




 本文深入解析Lucene的倒排索引机制,对比关系型数据库的B-tree索引,探讨Lucene如何通过TermIndex和TermDictionary实现高效检索。同时,介绍了Lucene的联合查询策略,包括SkipList和Bitmap的运用,以及RoaringBitmap的优化,揭示其在大数据量场景下的高性能表现。
本文深入解析Lucene的倒排索引机制,对比关系型数据库的B-tree索引,探讨Lucene如何通过TermIndex和TermDictionary实现高效检索。同时,介绍了Lucene的联合查询策略,包括SkipList和Bitmap的运用,以及RoaringBitmap的优化,揭示其在大数据量场景下的高性能表现。
参考文章:时间序列数据库的秘密 (2)——索引
目录
Lucene 基于倒排索引实现比关系型数据库更快的过滤,尤其是对于组合条件查询具有更快的检索速度。Lucene 的倒排索引相比于关系型数据库的 b-tree 索引快在哪里呢?简单的来说,b-tree 索引是为写入优化的索引结构,能够支持快速的更新;而 Lucene 则是通过牺牲快速更新的性能,来换取更快的检索速度和更小的储存空间。
1、Lucene 的倒排索引
Lucene的倒排索引由三部分组成:Term Index、Term Dictionary 和 Posting List。

