



 本文介绍了在Windows10环境下,利用Anaconda管理虚拟环境并安装Tensorflow2.3.0进行卫星图像二分类的步骤。首先创建并激活虚拟环境,然后安装Tensorflow及依赖,最后在Jupyter Notebook中验证安装并进行实验准备。
本文介绍了在Windows10环境下,利用Anaconda管理虚拟环境并安装Tensorflow2.3.0进行卫星图像二分类的步骤。首先创建并激活虚拟环境,然后安装Tensorflow及依赖,最后在Jupyter Notebook中验证安装并进行实验准备。
Tensorflow2.0 卫星图像2分类实例
一、win10下管理anaconda的虚拟环境
1、创建虚拟环境,比如环境名是tf230
conda create -n tf230 python=3.6
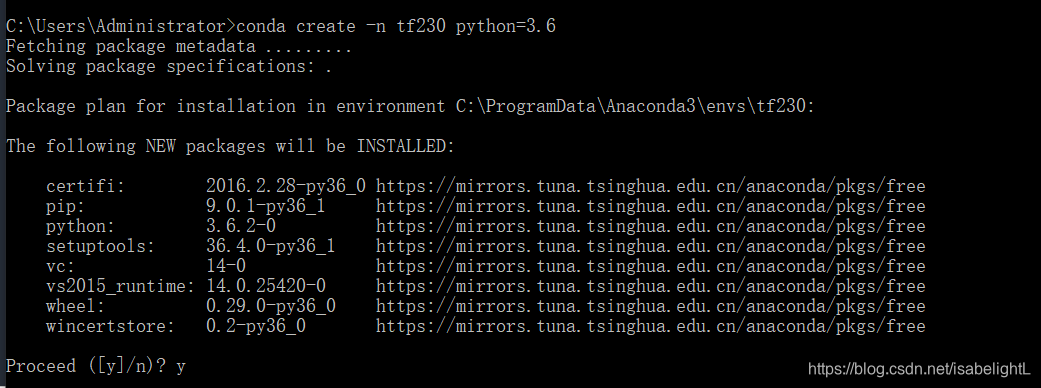
同样的方法创建tf0
2、查看当前虚拟环境,可以看到目前有三个,tf0、tf230是环境名称
命令行:
conda env list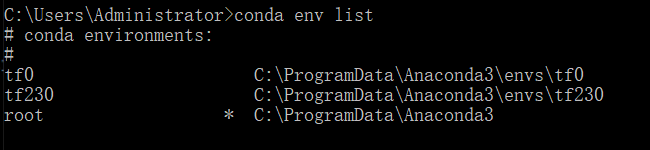
3、进入激活虚拟环境
使用如下命令即可激活创建的虚拟环境
Linux: source activate 虚拟环境名
Windows: activate 虚拟环境名
命令行:
activate tf230
4、退出虚拟环境
使用如下命令即可退出创建的虚拟环境
Linux: source deactivate 虚拟环境名
Windows:deactivate 虚拟环境名
5、删除虚拟环境
conda remove -n tf230 --all二、在创建的tensorflow环境下进入jupyter notebook

在chorme浏览器中自动弹入
jupyter notebook中可创建多个kernel,每个kernel对应封装着运行环境中需要的各类包,如下图中所示,点击new,Notebook下的Python 3,tf0均为kernel名称,我的tf0对应封装tf0虚拟环境中的各种包。

6、安装tensorflow2.3.0虚拟环境
conda create -n tf230 python=3.6
conda env list
activate tf230
conda list
python -m pip install --upgrade pip
python -m pip install tensorflow-cpu==2.3.0 -i https://pypi.douban.com/simple/安装好环境后测试是否安装tensorflow以及tensorflow版本:
python
import tensorflow as tf
print(tf.__version__)如下图,表明成功安装

Ctrl +Z退出python 命令行,此外,如需再安装第三方依赖包,统一使用:
python -m pip install XXXX二、开始实验


















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









