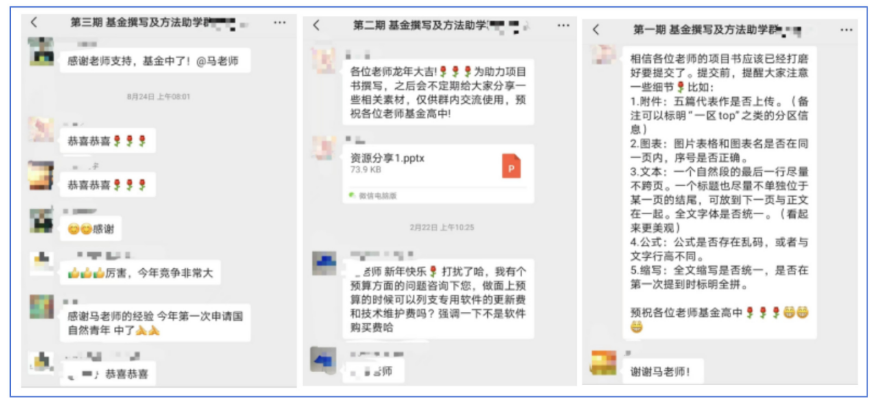
📅 培训时间
培训方式:腾讯会议直播
直播时间:2025年8月30日-31日(腾讯会议直播)
📋 课程内容简要
专题一 国自然/省级/博后项目介绍 | 1.1项目介绍 1.2接收情况 1.3受理情况 1.4近五年资助情况 1.5国自然项目解读 1.6省级项目解读 1.7博后项目介绍 |
专题二 基金的撰写技巧及AI融合应用 (从申请人的角度,带你一次入门) | 2.1 问题属性与评阅标准 2.2 前期准备工作- 2.2.1 如何去选题 2.2.2 AI大语言模型推荐研究方向 2.2.3 AI大语言模型助力高效搜索 2.2.4 AI大语言模型梳理文献 2.3 项目撰写 2.3.1 题目的设计 2.3.1.1题目确定:如何设计一个合适的题目 2.3.1.2 AI大语言模型选择基金题目 2.3.1.3 AI大语言模型生成基金提纲 2.3.2 立项依据 2.3.2.1 立项依据的四段式结构 2.3.2.2立项依据的五方面注意事项 2.3.2.3 AI大语言模型形成文献综述 2.3.2.4 AI大语言模型搜索关键图片 2.3.2.5 典型例子分析 2.3.3 项目的研究内容、研究目标,以及拟解决的关键科学问题 2.3.3.1 研究内容的四点注意事项 2.3.3.2 研究目标如何精准定位 2.3.3.3 关键科学问题的提炼方法-一个行之有效的小技巧 2.3.3.4 成功模版分享 2.3.3.5 典型例子分析 2.3.4 拟采取的研究方案及可行性分析 2.3.4.1 研究方案:如何安排总述与总图 2.3.4.2技术路线:如何将技术细节做到一一对应 2.3.4.3 可行性分析:如何通过三个维度分析到位 2.3.4.4 成功模版分享 2.3.4.5 AI大语言模型扩写/缩写基金内容 2.3.4.6 AI大语言模型降重文本内容 2.3.4.7 典型例子分析 2.3.5 本项目的特色与创新之处 2.3.5.1 多角度分析思路 2.3.5.2成功模版分享 2.3.5.3 AI大语言模型润色基金文字 2.3.5.4 AI大语言模型仿写指定风格 2.3.6 年度研究计划与预期成果: 2.3.6.1 研究计划如何布局推进 2.3.6.2 预期成果有哪些细微区别 2.3.6.3成功模版分享 2.3.7 研究基础与工作条件 2.3.7.1 研究基础-如何突出与代表作的联系 2.3.7.2工作条件-如何充分展现平台优势 2.3.8 其他注意事项 2.3.8.1 项目书撰写建议 |
专题三 基金的专项技巧及AI融合应用 (从评审专家的角度,带您逐一突破) | 3.1 了解评审专家的视角 3.1.1 专家视角分析 3.1.2 AI大语言模型分析评审意见 3.2 最关键的细节 3.2.1 摘要的写法 3.2.2 AI大语言模型助力摘要书写 3.3 如何挑选的五篇代表作 3.4 手把手带你画技术路线图 3.5 如何合理安排研究经费 3.6往期学员汇总问题解析 3.7最后的自查-自查十连问 |
