




 介绍了一款用于从Google搜索引擎批量下载图片的工具,支持指定图片分辨率及数量,详细步骤包括安装配置、参数设置及常见问题解决,如使用chromedriver应对下载数量限制。
介绍了一款用于从Google搜索引擎批量下载图片的工具,支持指定图片分辨率及数量,详细步骤包括安装配置、参数设置及常见问题解决,如使用chromedriver应对下载数量限制。
爬取Google搜索引擎图片的工具,工具链接如下:
https://github.com/hardikvasa/google-images-download
该工具的好处是可以指定下载图片分辨率以及下载图片的张数。
1.使用:
(a)clone 项目到本地
(b)进行相关配置:
(1)pip install google_images_download
(2)cd google_images_download
(3) sudo python setup.py install
(c) cd google-images-download
(d) python google_images_download.py -k makeup -l 500 -s '>4MP'
附录:
笔者使用的是-k,-l,-s这三个参数传入.py文件,也可以选择其它参数。
参数查询文档如下:
https://google-images-download.readthedocs.io/en/latest/arguments.html
2.可能遇到的问题:
(a)参数设置问题:
1.错误:-l 500 (下载期望是500张,大于默认100),错误如下图

2.解决办法:
(a)下载chrome browser 对应的chromedriver ,下载链接如下:
http://chromedriver.storage.googleapis.com/index.html
下载对应的chromedriver,笔者的chrome browser 版本是78.0.3904.108(正式版本) (64 位),下载的 chromedriver 版本是78.0.3904.105 ,对应的chromedriver 版本截图如下,由于本地是mac电脑,所以选择箭头所指的文件:
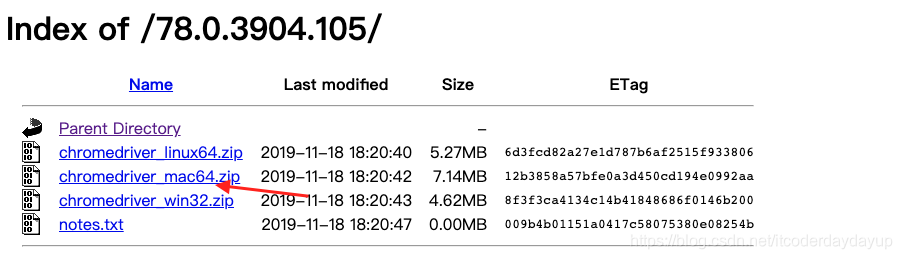
(b)将chromedriver _mac64.zip下载到本地之后解压,解压后截图如下:

(c)将解压后的chromedriver,copy到/usr/local/bin/目录下
(d) 运行python google_images_download.py -k makeup -l 500 -s '>4MP' -cd /usr/local/bin/chromedriver

















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









