




 本文详细介绍如何在Solr中集成IKAnalyzer进行中文分词,包括必要的文件放置位置及schema.xml配置更新,实现更精准的中文搜索功能。
本文详细介绍如何在Solr中集成IKAnalyzer进行中文分词,包括必要的文件放置位置及schema.xml配置更新,实现更精准的中文搜索功能。
将"IKAnalyzer2012_V5.jar"放入"webapps\solr\WEB-INF\lib"中,
将"ext_stopword.dic"、“IKAnalyzer.cfg.xml”、“mydict.dic”三个文件放入"webapps\solr\WEB-INF\classes"中
配置schema.xml文件:
将
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
加入schema.xml文件中
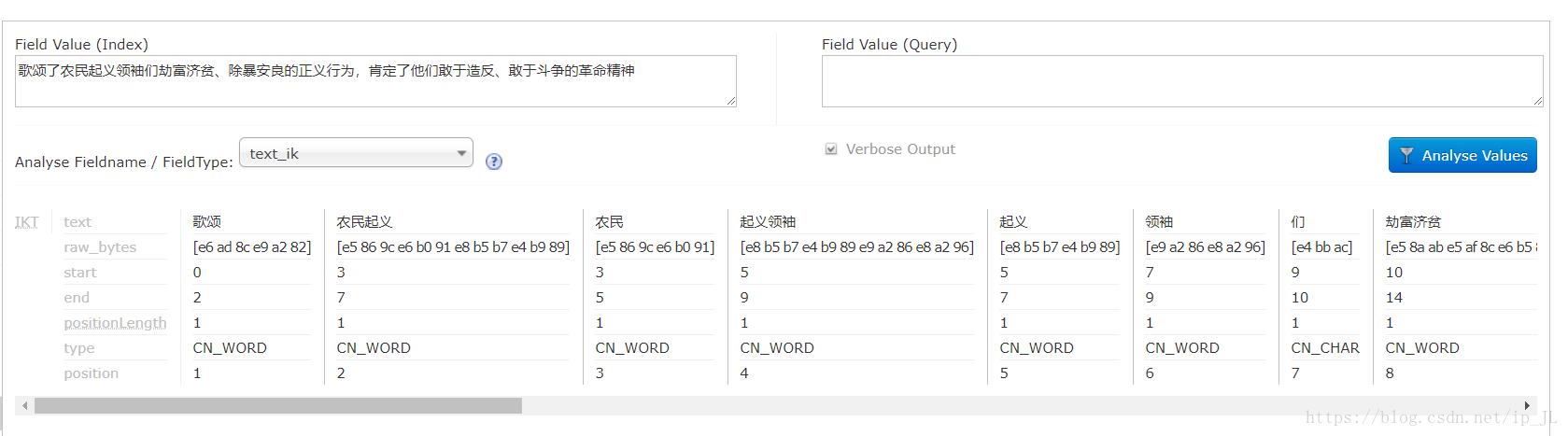
分词结果:

















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