问卷主题 | 问卷归纳 |
项目的立项依据(附主要的参考文献目录) | ·选题:选题的切入点如何找? ·立项依据: 立项依据中是否必须基于之前的青年基金研究内容及成果展开? 立项依据的具体撰写方法? 立项依据和可行性分析内容上是不是有交叉重叠? ·参考文献: 参考文献特别少? |
项目的研究内容、研究目标,以及拟解决的关键问题 | ·研究内容: 项目的研究内容控制在4个方面还是3个方面好? 面上的内容需要多少? 研究内容写的有点多? 怎么看我的研究内容逻辑是否连贯,视角是否新颖?什么样的本子算是好本子? ·研究目标: 容易把研究内容和研究目标的界限混淆,或者二者之间脱节、连贯性不强 ·科学问题: 关键科学问题标题总觉得起的不好,内容也不够精炼有逻辑。 如何写拟解决的关键问题?是否和背景写的科学问题是一样的?科学假说怎么写如何凝练科学问题找创新? |
拟采取的研究方案及可行性分析 | ·详细程度: 研究方案要多详细有多详细吗,几页合适呢? 不知深入到哪种程度去说明? ·亮点设计: 研究方案如何写精彩?怎么表述,怎么把这部分内容写精彩?研究的方法、实施方案如何撰写? ·其他: 创新点如何在研究方案中体现?不确定什么样的课题框架算是论证严密逻辑可行!研究内容与研究方案每一条前后逻辑不紧密怎么写方案不暴露自己的弱点? |
本项目的特色与创新之处 | ·特色: 想更清楚了解写法,怎么写更有特色,更吸引评审专家交叉学科如何体现特色?如何写出本子的特色? ·创新: 创新点凝练不够?创新点怎么写? 搞不清楚,做到哪种程度算得上创新?研究内容、拟解决的关键科学问题、创新点如何体现先进性和创新性。 |
年度研究计划及预期研究结果 | |
研究基础与工作条件 | ·代表作: 代表作不足,论文质量较差,本子创新性不足? 学术专著对课题申报的重要程度? MDPI的文章能否作为5篇代表作上传? scientific reports第一通讯能否作为代表作? 是不是sci只有两个的希望不大?还有青基需要避雷的地方 ·研究团队与基础: 如果基金中有一些内容是拓展研究且目前团队无相关研究基础,该怎么论述才能避免评审专家的差评? 研究团队人员如何组合好? 双非学校的青椒申请面上,怎么写研究基础能避免劣势? 研究基础只有文献支持可不可以? ·工作条件: 申请地区项目的工作条件可写博后(在职)单位吗? |
其他 | 如何根据项目内容选择合适的投送代码?副教授是否可以申请2个学部? 迷惑: 准备报国自然基金,但是没经验,也没做过国家级课题,不知道应该怎么写如何提升基金项目的命中率?字数超了会不会影响很大? |
📞 报名咨询 联系人:王倩 微信二维码:
📚 课程四