假设我们有如下数据:
| docid | age | gender |
| 1 | 18 | female |
| 2 | 20 | male |
| 3 | 18 | male |
上表中每一行为一个document,每个 document 有一个 docid 和两列属性。对上表建立倒排索引,就是对 age 和 gender 字段做索引,即建立两个倒排索引,结果如下,注意:倒排索引不是以关系型数据库库 row 和 column 形式存储的,而是以 key-value 形式存储的,下表只是为了方便展示。
| Term | Posting List |
| 18 | [1,3] |
| 20 | [2] |
| Term | Posting List |
| female | [1] |
| male | [2,3] |
18、20、female、male就是 Term,而[1,3]、[2]、[1]、[2,3]就是 Posting List,Posting List 就是一个 int 的数组,存储了所有符合某个 Term 的 docid。那么什么是 Term Dictionary 和 Term Index呢?
假设我们有很多个 Term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena。
如果按照这样的顺序排列,找出某个特定的 Term 一定很慢,因为 Term 是没有排序的,需要全部遍历一遍才能找出特定的 Term,而将其排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标 Term。这个就是 Term Dictionary。有了 Term Dictionary 之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次 random access 大概需要 10ms 的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 Term Dictionary 本身又太大了,无法完整地放到内存里。于是就有了 Term Index,Term Index 有点像一本字典的目录,也就是说 Term Dictionary 是 Posting List 的索引,而 Term Index 是 Term Dictionary 的索引。实际的 Term Index 是一棵 trie 树:
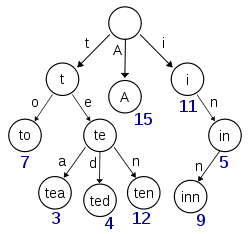
这棵树不会包含所有的 Term,它包含的是 Term 的一些前缀。通过 Term Index 可以快速地定位到 Term Dictionary 的某个 offset,然后从这个位置再往后顺序查找。再加上一些压缩技术(例如 FST,参考:还没写完,之后补,先看看其他大佬写的https://www.cnblogs.com/bonelee/p/6226185.html) Term Index 的大小可以变为所有 Term 的几十分之一,使得用内存缓存整个 Term Index 变成可能。
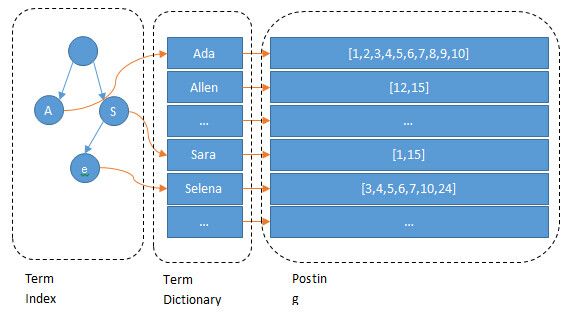
看到这里我们就明白了 Lucene 的倒排索引为什么比关系型数据库的 b-tree 索引快了。b-tree 索引只有 Term Dictionary 这一层,没有 Term Index,而且 b-tree 索引是存储在磁盘上而不是内存中的,检索一个 Term 需要若干次 random access 的磁盘操作。Lucene 通过增加 Term Index 来加速检索,而且 Term Index 是以树的形式存储在内存中的,从 Term Index 查到对应的 Term Dictionary 的 block 位置后,再去磁盘上找 Term,大大减少了磁盘的 random access 次数。
另外还有两点值得注意:
-
Term Index 在内存中是以 FST(Finite State Transducers)的形式储存的,非常节省内存。
-
Term Dictionary 在磁盘上是以分 block 的方式储存的,一个 block 内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去。这样 Term Dictionary 可以比 b-tree 更节省磁盘空间。
2、Lucene的联合查询
假设我们现在有这样一个查询:查询所有年龄为18岁的女性。假设 MysQL 对 age 和 gender 字段均做了b-tree索引,Lucene也对这两个字段做了倒排索引。
对于 MySQL 而言,查询时只会用 age 和 gender 中最 selective 的字段的索引,无法同时使用两个索引(除非你建了复合索引,这里不考虑),然后另一个字段的过滤是在遍历行的过程中执行。
对于 Lucene 而言,可以对两个字段分别查询,然后做合并操作。合并操作的实现方式有两种:skip list 和 Bitmap。
PostgreSQL 从 8.4 版本开始支持通过 Bitmap 联合使用两个索引,就是利用了 Bitmap 数据结构来做到的,一些商业的关系型数据库也支持类似的联合索引的功能。Lucene 支持以上两种的联合索引方式,如果查询的 filter 缓存到了内存中(以 Bitmap 的形式),那么合并就是两个 Bitmap 的 '与' 操作。如果查询的 filter 没有缓存,那么就用 skip list 的方式去遍历磁盘上的 两个 Posting List。
(1)Skip List
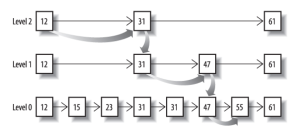
Skip List(跳表)的结构如上图所示,第三层(最下边一层)就是原始的数据,从原始数据中抽出几个构成第二层的数据,再从第二层中抽出几个构成第一层(最上层)的数据。每次从第一层数据开始遍历,假如要寻找55这个数字,首先遍历第一层,找到比55大的数,跳转到第二层(55>12 => 55>31 => 55<61,跳转到第二层的31),重复第一层的操作,直到在最后一层中找到55。常用的跳表分层可以使用每2个元素做一次分层,也可以使用自定义的分层方式。
Lucene 中对于两个或者多个 Posting List,从短的 List 开始遍历,利用跳表跳过部分元素,最终求出交集。
Lucene 对于跳表分层分出的 block(对于上图中第一层的 block 就是[12,15,23]、[31,31,47,55]、[61])也会进行相应的压缩,其压缩方式叫做 Frame Of Reference 编码,其利用增量的形式存储数据,而不是直接存储数据。示例如下,
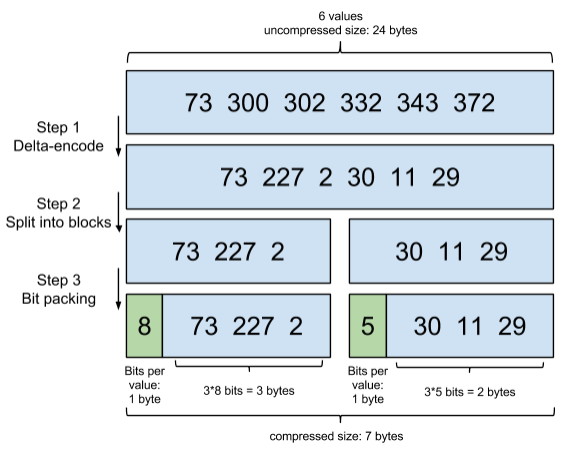
考虑到频繁出现的 Term(即 low cardinality 的值),比如 gender 里的男或者女。如果有 1 百万个文档,那么性别为男的 Posting list 里就会有 50 万个 int 值。用 Frame of Reference 编码进行压缩可以极大减少磁盘占用。这个优化对于减少索引尺寸有非常重要的意义。当然 MySQL 的 b-tree 里也有一个类似的 Posting List 的东西,是未经过这样压缩的。
因为这个 Frame of Reference 的编码是有解压缩成本的,所以利用 Skip List做合并操作,除了跳过了遍历的成本,也跳过了解压缩这些压缩过的 block 的过程,从而节省了 CPU。
(2)Bitmap
Bitmap 就是位图,假设 Posting List 为
[1,3,4,7,10]
对应的 Bitmap 就是:
[0,1,0,1,1,0,0,1,0,0,1]
就是把 Posting List 中表示数字的对应下标置为1,每个文档按照 docid 排序对应其中的一个 bit。
Bitmap 本身就有压缩的特点,其用一个 byte 就可以代表 8 个文档,所以 100 万个文档只需要 12.5 万个 byte。但是考虑到文档可能有数十亿之多,在内存里保存 Bitmap 仍然是很奢侈的事情,而且对于个每一个 filter 都要消耗一个 Bitmap,比如 age=18 缓存起来的话是一个 Bitmap,18<=age<25 是另外一个 filter 缓存起来也要一个 Bitmap。所以 Lucene 使用了一种改进版的Bitmap,叫做 Roaring Bitmap。
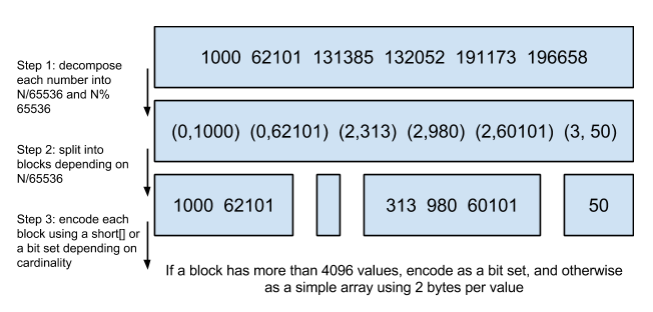
Roaring Bitmap 首先对每个 docid 做取余和取商操作,再根据取商操作的结果进行分块,然后根据每个 block 的数据量使用short 数组(ArrayContainer)或者 Bitmap(BitmapContainer)进行存储,当数据量小于4096时使用 short 数组,大于4096时使用Bitmap。此外对于连续的数据会使用第三种方式存储(RunContainer),例如[11,12,13,14,15]会储存为[11,5]。Roaring Bitmap 的详细实现和原理,可以参考:RoaringBitmap数据结构及原理。

















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