📢 SCI论文写作是科学研究成果传播和学术交流的重要途径,不仅是研究者展示创新性和学术贡献的核心方式,也是提升个人学术影响力和职业发展的关键手段。本课程对SCI论文从准备到投稿全流程进行讲解,包括文献检索和计量分析(VOSViewer、R bibliometrix)、文献高效管理(Endnote、Connected papers)、文献动态跟踪工具使用、论文问题切入点和想法idea提炼、论文框架和行文设计、论文图表设计和组合(R、Python)、各个板块(题目、摘要、引言、材料与方法、结果、讨论、结论)段落、句子的设计和布局、cover letter的写作模板、语法检查(Grammarly)、语言润色(chatGPT)、Graphical Abstract准备、Nature、Science及其子刊和顶刊的不同写作套路转换、目标期刊的研究和分析、不同风格投稿系统准备、理解同行审稿机制、修改意见处理等。全过程通过AI大模型辅助,提升SCI论文的写作效率和投稿命中率。
强基础:前期准备与工具使用 养习惯:SCI文献追踪与科研思维养成
学套路:SCI论文写作技巧 装门面:高质量的图表制作和排版
再提升:论文润色、自我审稿和复查 善投稿:目标期刊选择和投稿系统熟悉
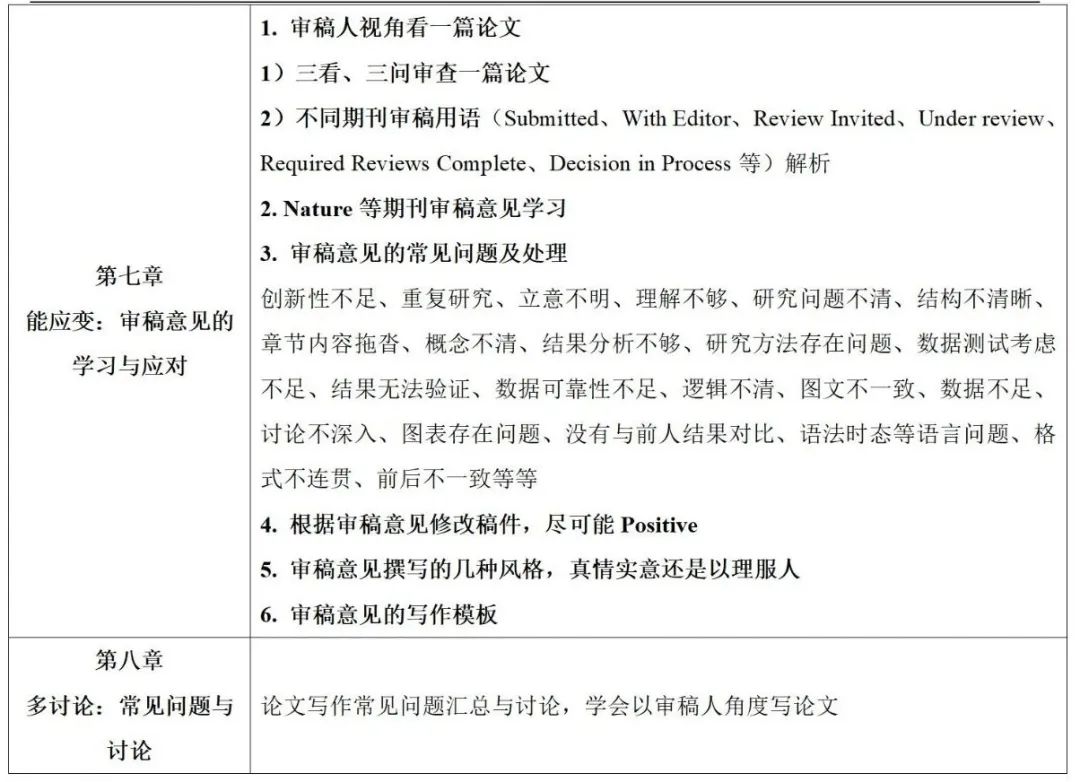
能应变:审稿意见的学习与应对 多讨论:常见问题与讨论
📅 培训时间 培训方式:腾讯会议直播 直播时间:2025年9月5日-6日、12日-13日 📋 课程内容简要 上下滑动查看更多内容 📞 报名咨询 联系人:王倩 微信二维码:




📂视频课程系列推荐
名师指导

提供全套上课资料【课件、案例数据、代码、参考资料等】+课程长期有效+导师群长期辅助学习
🔬生物科研服务

💻洪水淹没软件与慧天软件

📲 报名咨询
联系人:王倩
微信二维码:

END
END
Ai尚研修丨专注科研领域
技术推广,人才招聘推荐,科研活动服务
科研技术云导师,Easy Scientific Research`


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









